_ _
_ | | _ _ | | _
_ | | | | | | _ | | | | | | _
|_| |_| | | |_| |_| |_| | | |_| |_|
|_| |_|
____ ___ ____ ____ ___
/ ___| |_ _| / ___| / ___| / _ \
| | | | \___ \ | | | | | |
| |___ | | ___) | | |___ | |_| |
\____| |___| |____/ \____| \___/
☠ morketsmerke ☠
0. Wstęp
Pod koniec wakacji zeszłego roku w pracy (tej nowej, której szukałem przygotowując materiał o RHCSA), kierownik podsłał mi propozycje kursu z certyfikacji Cisco CCNA, która odbywała się na wydziale informatyki jednej z miejscowych uczelni wyższych w kraju. Pomyślałem sobie, że może być ciekawie, ale poźniej trochę ekscytacja opadła po pierwsze, ponieważ sieci nigdy nie były obiektem jakiś moich większych zainteresowań. Dalej nie wiem jako to się stało, że pracuje jako administrator sieci. Więc po dłużyszych działaniach biurokratycznych (kurs w pełni finansowany przez pracodawce - umowa szkoleniowa - lojalka - 5500 brutto albo przez 3 lata zostajesz w firmie), zapisałem się na kurs. Na pierwszych zajęciach nawet nie byłem, zmęczony byłem podróżom z i do stolicy. Dostałem maila od wykładowcy z dostępem do wydziałowego moodle-a oraz platformy netacad.com. Gdzie można było pobrać Packet Tracer, same wykłady prowadzone na wydziale były super, dużo gadania, dyskusji czy luźnych rozkmin, a i gdzieś tam miałem szanse dotknąć sprzetu Po trzecim temacie przyszedł czas tzw. egzaminów cząstkowych - zwykłych testów, które należało zaliczyć. Wyszystko ładnie pięknie, ale z czegoś się trzeba przygotować, nie uważam, że wykładowca nas nie przygotował, ale pierwszy egzamin cząstkowy, już pokazywał że wiedza z wykładów jest ciekawa i na pewno niesie ze sobą wiecej wartości merytorycznej niż to co oferuje firma Cisco. Same materiały zapewnione przez Cisco do nauki dla kursantów są wątłej jakości, tłumaczenie na język polski to ło Matko, ło Jezu. A prezentacje w PowerPoint w języku angielskim, potrafią nie zawierać przykładów, czy zawierać błędy w poleceniach lub opisy mogą niepasować do niektórych terminów (ale nie to, że merytorycznie coś jest nie tak, są po prostu zamienione w tabeli miejscami XD), same egzaminy również zawierają pokrętnie napisane pytania. Na przykład pytania o topologię hybrydową, o której nie ma ani słowa materiałach. Albo brak poprawnej odpowiedzi odnośnie działania zapory pakietów czy zapory stanowej. Także mentalnie trzeba się przygotować do tego, że chociaż by się nie wiadomo jak mocno starać, to i tak nie uzyskać się maksymalnej ilości punktów, albo kolejne ciekawa rzecz, wg. kryteriów oceniania kursu CCNA firmy Cisco, to pracownik, który próbuje złamać hasło innego pracownika jest słabością a nie atakiem. Także wiecie z czym macie doczynienia, dlatego I DON'T GIVE A SHIT czy zdam czy niezdam. Mi zostanie wiedza z kursów i miło spędzony czas na wykładach a pracodawcy wystarczy zaświadczenie o ukończeniu kursu wydane przez uniwersytet. Kiedyś nie było to możliwe, kiedyś trzeba było mieć wszystko zaliczone, aby iść dalej teraz już nie.
Przedstawione tutaj informacje mogą nie tyle mijać się z celem, co być nie kompletne na dzień dzisiejszy. Celem tego kursu najwidoczniej nie jest nauka z zakresu sieci komputerowych (poniekąd), tylko uzyskanie certyfikatów, chcąc certyfikować ludzi na całym świecie trzeba utworzyć pewien standard, a zdający muszą zdawać zgodnie z tym standardem (kluczem).
1. Moduł 1: Wprowadzenie do sieci komputerowych
1.1. Sieci dzisiaj
W dzisiejszym świecie wszystko chce być podłączone do Internetu, czy korzystać z zasobów rozległych sieci. Nie zawsze tak było. Czasy się zmieniają, i to czy podążymy za nimi to już nasza decyzja. Każdy obecnie ma smartfon w kieszeni, u większości osób na ścianie wiszą telewizory, które służą do oglądania stricte kanałów telewizyjny a platform streamingowych. Czy kto kolwiek zadał sobie to pytanie jak to wszystko funkcjonuje chociaż raz. Raczej nie, po co sobie zaprzątać tym głowe. Ten rozdział nie będzie o tym, ponieważ to są materiały przygotowe przez Cisco, więc można go potraktować z przymrużeniem oka.
1.1.1. Komponenty sieciowe
Każdy komputer w sieci nazywany jest hostem lub urządzeniem końcowym. Serwery są komputerami, które dostarczają informacji urządzeniom końcowym, np. serwery pocztowe, serwery WWW czy serwery plików. Klienci to komputery, które wysyłają żądania do serwerów aby otrzymać odpowiednie informacje.
Możliwe jest aby jedno urządzenie było jednocześnie klieten oraz serwerem. Jest to połączenie Peer-to-Peer. Tego typu rozwiązania są dobre do małych sieci.
Po za hostem w sieciach istnieją jeszcze urządzenia pośrednie. Ich zadaniem jest łączyć ze sobą hosty. Do takich urządzeń możemy zaliczyć routery, przełączniki, zapory sprzętowe, czy access pointy.
Do łączenia ze sobą hostów wykorzystuje się media. To media transmisyjne pozwalają na przesył informacji między komponentami sieciowymi. Z pośród mediów transmisyjnych możemy wyróżnić okablowanie miedziane - wykorzystujące impulsy elektryczne, okablowanie światłowodowe - wykorzysujące impulsy świetlne czy powietrze wykorzysujące fale radiowe oraz mikrofalowe.
1.1.2. Powszechne rodzaje sieci
Sieci mają różne rozmiary. Sieci domowe zazwyczaj łączą ze sobą kilka komputerów/urządzeń. Sieci klasy SOHO, mogą wcale nie różnić się od sieci domowych. Mogą być to oddziały firmy, a jedyną róznicą może być dobrej klasy łącze, aby można było bezpiecznie i bez trudu komunikować się z siecią w siedzibie firmy. Średnie i duże firmy mogą łączyć ze sobą setki jak nie tysiące komputerów w tym kilka budynków. Największe sieci to te o zasięgu globalnym, np. Internet.
Sieci można podzielić na podstawie: zasiegu, liczby podłączonych użytkowników, liczby i rodzaju dostępnych usług czy obszaru odpowiedzialności. Istnieją dwa rodzaje najczęściej spotykanych sieci: sieci lokalne (LAN) oraz sieci rozległe (WAN). Sieci lokalne obejmują co najwyżej obszar kilku budynków, gdzie sieci rozległe mogą łączyć ze sobą naprawdę odległe sieci lokalne.
Internet jest zbiorem połączonych ze sobą sieci LAN i WAN. LAN-y razej łączą się przez inne sieci WAN. Intenet nie należy do nikogo, chociaż są grupy takie jak ICANN oraz IETF, które zajmują się przestrzenią adresową czy rozwojem protokółów.
Intranet jest zbiorem LAN-ów oraz WAN-ów w obrębie jednej organizacji oznacza to również, że do tej sieci mają dostęp tylko określeni członkowie organizacji oraz inni, którzy mogą się zautoryzować. Firmy korzystają z ekstranetu aby zapewnić dostęp do wybranych zasobów ściśle określonym użytkownikom.
1.1.3. Połączenia z Internetem
Obecnie zwykli użytkownicy w domach oraz duże organizację mogą łączyć się z internetem w różny sposób. Każdy głównie korzysta ze sposobów na który pozwalają warunki technicze naszej lokalizacji oraz zasób naszego portfela.
Użytkownicy domowi wykorzystują takie łącza jak: kablówka/sieć osiedlowa, DSL, połączenia radiowe oraz połączenia sieci komórkowej.
Organizacje mają o wiele wieksze potrzeby oraz wymagania dotyczące łączności internetowej dlatego też wymagane jest dobre jakości stałe łącze dlatego też odpowiednimi dla nich łączami będzie biznesowa wersja DSL, łącze dzierżawcze oraz sieć miejska, która może skupiać najważniejsze ośrodki badawczo-przemysłowe w danym mieście.
Dziś internet staje się podobnie niezbędnym medium jak prąd czy woda. Obecnie rezygnuje się z telefonów czy telewizji na rzecz własnie internetu. Za pomocą właśnie internetu możemy prowadzić rozmowy telefoniczne czy oglądać telewizje. Takie zajwisko nazywane jest konwergencją sieci. Sieć telewizyjna oraz sieć telefonicza zostały połączone w jedną jak stał się internet.
Zadanie praktyczne - Packet Tracer
Reprezentacja sieci - scenariusz Reprezentacja sieci - zadanie
1.1.4. Niezawodność sieci
Architektura sieciowa odnosi się do technologii wspierających infrastrukturę, która przenosi dane przez sieć. Istnieją cztery podstawowe cechy charakterystyczne, które muszą być podwaliną każdej architektury sieciowej, aby móc spełnić oczekiwania użytkowników. Są nimi: odporność na błędy, skalowalność, QoS czy bezpieczeństwo.
Sieci z odpornością na błędy ograniczają wpływ problemu po przez zmniejszenie dotkniętych nim urządzeń. W sieciach taką tolerancją błędów, może być zapewnienie połączeń nadmiarowych. Oczwywiście wymaga to zastosowania bardziej zaawansowanych technologii.
Skalowalne sieci komputerowe, można w prosty i szybki sposób rozszerzyć bez wpływu na wydajność pozostałych użytkowników. Projektanci sieci projektują ją zgodnie ze standardami oraz powszechnie wykorzystywanymi protokołami, aby zapewnić jej skalowalność.
OoS - ang. Quality of Service jest podstawowym mechanizmem używanym do zapewnienia niezawodności dostarczenia danych do wszystkich użytkowników. Za pomocą zastosowanej polityki QoS routery mogą regulować przesył ruchu danych czy przesyłanie głosu.
Są dwa główne rodzaje bezepieczeństwa sieci jaki trzeba zapewnić: bezpieczeństwo infrastruktury sieciowej oraz bezpieczeństwo informacji. Na bezpiczeństwo sieci składa się fizyczne zabezpieczenie urządzeń sieciowych oraz ochronę przed nieuprawnionym dostępem do nich. Natomiast bezpieczeństwo informacji polega na zabepieczeniu informacji lub danych przesyłanych przez sieć. Są trzy podstawowe cele bezpieczeństwa sieci: poufność - tylko określeni odbiorcy mogą odczytać przesyłane dane, integralność - zapewnienie, że dane nie zostały zmienione podczas transmisji oraz dostępność - zapewnienie o niezawodnym dostępie do danych przez autoryzowanych użytkowników.
1.1.5. Trendy sieciowe
Role sieci wymagają ciągłych zmian, ciągłego dostosowania aby nądąrzyć za ciągle pojawiąjcymi się na rynku urządzeniami. Możemy wyróżnić kilka nowych trendów, majacych wpływ na organizację:
- Bring Your Own Device (BYOD)
- Współpraca online
- Komunikacja wideo
- Przetwarzanie chmurowe
Bring Your Own Device (BYOD), ang. przynieś swoje urządzenie, pozwala użytkownikom używać ich własnych urządzenie co daje im więcej możliwości oraz większą elastyczność. BYOD pozwala użytkownikom końcowym na używanie ich własnych (ulubionych) narzędzi. BYOD oznacza dowolne urządzenie w posiadaniu rożnych osób, używane gdzie kolwiek.
Współpraca online pozwala wspólną pracę nad wieloma projektami z różnymi ludźmi na odległość z pośrednictwem sieci. Do tego celu często wykorzystywan są takie aplikacje jak MS Teams czy Cisco Webex. Takie podjeście swietnie odnajduje się biznesie czy edukacji.
Połączenia wideo mogą być wykonywane przez kogo kolwiek gdzie kolwiek jest są one poteżnym narzędziem do komunikacji z innymi. Konferencje wideo stały się wręcz wymogiem do efektywnej współpracy.
Przetwarzanie chmurowe pozwala na przechowywanie osobistych danych na na serwerach w internecie. Możliwe jest również dostarczanie zasobów komputerów (np. w celach wirtualizacji) jak i samych aplikacji. Przetwarzanie chmurowe jest obsługiwane najczęsciej przez ogromne korporacje takie jak Amazon czy Google. Mozemy wyróżnić cztery rodzaje chmur:
- Publiczne, z których każdy może korzystać, za darmo lub opłatą według zużycia zasobów.
- Prywatne, do wykorzystania przez spcyficzne organizacje takie jak np. rząd.
- Hybrydowe, łączące ze soba funkcję na przykład chmur prywatnych jak i tych niestandardowych.
- Niestandardowe, tworzona dla specjalnych potrzeb organizacji. Może być prywatna i np. wykorzystywać zasoby chmury publicznej.
1.1.6. Bezpieczeństwo sieci
Bezpieczeństwo jest integralną częścią sieci, bez znaczenia na jej wielkość. Musi ono zostać zaimplentowane w taki sposób aby nie wpłyneło za bardzo na wymagania dotyczące łączności. Zabezpieczenie sieci angażuje wiele protokołów, technologii, urządzeń, narzędzi czy technik w celu zabepieczenia danych oraz złagodzenia zagrożeń, które mogą pochodzić jak najbardziej z zewnątrz ale ich źródło może być równie dobrze z wewnątrz organizacji.
Z pośród zagrożeń zewnętrznych możemy wymień takie jak:
- Wirusy, robaki czy konie trojańskie
- Oprogramowanie typu spyware czy adware
- Ataki typu 0-day
- Ataki podmiotu zagrożenia
- Ataki odmowy usługi
- Ataki kradzieży oraz fałszowania danych
- Kradzież tożsamości
Natomiast zagrożenia wewnętrzne to między innymi:
- Zgubione lub ukradzone urządzenia
- Przypadkowe nadużycia przez pracowników
- Złośliwy pracownik
Zabepieczenia powinny obejmować wiele warstw, składać się z większej ilości rozwiązań. Dla małej sieci domowej, wystarczy dobrej jakości program antywirusowy zainstalowany na urządzeniach końcowych oraz firewall blokujący nieautoryzowanych dostęp do sieci.
Przy czym dla większych sieci stosuje się nieco bardziej wyrafinowane rozwiązania takie jak: dedykowany firewall, listy kontroli dostępu (ACL), systemy zapobiegania włamaniom (IPS), wirtualne sieci prywatne (VPN). Zrozumienie bezpieczeństa sieci rozpoczyna się od dobrego zrozumienie infrastruktury sieci, w tym przełączników oraz routerów.
Podsumowanie
Tym rozdziałem rozpoczynamy kurs. W ramach tego rodziału poznaliśmy współczene trendy sieciowe oraz to jak w obecnych czas istotne jest połączenie z Intenetem za pośrednictwem nawet najmniejszej sieci.
1.2. Podstawowa konfiguracja przełącznika oraz urządzenia końcowego
W tym rodzdziale nie bedziemy skupiać się na konfiguracji urządzenia końcowego, jakby tytuł sugerował. To wydaje mi się, że każdy potrafi, prawda? Skupimy się na zapoznaniu z system IOS, będącym oprogramowaniem urządzeń firmy Cisco oraz jak wyglądają takie podstawowe czynności, które należy wykonać na tym urządzeniu przed już bardziej ukierunkowaną na konkretne urządzenie konfiguracją.
1.2.1. Dostęp do systemu Cisco IOS
Słowem wstępu systemy komputerowe składają się z sprzętu oraz oprogramowania. Aby uruchamiać specyficzne oprogramowanie potrzebujemy platformy programowej zapewniającej wszystkie niezbędne składniki do uruchomienia wybranych programów. Tym jest właśnie system operacyjny. Systemy operacyjne składają się z jądra, przestrzeni użytkownika oraz powłoki. Powłoka z kolei jest to interfejs pozwalający na prowadzenie interakcji z systemem operacyjnym a co za tym idzie z naszym sprzętem komputerowym. Powłoką może być interfejs graficzny lub program dający dostęp do wiersza polecenia oraz interpretujący co zostało w nim zapisane. Systemami składającymi się z jadra oraz powłoki są najczęściej systemy wbudowane takie jak Cisco IOS.
Dostęp do IOS możemy uzyskać na 3 sposoby: połaczeniem konsolowym za pomocą kabli szeregowych połączanych do portu szeregowego komputera oraz do portu konsolowego urządzenia. Jeśli urządzenie jest przywrócone do ustawień fabrycznych to raczej może nie być innej możliwości. Połączenia szeregowe w przypadku urządzeń Cisco mogą być zestawione przy użyciu istniejącego okablowania sieciowego. Innym sposobem jest wykorzystanie połączeń przy użyciu protokołów SSH oraz Telnet. Przyczym warto mieć na uwadzę, że Telnet nie jest bezpiecznym protokołem, ponieważ przesyła on informacje za pomocą jawnego tekstu. Programów do połączenia się z urządzeniami Cisco jest kilka, najpopularniejszym z nich jest chyba program PuTTY, zapewnia on wspracie dla wszystkich wymienionych rodzajów połączeń.
1.2.2. Nawigacja po systemie IOS
Po połączeniu z naszym urządzeniem do dyspozycji będziemy mieć dwa tryby wykonywania poleceń tryb użytkownika EXEC znak zachęty może wyglądać wówczas tak:
Router> Switch>
Tryb ten jest domyślnym uruchamiany zaraz po podłączeniu się do urządzenia o ile urządzenie nie wymaga logowania. Tryb ten zapewnia ograniczoną liczbę poleceń i pozwala na wydanie kilku poleceń monitorujących.
Innym trybem jest tryb uprzywilejowany EXEC, jest coś w rodzaju administratora urządzenia, ten tryb pozwala na zmianę trybów konfiguracji, w tym trybie znaki zachęty mogą wyglądać w ten sposób:
Router# Switch#
W urządzeniach Cisco, mamy dostępny tryb konfiguracji globalnej, wykorzystywany do konfiguracji parametrów urządzenia. Ten tryb posiada dwa podtryby: tryb konfiguracji linii, za jego pomocą konfigurujemy dostęp do urządzenia. Drugin podtrybem jest tryb konfiguracji interfejsu.
Po podłączeniu się do urządzenia, automatycznie przechodzimy do trybu
użytkownika EXEC, chcąc przejść do trybu uprzywilejowanego wydajemy
polecenie enable. W tym trybie możemy
już skonfigurować kilka opcji, jeśli jednak interesuje nas konfiguracja
dostępu do urządzenia (a powinna), to żeby przjeść do trybu
konfiguracji globalnej wydajemy polecenie
configure terminal, z tego trybu
możemy powrócić wydając polecenie
exit. Przjście do konfiguracji dostępu
wymaga polecenia line oraz podania
trybu dostępu, który chcemy skonfigurować. Dla połączenia szeregowego
podajemy console 0 dla połączeń
zdalnych podajemy vty, czyli konsole
wirtualną, następnie ilość jednoczesnych połączeń dla 5 podajemy
0 4.
Poszczególne tryby możemy opuścić za pomocą polecenia
exit, wówczas powrócimy do trybu
poprzedniego. Jeśli chcemy zakończyć konfigurację i powrócić do
trybu uprzywilejowanego EXEC wydajemy polecenie
end. Warto zwrócic uwagę na to, że
wraz ze zmienymi trybami zmieniają się znaki zachęty, więc wiemy
gdzie jesteśmy.
Switch>enable Switch#configure terminal Enter configuration commands, one per line. End with CNTL/Z. Switch(config)#line console 0 Switch(config-line)#exit Switch(config)#int vlan1 Switch(config-if)#end Switch# %SYS-5-CONFIG_I: Configured from console by console Switch#
1.2.3. Struktura poleceń
Polecenia składają się z samego polecenia, często identyfikującego program, który będzie uruchamiany. Następnie występują słowa kluczowe oraz argumenty, często będące opcjami oraz modyfikatorami działania głównego polecenia (programu).
IOS posiada funkcje pomocy wywoływaną za pomocą znaku zapytania (?). Za jego pomocą możemy dostępne w danym trybie polecenia, lub sprawdzić dostępne argumenty dla podanych polecen.
Podczas wpisywanie poleceń możemy posłużyć się skrótami poleceń, podając tyle znaków, aby powłoka IOS mogła je jednoznacznie zidentyfikować.
Switch#con % Ambiguous command: "con" Switch#con? configure connect Switch#conf t Enter configuration commands, one per line. End with CNTL/Z. Switch(config)#
IOS wprowadza również kilka skrótów klawiszowych. Dobrze odnajdą się
tutaj użytkownicy powłoki BASH, gdyż IOS jest kompatybilny z
GNU Readline. Pod Tab-em mamy dopełnianie poleceń. W przypadku
stronicowania ("--More--") mamy do
dyspozycji klawisz Enter, który pozwoli na wyświetlenie
kolejnej linii stronicowanego tekstu lub Spacją kolejną
stronę. Każde naciśniecie innego klawisza spowoduje zakończenie
wyświetlania i przejście do trybu EXEC. Zakończenie wprowadzania
konfiguracji możemy dokonąć albo za pomocą wyżej wymienionych poleceń,
albo za pomocą skrótów takich Ctrl+z lub Ctrl+c. Do przerwania
polecenia ping, traceroute czy odwzorowania nazw domenowych należy
wykorzystać kombinację klawiszy Ctrl+Shift+6
Zadanie praktyczne - Packet Tracer
Nawigacja w IOS - scenariusz Nawigacja w IOS - zadanie
Laboratorium
Nawigacja w IOS za pomocą Tera Term przez konsolę
1.2.4. Podstawowa konfiguracja urządzeń
Jedno z podstawowych czynności jakie należy wykonać dokonując
pierwszej konfiguracji urządzenia z system IOS jest zmiana jego nazwy.
Dokonujemy tego za pomocą polecenia
hostname, podają wybraną nazwę jako
argument polecenia. Nazwy muszą zaczynać się od litery, nie zawierać
spacji, muszą zakończyć się literą lub cyfrą, zawierać tylko litery,
cyfry lub myślniki. Nazwa nie może przekraczać 64 znaków. Aby
przywrócić domyślną nazwę należy użyć polecenia:
no hostname.
Następną czynnością jest zabezpieczenie dostępu do urządzenia, przy
użyciu hasła. Te czynności musimy wykonać w trybie konfiguracji
linii za równo dla konsoli szeregowej jak i konsoli wirtualnych
wykorzystywanych przez połączenia SSH oraz Telnet. W trybie
konfiguracji globalnej
(configure terminal), przechodzimy
do konfiguracji linii połączenia szergowego
(line console 0), teraz możemy
ustawić hasło, pamiętając o zasadach bezpiecznych haseł. Ustawiamy
hasło (password) oraz włączamy
dostęp do trybu EXEC za pomocą polecenia
login. Tę samą czynność powtarzamy dla
konsoli wirtualnych, przyczym warto pamiętać, że IOS pozwala na
16 jednoczesnych połączeń więc do przejścia w tryb konfiguracji linii
wykorzystujemy następujące polecenie
line vty 0 15
Switch#configure terminal Enter configuration commands, one per line. End with CNTL/Z. Switch(config)#line console 0 Switch(config-line)#password cisco Switch(config-line)#login Switch(config-line)#exit Switch(config)#line vty 0 15 Switch(config-line)#password cisco Switch(config-line)#login Switch(config-line)#exit
Hasła, które widnieją na powyższym przykładnie do najtrudniejszych
nie należą nie mniej jednak co z tego jeśli hasło będzie trudne. Jeśli
są one przechowywane w postaci jawnego tekstu. Aby się o tym przekonać,
możemy wyświetlić obecną konfigurację za pomocą polecenia
show running-config, wydanego w
uprzywilejowanym trybie EXEC.
... line con 0 password cisco login ! line vty 0 4 password cisco login line vty 5 15 password cisco login ...
Hasła te możemy zaszyfrować wydając w trybie konfiguracji globalnej
polecenie
service password-encryption.
Switch(config)#service password-enc Switch(config)#service password-encryption Switch(config)#exit Switch# %SYS-5-CONFIG_I: Configured from console by console Switch#show running-config ... ! line con 0 password 7 0822455D0A16 login ! line vty 0 4 password 7 0822455D0A16 login line vty 5 15 password 7 0822455D0A16 login ...
Kiedy dostęp do trybu użytkownika jest chroniony hasłem, możemy zabezpieczyć tryb uprzywilejowany wydając odpowiednie polecenie w trybie konfiguracji globalnej.
Switch(config)#enable secret class Switch(config)#exit
Przy czym class jest własnie tym
ustawionym hasłem. Ostatnią czynnością będzie ustawienie informacji
na temat tego, że jeśli ktoś się podłączy do naszego urządzenia, to że
nie życzymy sobie żadnego nieupoważnionego dostępu. Do tego celu
wykorzystamy polecenie
banner motd # wiadomość #, polecenie
to wydajemy w trybie konfiguracji globalnej. Komunikat musi znajdować
się między krzyżykami (#) i nie musi być to włącznie
jedna linia (stąd znak początku i końca wiadamości).
Switch(config)#banner motd # Osobom nieupowaznionym, wstep wzbroniony! # Switch(config)#exit
1.2.5. Zapisywanie konfiguracji
Już we wcześniejszych przykładach wyświetlaliśmy obecnie działającą konfigurację. Ta konfiguracja rezyduje w pamieci RAM, która jest pamięcią ulotną. Jeśli urządzenia straci zasilanie i ono powróci to utracimy całą tą konfigurację, dlatego też urządzenia Cisco mają pamięć NVRAM, która jest nie ulotna. Ale to w naszej gestii jest aby tę konfigurację zapisać, chyba że dojdzie do sytuacji, że nie będziemy chcieli jej zapisać. Nie mniej jednak, aby zapisać konfirgurację w NVRAM należy w trybie uprzywilejowanym EXEC wydać następujące polecenie:
Switch#copy running-config startup-config Destination filename [startup-config]? Building configuration... [OK] Switch#
Jeśli podejrzewamy, że obecna konfiguracja jest wadliwa możemy wrócić do konfiguracji startowej z NVRAM, wydając w trybie uprzywilejowanym EXEC polecenie:
Switch#reload Proceed with reload? [confirm]
Przywrócenie urządzenia do ustawień fabrycznych dokonujemy za pomocą dwóch poleceń wydanych w trybie uprzywilejowanym EXEC.
Switch#erase startup-config Erasing the nvram filesystem will remove all configuration files! Continue? [confirm] [OK] Erase of nvram: complete %SYS-7-NV_BLOCK_INIT: Initialized the geometry of nvram Switch#reload Proceed with reload? [confirm]
Korzystając z programu PuTTY możemy rejestrować naszą sesję połączenia z urządzeniem do pliku. W ten sposób możemy zrzucić sobie konfigurację do pliku tekstowego. Ustawienia session/logging.
1.2.6. Konfiguracja adresacji IP
Z racji tego, że pomineliśmy konfigurację hostów z systemem Windows 10.
Możemy przejść od razu do systemu IOS. W przypadku przełączników
występuje coś takiego jak SVI - wirtualny interfejs
przełącznika i to jemu nadajemy adres w przypadku tego urządzenia.
W trybie konfiguracji globalnej przechodzimy do interfejsu vlan1
następnie za pomocą polecenia
ip address 192.168.1.2 255.255.255.0
nadajemy mu adres IP, następnie musimy aktywować ten interfejs za
pomocą polecenia no shutdown. Poniżej
znajduje się przykład, pokazujący te czynności.
Switch(config)#int vlan1 Switch(config-if)#ip addr 192.168.1.2 255.255.255.0 Switch(config-if)#no shutdown Switch(config-if)# %LINK-5-CHANGED: Interface Vlan1, changed state to up Switch(config-if)# Switch(config-if)#exit
Zadanie praktyczne - Packet Tracer
Konfiguracja ustawień początkowych przełączników - scenariusz Konfiguracja ustawień początkowych przełączników - zadanie Realizacja podstawowej łączności - scenariusz Realizacja podstawowej łączności - zadanie
Podsumowanie
W tym rozdziale zapoznaliśmy z system IOS firmy Cisco, poznaliśmy składnie poleceń, funkcję pomocy oraz przydatne skróty klawiszowe. Na koniec skonfigurowaliśmy przełącznik w podstawowym stopniu.
Zadanie praktyczne - Packet Tracer
Podstawowa konfiguracja przełącznika i urządzenia końcowego - scenariusz Podstawowa konfiguracja przełącznika i urządzenia końcowego - zadanie
Laboratorium
Podstawowa konfiguracja przełącznika i urządzenia końcowego
1.3. Protokoły i modele
Za pomocą protokół oraz modeli możemy wyjaśnić w jaki sposób urządzenia podłączone do sieci mogą uzyskać dostęp do jej zasobów.
1.3.1. Zasady
Sieci komputerowe mogą być rożne pod względem wielkości oraz złożoności. Nie jest wystarczające połączenie między nimi, potrzebne jest również ustalenie wspólnych metod komunikacji. W każdej komunikacji istnieją trzy elementy: źródło (nadawca), cel (odbiorca) oraz kanał (medium), który umożliwia komunikację między jej składnikami.
Większość komunikacji zarządzana jest za pomocą protokołów. Protokoły są zestawem zasad, które należy przestrzegać, aby komunikacja mogła dojść do skutku i te zasady mogą być rożne w zależności od protokołu, a strony komunikacji muszą je zaakceptować.
Protokoły chcąc brać udział w komunikacji sieciowej muszą spełnić takie wymagania jak: kodowanie wiadomości, jej formatowanie oraz enkapsulacja, wielkość wiadomości czy możliwości jej dostarczenia są istotnym czynnikiem tutaj może być to rozłożenie etapów komunikacji w czasie.
Kodowanie jest proces zmiany formy wiadomości do celów transmisji. Natomiast dekodowanie jest procesem odwrotnym do kodowania. Wiadomość powraca do pierwotnej formy w celu interpretacji.
Wysyłana wiadomość musi mieć odpowiednią formę lub strukture. Zależy to od medium przez jakie jest przesyłana. Wiadomości przesyłane przez sieci muszą zostać skonwertowane do postaci bitów. Bity te są poźniej zamieniane na impulsy świetlne, dźwięk czy impulsy elektryczne. Odbiorca musi ten proces odwrócić, aby móc odczytać wiadomość.
Jak wspomniano istotny w komunikacji może być czas, w tym takie zagadnienia jak kontrola przepływu, która zarządza prędkością transmisji. Definiuje jak dużo informacji można przesłać i z jaką prędkością może ona zostać dostarczona. Inną wartoscią jest czas odpowiedzi, który określa ile jedna ze stron może czekać na odpowiedź od drugiej. Kolejnym czynnikiem definiującym poniekąd czas jest dostęp do łącza, w którym określane jest kiedy można wysłać wiadomość. Zapobiega to tworzeniu kolizji - sytuacji kiedy dwóch nadawców zaczyna nadawać na tym samym kanale w tym samym czasie. Niektóre algorytmy dostępu do łącza wykrywają kolizje i organizują retransmisje uszkodzonych danych inne posiadają mechnizmy pozwalające na ich uniknięcie.
Istnieje kilka sposobów na dostarczenie wiadomości. Najprostszą z nich unikast, mamy jednego nadawcę oraz jednego odbiorcę. W inny przypadku wiadomość może trafić do wielu odbiorców będących częścią tej samej grupy - multikast. Ostatni rodzaj dostarczenia to wiadomość skierowana do wszystkich odbiorców - broadkast.
1.3.2. Protokoły
Protokoły sieciowe składają ze zbioru reguł. Mogą one określać zastosowania programowe oraz sprzetowe, jak i oba. Każdy protokół posiada własne funkcje, format czy zasady.
Urządzenia wykorzystują uzgodnione protokoły. Mogą mieć one takie funkcje jak: adresacja - pozwalająca na identyfikację nadawcy i odbiorcy; niezawodność - gwarancje dostarczenia danych; kontrolę przepływu - określającą optymalną prędkość dla przesyłanych danych; sekwencyjność - unikalne oznaczanie danych podczas transmisji; detekcję błędów - określenie czy jakieś dane nie zostały uszkodzone podczas transmisji oraz interfejs aplikacji - pozwalający na komunikację aplikacji z pośrednictwem tego protokołu.
W komunikacji sieciowej wymagane jest stosowanie kilku protokołów, Każdy znich posiada swój format danych. Takimi protokłami są Ethernet, Internet Protocol (IP), Transmission Control Protocol (TCP) czy Hypertext Transfer Protocol (HTTP)
1.3.3. Zestawy protokołów
Protokoły muszą być w stanie współpracować z innymi protokołami. Zestawy protokołów to grupa powiązanych ze sobą protokołów niezbędnych do komunikacji lub zbiór reguł współpracujących ze sobą w celu rozwiązania problemów. Protokoły są często postrzegane w kategoriach warstw: warstw wyższych czy niższych, które mają za zadanie przenieść dane oraz dostarczyć usługi warstwom wyższym.
Obecnie mamy kilka różnych zestawów protokołów. Najczęściej spotykany, zarzązany przez IETF - Internet Protocol Suite lub TCP/IP, Open Systems Interconnection protocols, rozwijany przez organizacje takie jak ISO wraz z ITU. Pozostałe takie Apple Talk czy Novell NetWare nie są już rozwijane ani stosowane w szerszej skali.
Protokoły TCP/IP operują na warstwie aplkacji, transportu, czy internetu. Protokołami dostępu do łącza, a zarazem najpopularniejszymi dla sieci LAN są Ethernet oraz WLAN (sieć bezprzewodowa).
Protokół TCP/IP jest stosem protokołów wykorzystywanym przez sieć Internet i zawierającą wiele protokołów. Jest to otwarty ogólnodostępny standard, który może zostać użyty przez dowolnego producenta. Jest on oparty na standardach przyjętych przez przedsiębiorstwa sieciowe oraz aktualizowany przez instytucje standaryzujące w celu zapewniania interoperatywności.
Proces komunikacji w stosie TCP/IP wygląda następująco, że przeglądarka internetowa enkapsuluje stronę (przy użyciu TCP/IP) i wysyła ją do klienta. Klient dekapsuluje przy użyciu stosu TCP/IP i przekazuje do przeglądarki.
3.4. Organizacje standaryzujące
Otwarte standardy zapewniają interoperacyjność, konkurencyjność i innowacyjność. Organizacje standaryzujące są niepowiązane z żadnym z producentów sprzętu, organizacjami non-profit. Powołane aby rozwijać koncepcje otwartych standardów.
Wśród organizacji pracujących nad standardami internetowymi możemy wyróżnić dwie podstawowe: Internet Engineering Task Force (IETF) czy Internet Engieering Research Task Force (IRTF) - zajmują się one rozwojem oraz utrzymaniem wielu kluczowych technologii internetowych w tym stosu TCP/IP. Innymi organizacjami zajmującymi się Internet jest Internet Corporation for Assigned Names and Numbers (ICANN) oraz Internet Assigned Numbers Authority (IANA), te organizacje zajmują się zarądzaniem różnego rodzaju numeracją, jak np. adresy IP, numery portów czy nazwami domenowymi.
Innym rodzajemy standardów są standardy elektroniczne czy komunikacjyne, Do najpopularniejszych należą:
- Institute of Electrical and Electronics Engineers (IEEE) - powołane w celach utworzenia standardów dla sektorta energetycznego, ochrony zdrowia, telekomunikacji oraz sieci komputerowych.
- Electronic Industries Alliance (EIA) - opracowuje standardy dla okablowania elektrycznego, złączy czy standardu stojaków oraz szaf 19-calowych, w których montowane są urządzenia sieciowe oraz serwery.
- Telecomunications Industry Association (TIA) - Rozwija standardy w osprzęcie radiowym, stacjach bazowych telefonii komórkowej, urządzenia typu VoIP, komunikacji satelitarnej oraz wielu innych.
- International Telecommunications Union-Telecommunication Standardization Sector (ITU-T) - określa standardy np. dla kompresji wideo, protokołu Telewizji Internetowej (IPTV) czy łączy szerokopasmowych takich jak DSL.
Laboratorium
1.3.5. Model odniesienia
Przez złożoność koncepcji wyjaśnienie oraz zrozumienie jak działa sieci, może być trudne. W tym celu posługujemy się modelem odniesienia, modelem warstwowym. Do tego celu można wykorzystać model ISO/OSI oraz model TCP/IP. Generalnie posługujemy się modelem TCP/IP, jeśli nie musimy zagłębić się zasady działania aplikacji. Warstwa SSL dla HTTP to ta sama warstwa modelu TCP/IP ale inna w modelu ISO/OSI. W nomenklatrzue rozwiązań firmy Cisco również używa się modelu ISO/OSI.
Model odniesienia pomaga w projektowaniu protokołów, umożliwia współpracę producentów urządzeń, chroni przed wpływem technologii z innych warstw na siebie, dostarcza wspólnego języka do opisu funkcji oraz możliwości sieci.
Model referencyjny OSI prezentuje się następująco:
- Warstwa aplikacji - Zawiera protokoły wykorzystywane do komunikacji między procesami.
- Warstwa prezentacji - Dostarcza ogólnej prezentacji danych przesyłanych między aplikacjami.
- Warstwa sesji - dostarcza usług dla warstwy prezentacji i zarządza wymianą danych.
- Warstwa transportowa - określa usługi dla segmentacji, transferu oraz ponownego złożenia danych dla poszczególnych połączeń.
- Warstwa sieciowa - dostarcza usług w celu wymiany indywidualnych fragmentów danych poprzez sieć.
- Warstwa łącza danych - określa metody wymiany ramek danych przez popularne media.
- Warstwa fizyczna - określa znaczenie dla aktywacji, zarządzania i deaktywacji połączeń fizycznych.
Natomiast model TCP/IP jest podobobny. Nie skupia on sie za bardzo na protokołach i aplikacjach oraz na warstwie fizycznej. Dlatego też z 7 warstw zostały 4. Warstwy sesji, prezentacji oraz aplikacji zostały połączone w jedną warstwę aplikacji, natomiast warstwa fizyczna i łącza danych zostały połączone w jedną warstwę dostępu do łącza.
Zadanie praktyczne - Packet Tracer
Badanie modeli TCP/IP i OSI w działaniu - scenariusz Badanie modeli TCP/IP i OSI w działaniu - zadanie
1.3.6. Enkapsulacja danych
Segmentacja jest procesem rozbijania wiadmości na mniejsze jednostki. Multipleksacja jest procesem wysyłania wielu segmentów jednocześnie. Segmentacja ma dwie podstawowe zalety: zwiększa prędkość oraz zwiększa wydajność.
Sekwencyjnosć wiadomości jest procesem numeracji segmentów, zapewnia to możliwość dostarczenia wiadomości w takiej samej kolejności jak została wysłana.
Enkapsulacja to proces, w którym protokoły dodają swoje dane, na każdym etapie tego procesu, PDU - jednostka danych protokołu (ang. Protocol Data Unit) ma inną nazwę aby odwzorować jej funkcje. Nie ma jednej ogólnej nazwy dla PDU, chociaż stosuje w mowie potocznej określenie pakiet. Są one nazywane powiązane protokołami stosu TCP/IP, opuszczając stos PDU nazywane są kolejno:
- Dane (strumień danych)
- Segment
- Pakiet
- Ramka
- Bity
Enkapsulacja jest procesem, który jest przeprowadzany od z góry na dół. Górne poziomy przekazuje dane/PDU w dół do dolnych warstw, które obudowywują dane z góry w dane kontrolne PDU obecnej warstwy, aż do formy strumienia bitów.
Deenkapsulacja jest procesem odwrotnym, tutaj strumień bitów zamieniany jest do postacji ramki, kiedy dane wędrują w górę poszczególne warstwy dokonują przetwarzania swoich danych kontrolnych, a następnie usuwają swoje dane kontrolne i przekazują dane wyżej, aż do aplikacji.
1.3.7. Dostęp do danych
Obie warstwy: łacza danych oraz warstwa sieciowa, wykorzystują adresy aby dostaczyć dane od źródła do celu. Warstwa sieciowa wykorzystuje adresy IP do adresacji pakietów, w przypadku warstwy łącza danych wykorzystywane są adresy fizyczne kart sieciowych (adresy MAC).
Pakiet IP zawiera dwa adresy IP, adres źródłowy określający twórcę wiadomości oraz adres docelowy określający odbiorcę.
Adres protokół warstwy sieciowej dzielą się na dwie części: część sieciową (dla IPv4) lub prefiks (dla IPv6) oraz cześć hosta (dla IPv4) lub identyfikator interfejsu (IPv6). Urządzenia w tej samej sieci, mają takie same części sieciowe lub prefiksy.
Urządzenia w tej samej sieci Ethernet, do adresacji ramek wykorzystają już właściwe dla adresy MAC przypisane do fizycznych kart sieciowych. Jeśli odbiorca znajduje się w innej sieci, to wówczas adres MAC nadawcy ulegnie zmianie, na adres MAC routera, tak aby odbiorca wiedział gdzie ma odesłać odpowiedź.
Ciekawie jest przypadku warstwy sieciowej, to jeśli odbiorca pakietu nie należy do naszej sieci wówczas pakiet IP zostanie zaadresowany docelowym adresm IP odbiorcy, ale ramka zostanie zaadresowana adresem bramy domyślnej - routera, który zapewnia nam dostęp do innej sieci. Każdy z hostów zawiera informacje jak ma adresować pakiety IP i przez jakie interfejsy (karty sieciowe) je wysłać. Brama domyślna jest hostem do którego należy przesłać pakiety, kiedy host nie wie gdzie ma je przesłać. Jest to trasa ostatniej szansy. Router przekazując ten pakiet już do sieci docelowej lub na swoją bramę przepakuje go w nową ramkę, opatrzoną w adresy fizyczne nadawcy (swojego interfejsu WAN) oraz odbiorcy. Ten pakiet może przejść kilka takich etapów zanim trafi do odbiorcy. Podobnie jest z odpowiedzią.
Laboratorium
Instalacja programu Wireshark Wykorzystanie programu Wireshark do badania ruchu sieciowego
Podsumowanie
W tym rozdziale poznalismy w jaki sposób przebiega komunikacja i jakie warunki trzeba spełnić. Poznaliśmy protokoły, ich stosy oraz organizacje standaryzujące. Dowiedzielismy czym są modele odniesienia i doczego służą. Zapoznalismy się z enkapsulacją danych oraz jak faktycznie wygląda dostęp do danych.
Egzamin cząstkowy
Po omówieniu 3 rozdziału spotkamy się z przedsmakiem egzaminu końcowego mianowicie egzaminem cząstkowym obejmującym od 2 do 3 tematów. W większości przypadków będą to trzy tematy. Egzamin składa się z pytań jednokrotnego oraz 2 lub 3-krotnego wyboru oraz pytań polegających na przypasowaniu definicji do pojęcia - oczywiście jest to pojęcie względne, ponieważ nie zawsze definicje oraz pojęcia faktycznie nimi będą. Taki przypadek możemy spotkać na podstawie przypisania opisu do konkretnego adresu. Egzaminy cząstkowe łączą test teoretyczny z zadaniem praktycznym do wykonania w Packet Tracerze. Na całość mamy 60 minut. Liczba pytań wacha się od 30 do 35 pytań.
Wszystkie egzaminy zdajemy na platformie netacad.com>. Mamy możliwość jednego podejścia oraz jednej poprawki przy czym poprawkę musi umożliwić nam prowadzący kurs. Do wyboru są dwa języki: ojczysty oraz język angielski. Z językiem ojczystym jak jest każdy wie. Przy czym warto dodać, że końcowy egzamin praktyczny jest wyłącznie w języku angielskim.
1.4. Warstwa fizyczna
Warstwa fizyczna skupia w sobie wiele technologii związanych z fizycznym podłączeniem hostów oraz standardów tych połączeń.
1.4.1. Przeznaczenie wartstwy sieciowej
Aby w ogóle komunikacja sieciowa mogła zajść potrzebne są połączenia fizyczne między jej stronami. W zależości od konfiguracji sieci połączenia mogą być przewodowe lub bezprzewodowe. Podłączenie do sieci uzyskujemy za pomocą urządzeń kart sieciowych wbudowanych w nasze urządzenia, oczywiście nie wszystkiego rodzaju połaczenia fizyczne mają taka samą wydajność.
Warstwa fizyczna znajmuje się transportem bitów przez media sieciowe, odbiera ona ramkę z warstwy łącza danych koduje ją za pomocą serii sygnałów, które są następnie transmitowane za pomocą lokalnego medium. Warstwa fizyczna kodując i dekodując ramkę, kończy proces enkapsulacji lub rozpoczyna proces deenkapsulacji.
1.4.2. Charakterystyka warstwy fizycznej
Standardy zastosowane w sprzęcie sieciowym są zarządzane przez wiele organizacji takich jak: ISO, EIA/TIA, ITU-T, ANSI, IEEE.
Standardy warstwy fizycznej operują na dwóch płaszczyznach: kompnentów fizycznych, kodowania oraz sygnałów. Komponenty takie jak urządzenia sprzętowe, media czy różnego rodzaju wtyczki są odpowiedzialne z transmisję sygnału reprezentującego bity. Karty sieciowe, złacza, wtyczki czy same przewody są uwzględnione w standardach warstwy fizycznej.
Kodowanie ma celu dostosowanie strumienia bitów do formatu rozpoznawalnego przez następne urządzenia w sieci poprzez użycie przewidywalnych schematów, które mogą być przez nie rozpoznane. Kodowanie obejmuje takie metody jak: Manchester, 4B/5B czy 8B/10B.
Sygnały natomiast są sposobem reprezentacji bitów (wartości 1 oraz 0) w medium transmisyjnym. Metoda wybranej syganlizacji może być bardzo różna i często jest uzależniona oraz wykorzystywanego medium.
Szerokość pasma jest możliwością nośną pasma. Dla cyfrowych szerokości pasma mierzona jest na podstawie ilości danych, które mogą zostać przesłane z jednego miejsca w drugie w określonej ilości czasu. Jak dużo bitów można przesłać w przeciągu jednej sekundy (bps, bits per second). Właściwosci medium, wykorzystane technologie czy prawa fizyki mają wpływ na dostępną szerokość. Z szerokością pasma są związane pewne pojęcia.
- Opóźnienia (ang. latency) - ilość czasu wraz opóźnieniami potrzebna danym do pokonania trasy z jedne do drugiego punktu.
- Przepustowość (ang. Throughput) - miara transferu bitów przez medium transmisji w określonym odstępie czasu.
- Przepustowość na poziomie aplikacji (ang. Goodput) - miara użytecznych danych przesłanych w w danej jednostce czasu.
1.4.2. Okablowanie miedziane
Okablowanie jest najczęściej stosowanym rodzajem okablowania w sieciach obecnie, jest ono tanie i łatwe do instalacji.
Posiada ono również swoje wady takie jak osłabienie sygnału wynikające z zadługiego pojedynczego odcinka przewodu oraz wrażliwość na róznego rodzaje zakłócenia elektromagnetycze w tym przesłuchy.
Ze względu na to, że okablowanie miedziane jest tak popularne pojawiły się rozwiązania powyższych problemów takich jak: wytyczne pojedynczego odcinka kabla, ekranowanie przewodów wraz uziemieniem skręcenie ze sobą poszczególnych przewodów w pary eliminując przesłuchy.
Rodzaje kabli miedzianych:
- Unshielded Twisted-Pair Cable - Kabel UTP
- Shielded Twisted-Pair Cable - Kabel STP
- Coaxial Cable - Kabel koncetryczny
Kable UTP są najczęsciej spotykami przewodami sieciowymi, są one najczęściej zakończone za pomocą wtyku RJ-45, najczęściej łączą hosty z urządzeniami pośrednimi, jakimi jak przełączniki.
Kable UTP składają się z zewnętrznej izolacji chroniącej kabel przed uszkodzeniami zewnętrznymi oraz skręconych par przewódów (skręcenie ma zadanie zniwelować przesłuchy) w kolorowych izolacjach mających na celu identyfikację każdego z przewodów, każdej z żył.
Kable STP są rozszerzeniem kabli UTP o dodatkowe środki przeciwdziałające zakłóceniom, jak za folia aluminiowa otaczająca poszczególne pary czy siatka miedziana otaczająca wszystkie przewody.
Ostatnim rodzajem kabli miedzianych są kable koncentryczne wykorzystywane do antent sieci bezprzewodowych oraz kablowych technologiach dostęp do Internetu, takich jak DOCSIS. Taki table składa się z zewnętrznej grubszej izolacji, siatki miedzianej niewelującej zakłócenia, plastikowej elastycznej izolacji przewodnika oraz przewodnika.
1.4.3. Okablowanie UTP
Kabel UTP składa się z 4 par oznaczonych kolorami przewodów skrecony ze soba wewnątrz giętkiej plastikowej izolacji. Kable UTP nie posiadają żadnej dodatkowej ochrony przez zakłóceniami. Zastosowane w kablach UTP takie rozwiązania jak znoszenie, każdy przewód w parze ma inną polaryzację, przez co skręcone ze sobą skutecznie znoszą zakłócenia generowane przez siebie czy wariacja w w ilości skręceń na ok. 30cm zapobiera przesłuchą powodowany przez inne pary przewodów pomagają w niwelowaniu przesłuchów.
Kable UTP podlegają standaryzacji, którą zarządza organizacja EIA/TIA. Definiują ona standarad TIA/EIA-568 w którym znajdują się takie zagadnienia jak: Typ kabla, jego długość, rodzaje wykorzystywanych wtyczek, metody terminacji przewódu (w tym instalacji) sposoby testowania. Parametrami elektrycznimi kabli UTP zajęła się organizacja IEEE i do dyspozycji mamy takie kategorie jak: kategoria 3, kategoria 5 lub 5e czy kategoria 6.
Terminując kable, mamy dyspozycji dwa standardy oraz dwa rodzaje takiego zarobionego przewodu. Mianowicie standardy takie jak TIA/EIA T568B oraz T568A definiują ułożenie kolorowych przewodów we wtyczce. Obecnie standardem jest T568B, T568A wyszedł z użycia jednak przydaje się jego znajomość gdy musimy za pomocą sieci spiąć ze sobą dwa komputery. W wyżej wymienionych standardardach możemy ułożyć przewody w następujący sposób:
- T568A -
- biało-zielony
- zielony
- biało-pomarańczowy
- niebieski
- biało-niebieski
- pomarańczowy
- biało-brązowy
- brązowy
- T568B -
- biało-pomarańczowy
- pomarańczowy
- biało-zielony
- niebieski
- biało-niebieski
- zielony
- biało-brązowy
- brązowy
Dwie możliwości zrobienia wtyczek, dają nam dwa rodzaje kabli:
- Kabel prosty - zakończony z obu stron zgodnie ze jednym standardem. Obecnie wykorzystywany zgodnie ze standardem jest T568B, kabel wykorzystywany do większości połączeń.
- Kabel krosowy - zakończony przy użyciu różnych standardów. Dzis może zostać wykorzystany do połączenia bezpośredniego, pomiędzy dwoma komputerami lub dwoma takimi samymi urządzeniami Cisco.
1.4.5. Okablowanie światłowodowe.
Okablowanie światłowodowe nie jest tak popularne jak UTP, ze względu na drogi osprzęt oraz trudności w instalacji. Jest wstanie przesyłać dane na długie dystanse oraz z dużą szybkością, całkowicie odporne na zakłócenia elektromagnetyczne. Światłowody służa przewodzenia implusów świetlnych pomiędzy dwoma ich końcami z minimalną utratą sygnału, są zrobione z cienkich włókien bardzo czystego szkła, do zakodowania bitów w impulsy światła wykorzystują diody laserowe lub diody led.
Światłowody dzielą sie na jedno i wielomodowe. W budowie różnią się w średnicy rdzenia, w światłowodzie jednomodowym jest on o wiele cieńszy, gdyż będzie on obsługiwać tylko jeden promień świetlny. Wykorzystanie światłowodów jednomodowych jest również dużo droższe, ale przesyłaja dane z ogromną prędkością na długi dystans. W światłowodach wielomodowych zachodzi zjawisko dyspersji, czyli rozpraszania się światła, dlatego też światłowody wielomodowe są stosowane na ograniczony dystans, ale dla wielu firm jest on zupełnie wystarczający.
Z okablowaniem światłowodowym możemy spotkać się kilku rożnych rodzajach firm:
- Sieci dużych firm - wykorzystanie światłowodu jako sieć szkieletowa w celu połączanie infastruktury.
- Technologia FTTH - Usługa szerokopasmowego połączenia dla domów oraz małych firm.
- Sieci długodystansowe - sieci łączące kraje czy większe miasta.
- Podwodne światłowody morskie - swiatłowody o dużej przepustowości do połączeń transoceanicznych.
Okablowanie światłowodowe jest wykorzystywane głównie jako sieć szkieletowa łączaca ze soba punkty dostępowe w wewnątrz budynku czy między budnkami na większym terenie.
1.4.6. Medium bezprzewodowe
Działanie sieci bezprzewodowych opiera się na nośności bitów danych z wykorzystaniem sygnałów elektromagnetycznych na częstotliwości radiowej lub mikrofalowej. Sieci tego typu zwiększają mobilność, jednak nie bez wad.
Głównymi problemami sieci bezprzewodowych jest zasięg, który może ograniczać nam dostęp za pośrednictwem tego medium. Kolejnym czynnikiem mogą być zakłócenia, które może powodować wiele urządzeń. Bezpieczeństwo jest również cechą decydującą, nawet jeśli nasza sieć działa na niewielkim obszarze, to napastnik może wyposażyć się w taki sprzęt który pozwoli mu zebranie kilku istotnych informacji. Dość istotną sprawą jest samo działanie sieci bezprzewodowej, urządzenia podłączone do takiej sieci współdzielą to samo łącze, więc jesli będzie ich stosunkowo dużo to przepustowość może spaśc dość znacząco.
Organizacja IEEE wraz z inną instytucją standaryzjąca sporządziła serię standardów dla sieci bezprzewodowych. Opisują one miedzy innymi: metody kodowania sygnałów, częstotliwość oraz moc nadawania, odbiór sygnału oraz dekodowanie transmisji czy wytyczne dotyczące anten. Takim standardami są:
- WiFi (IEEE 802.11) - technologia Wireless LAN
- Bluetooth (IEEE 802.15)
- WiMAX (IEEE 802.16)
- Zigbee (IEEE 802.15.4)
Ogólnie to podłączenie sie do sieci WLAN może wymagać takich urzązeń jak punkt dostępowy, umożliwiający dostęp użytkownikom WLAN-u do sieci kablowej oraz karty sieciowe sieci bezprzewodowej. Przy zakupie sprzetu bezprzewodowego należy pamiętać aby ten sprzęt był kompatybilny ze sobą, często wystarczy zgodność obu wyżej wymienionych urządzeń z jednym ze standardów sieci bezprzewodowej.
Przy rozważaniu wdrożenia sieci bezprzewodowej, trzeba również uwzględnić dla niej odpowiednią politykę bezpieczeństwa.
Zadanie praktyczne - Packet Tracer
Łączenie przewodowych oraz bezprzewodowych sieci LAN - scenariusz Łączenie przewodowych oraz bezprzewodowych sieci LAN - zadanie
Laboratorium
Wyświetlanie informacji o przewodowych i bezprzewodowych kartach sieciowych
Podsumowanie
W tym rodziale rozpoczeliśmy analizowac model sieciowy ISO/OSI. Zapoznalismy się z funkcjami warstwy fizycznej. Scharakteryzowaliśmy każde medium jakie możemy spotkać w sieci.
1.5. Systemy liczbowe
Z systemami liczbowymi, spotykamy się na co dzień licząc lub wykorzystując jego cyfry. Ludzie naturalnie wykorzystują bowiem system dzięsiętny, które podstawą jest liczba 10 oraz znaki od 0-9. W przypadku komputerów, wykorzystywane jest ich znacznie więcej a takimi podstawowymi są: system binarny oraz system heksadecymalny oba te systemy znajdują swoje zastosowanie w sieci.
1.5.1. Binarny system liczbowy
Binarny system liczbowy składa się z 1 oraz 0 nazywanych bitami. Adresy protokołu IP zapisem poniękąd binarnym, adres składa się z ciągu 32-bitów podzielonych na cztery sekcje zwane oktetami. Każdy oktet składa się 8 bitów lub jednego 1 bajtu. Jednak ludzie w celu uproszczenia sobie nieco pracy wykorzysują zapis dziesiętny, konwertując poszczególne oktety. Dlatego też oktety adresów IP posiadają zakres wartości od 0 do 255.
Binarny system liczbowy podobnie do systemu dziesiętnego jest systemem pozycyjnym. Pozycyjność polega na tym, że cyfry reprezentują wartości na podstawie pozycji, na której się znajdują w sekwencji cyfr (liczbie). Spójrzmy na poniższy przykład, prostą liczbą dzięsiętną, którą możemy rozpatrzyć pod kątem pozyjności może być: 1234.
1 x 10^3 (1000) = 1000 + 2 x 10^2 (100) = 200 + 3 x 10^1 (10) = 30 + 4 x 10^0 (1) = 4
Podobnie jest z cyframi binarnymi, tak jak tutaj brano po uwagę potęgę wykładnika jakim jest liczba 2. Rozważmy sobie przykład liczby: 10110010.
1 x 2^7 (128) = 128
+
0 x 2^6 (64) = 0
+
1 x 2^5 (32) = 32
+
1 x 2^4 (16) = 16
+
0 x 2^3 (8) = 0
+
0 x 2^2 (4) = 0
+
1 x 2^1 (2) = 2
+
0 x 2^0 (1) = 0
= 178
Analizując pozycyjność cyfr binarnych, przypadkiem dowiedzieliśmy się w jaki sposób możemy dokonąć konwersji wstecznej z cyfr binarnych na postać dziesiętną.
Konwersji liczb dziesiętnych możemy dokonać w na dwa sposóby. Jednym z nich może być metoda pisemna. Polega ona na dzieleniu liczby przez dwa do momentu uzyskania 0, przyczym wiemy, że nie wszystkie liczby dzielą się na dwie równe częsci. Ta pozostałosc to reszta z dzielenia i przeważnie w wyniku dzielnia przez dwa jej wartość nie będzie wynosić więcej niż 1. Dlatego też reszta z dzielenia albo będzie występować (wówczas, będzie wynosić 1) albo jej nie będzie ponieważ cyfra podzieli się równo. Czy ten schemat nam coś przypomina. Tak, reszta z dzielenia to nasza wartość binarna. Ale tutaj jest pewien haczyk.
178 / 2 = 89 | 0 89 / 2 = 44 | 1 44 / 2 = 22 | 0 /\ 22 / 2 = 11 | 0 || 11 / 2 = 5 | 1 || 5 / 2 = 2 | 1 || 2 / 2 = 1 | 0 1 / 2 = 0 | 1
Otóż wartości reszty z dzielnia są odczytywane z dołu do góry. 178DEC = 10110010BIN.
Inny sposóbem jest próba oszacowania. Bierzemy na 178 i szukamy nawiększej potęgi dwójki mniejszej od naszej liczby w tym przypadku jest 128. Następnie sprawdzamy czy nasza liczba jest większa bądź równa 128. No tak. Zatem zapisujemy skranie po lewej stronie 1 i odejmujemy od naszej liczby bazowej 128 (178-128) pozostaje nam 50 itd. tak jak na przykładzie.
178 >= 128 = 1 178 - 128 = 50 50 >= 64 = 0 50 >= 32 = 1 50 - 32 = 18 18 >= 16 = 1 18 - 16 = 2 2 >= 8 = 0 2 >= 4 = 0 2 >= 2 = 1 2 - 2 = 0 0 >= 1 = 0 10110010
Postać binarna zamienianej liczby powstaje z wyników warunków logicznych jeśli przyjmiemy, że Tak to 1 a Nie to 0. Ta metoda pozwala na przeliczanie liczb w pamięci. Metodę odwrotnej konwersji już poznalismy przy poznawania pozycyjności.
1.5.2. System szesnastkowy
System heksadecymalny w przypadku sieci może przydzać się do zrozumienia IPv6. System ten wykorzysuje jako bazę 16 cyfr 0-9 oraz od A-F. Jedna cyfrę heksadecymalną możemy wyrazić za pomocą 4 binarnych bitów. System ten jest wykorzystywany tak jak wcześniej wspomniano do IPv6 oraz adresów fizycznych.
Chcąc skonwertować liczbę dziesiętna na heksadecymalną, możemy posłużyć się metodą pisemną tylko zamiast 2 użyć liczby 16. Raczej nie bedzie takie potrzeby aby to robić. Innym rodzajem konwersji możebyć przeliczenie z systemu binarnego na szesnastkowy. Tutaj nie trzeba nic przeliczać, wystarczy odwołać się do tabelki o poniżej.
0000 = 0 0001 = 1 0010 = 2 0011 = 3 0100 = 4 0101 = 5 0110 = 6 0111 = 7 1000 = 8 1001 = 9 1010 = A 1011 = B 1100 = C 1101 = D 1110 = E 1111 = F
Jeśli mamy przeliczyć cyfrę dziesiętna to możemy zrobić to bezpośrednio przez metodę pisemną lub pośrednio, zamienić ją na system binarny bo taki jest prosty do przeliczenia a następnie zgodnie z tablą powyżej zamienić 8 bitów binarnych na dwie cyfry heksadecymalne dające żądana liczbę. Pamiętamy że nasze 178 to 10110010 to chcąc zamienić tę liczbę na system szesnastkowy możey zrobić to tak:
178 = 1011 0010
B 2
178 = B2
B = 1011
2 = 0010
B2 = 10110010 = 178
Podsumowanie
W tym jakże, krótkim rozdziale poznaliśmy dwa podstawowe system liczbowe wykorzystywane także w sieciach. Nauczyliśmy się konwersji z systemu 10 na binarny oraz z systemu binarnego na szesnastkowym i odwrotnie. Konwersja systemów a w szczególności z dziesiętnego na binarny będzie nam potrzebna do podziału sieci na podsieci oraz metody VLSM.
1.6. Warstwa łącza danych
Warstwa łącza danych jest pierwszą warstwą, w której możemy spotkać się jaką komunikacją logiczną. Sztandarowym protokołe tej warstwy jest Ethernet a podstawową jednostką przesyłanych danych jest ramka.
1.6.1. Przeznaczenie warstwy łącza danych
Warstwa łącza danych jest odpowiedzialna za komunikację pomiędzy kartami sieciowymi, pozwala warstwą wyższym na dostęp do medium fizycznego oraz enkapsuluje pakiety warstwy 3 w ramki warstwy drugiej oraz dokonuje detekcji błędów i odrzuca uszkodzone ramki.
Standardy IEEE 802 LAN/MAN określają typ sieci (Ethernet, WLAN, WPAN itd.). Warstwa łącza danych składa się z dwóch podwarstw: Logical Link Control (LLC) oraz Media Access Control (MAC). Podwarstwa LLC zapewnia komunikację pomiędzy oprogramowaniem sieciowym z warstw wyższych a sprzętem z warstwy niższej, natomiast podwastwa MAC odpowiedzialna jest za enkapsulację danych oraz dostęp do łącza fizycznego.
Pakiety wymieniane między hostami, mogą doświadaczać wielu zmian na poziomie warstw niższych, dla porównania jeśli router odbierze ramkę to musi ją za akceptować na swojej karcie sieciowej, następnie zdekapsulować aby uzyskać potrzebne mu dane. Po wykonaniu czynności pakiet jest enkapsulowany ponownie w nową ramkę i przekazany za pomocą medium transmisjnego do następnej sieci.
Protokoły warstw łacza danych zostały zdefiniowane przez takie organizacje inżynieryjne jak: Institute of Electrical and Electronic Engineers (IEEE), International Telecomunications Union (ITU), International Organizations for Standarization (ISO) American National Standards Institute (ANSI).
1.6.2. Topologie
Toplogia sieciowa jest układ między urządzenia sieci oraz połączeniami występującymi między nimi. Rozróżniamy dwa rodzaje topologi:
- Fizyczna - przedstawiająca fizyczne połaczenia miedzy urządzeniami, np. użyte medium transmisji czy rodzaj podłączenia między nimi.
- Logiczna - przedstawiająca połaczenia wirtualne, interfejsy czy adresację IP.
W sieciach rozległych możemy wyróżnić kilka topologi fizycznych takich jak:
- Point-to-point - najprostsza i naczęsciej spotykana topologia WAN. Składa się ona ze stałego połączenia pomiędzy dwoma punktami końcowymi.
- Hub and spoke - podobna do topologii gwiazdy gdzie centralne urządzenie pośrednicy pomiędzy połączeniami point-to-point.
- Mesh - topologia dostarcza wysoki stopień dostępności usług, ale wymaga aby system były ze sobą połączone na zasadzie każdy z każdym.
Urządzenia końcowe takie jak komputery czy laptopy są podłączone do sieci lokalnych najczęsciej wykorzystujących topologię gwiazdy oraz topologię gwiazdy rozszerzonej (topologię hybrydową). Topologie tego typu są łatwe w instalacji oraz w rozwiązywaniu problemów, przy tym bardzo skalowalne. Na początkach instnienia sieci, były jeszcze dwie topologie: magistrali oraz pieścienia, ale nie odnalazływ sie one we współczesnych warunkach.
W sieciach komputerówych komunikacja jednoczesna komunikacja z drugą stroną może odbywać się albo na zasadzie half-duplex, gdzie w jednym czasie może nadawać lub odbierać tylko jeden host. Tego typu komunikacja zachodzi np. w sieciach bezprzewodowych, albo na zasadzie full-duplex, gdzie hosty mogą nadawać i odbierać informacje jednocześnie w tym samym czasie, tego typu transmisja zachodzi w sieciach Ethernet opartych na przełączniku.
Jeśli działamy w trybie half-duplex-u, to musimy określić metodę dostępu do łącza. W technologiach Ethernet istnieją dwa algorytmy, które badają dostęp do łącza są nimi CSMA/CD wykorzystywany w starym Ethernecie opartym na topologi magistrali, gdzie komputery łączył jeden wspólny kabel. Kolejnym mechanizmem stosowanym w sieciach bezprzewodowych jest modyfikacja wyżej wymienionego CSMA/CA.
Kiedy w starym algorytmie CSMA/CD, wykrywało się kolizje (moment, gdy dwie stacje nadają jednocześnie), to w przypadku sieci bezprzewodowych wprowadzono ich unikanie. Funkcja unikania kolizji, polega na tym, że jeśli stacja nadaje to nadaje jednocześnie informacje o tym ile czasu porzebuje na transmisje. Pozostałe hosty dostają te informacje i wstrzymują się z nadawaniem do upłynięcia zadeklarowanego czasu.
1.6.3. Ramka łącza danych
Dane enkapsulowane przez warstwę łącza danych wraz z nagłówkiem oraz stopką tworzą ramkę. Ramka składa się z nagłówka, danych oraz stopki, w zależności od użytego protokołu tej warstwy pola nagłówka oraz zawartość stopki może się różnić, podobnie może być ilością danych kontrolnych. Pola przeciętnej ramki prezentują się następująco:
- Początek oraz koniec ramki - pola kontrolne mające za zadanie wskazać początek oraz koniec ramki.
- Adresacja - pola zawierające adres źródłowy i docelowy.
- Typ - pole zawierające wskazanie protokołu warstwy wyższej.
- Kontrola - pole zawierające informacje, służace mechanizmom kontroli przepływu ruchu.
- Dane - pole zawierające ładunek, najcześciej PDU warstwy wyższej.
- Detekcja błędów - pole wykorzystywane w detekcji błędów.
W większość wyżej wymieniony pól znajduje się w nagłówku, ale detekcja błędów oraz koniec ramki znajdują się w stopce.
Adresy warstwy drugiej, nazwywane również fizycznymi, znajdują się wewnątrz nagłówka ramki i są wykorzystywane tylko i wyłącznie do dostarczenia jej lokalnie (w obrębie sieci lokalnej). Jeśli wymagane jest przezkazanie ramki dalej do inne sieci, to te adresy muszą zostać zmienione.
Topologie logiczne oraz fizyczne media często mają wpływ na wybór określonego protokołu warstwy wyższej. A jest z czego wybierać:
- Ethernet
- 802.11 WLAN
- Point-to-point (PPP)
- High-Level Data Link Control (HDLC)
- Frame-Relay
Każdy z tych protokołów posiada swoje mechnizmy kontroli dostepu do medium, dla określonych topologi logicznych.
Podsumowanie
W tym rozdziale poznaliśmy podstawowe zagadnienia związane z drugą warstwą - warstwą łącza danych. Ten rozdział również rozpoczyna jej bardziej szczegółowe omawianie oraz wstęp do technologi Ethernet i przełączników.
1.7. Przełączanie Ethernetu
W tym rozdziale zapoznamy się ze szczegółami technologii Ethernet, potrzebnymi do zrozumienia działania takiego urządzenia jak przełączniki. Poznamy również meteody przełączania jakie możemy spotkać w dostępnych na rynku przełącznikach.
1.7.1. Ramka Ethernet
Ethernet operuje w warstwie fizycznej oraz łącza danych, opisują go dwa standardy IEEE 802.2 oraz 802.3.
Standardy rodziny 802 wykorzystywane w sieciach LAN/MAN w tym i Ethernet wykorzystują dwie podwarstwy warstwy łącza danych. LLC, której zadaniem jest umieszczenie w ramce Ethernet informacji o wykorzystywanym protokole warstwy sieciowej dla tej ramki. Drugą podwarstwą jest MAC odpowiedzialna za enkapsulacje danych, kontrolę dostępu do łącza oraz adresacje w warstwie łącza danych.
Podwarstwa MAC jest odpowiedzialna za enkapsulację danych oraz dostęp do łącza danych. Jesli chodzi o samą enkapsulację to podwarstwa MAC zajmuje się ramką Ethernet - jej wewnętrzną strukturą; adresacją Ethernetu - ramki muszą zawierać adresy MAC źródła oraz hosta docelowego, aby dostarczyć je z jedenj karty sieciowej do drugiej; detekcją błędów Ethernetu ramki zawierają w stopce pole FCS Frame Check Sequence wykorzystywane do detekcji błedów.
W ramach kontroli dostępu do łącza Ethernet, podwarstwa MAC zawiera specyfikację dla różnych standardów komunikacyjnych Ethernetu przez różnego rodzaju łącza takie jakie okablowanie miedziane lub światłowody. Stary Ethernet wykorzystywał topologę magistrali lub koncentrator, które są współdzielonym medium działającym w trybie half-duplex. Ethernet przez tego typu łącza wymagał mechanizmów badania dostępności łącza oraz detekcji błędów. Temu służył algorytm CSMA/CD (ang. Carrier Sense Multiple Access/Colision Detection). Obecnie Ethernet wykorzystuje przełączniki przez co komunikacja może odbywać się w trybie full-duplex i nie ma potrzebny stosowania mechanizmu CSMA/CD ponieważ ta magistrala przy starym Ethernecie jest teraz jednym kablem łączącym kartę sieciową z portem przełącznika.
Jeśli chodzi o pola ramki Ethernet to najpierw warto sobie powiedzieć, że minimalną wielkością ramki mogą być 64B a maksymalną 1518B. Preambuła nie jest wliczana do ramki jeśli chodzi o jej wielkość. Wszelkie ramki mniejsze niż 64B są uważane za ramki uszkodzone i automatycznie odrzucane. Ramki przekraczające górną granice wielkości uważane są za ramki typu jumbo. Ramki przekraczające rozmiary lub mniejsze niż minimalny rozmiar, są zazwyczaj uznawane za rezulat kolizji lub niechciany sygnał. Przez odbiorców mogą być uznane za nieprawidłowe. Większe ramki są akceptowane do technologi FastEthernet w góre.
Laboratorium
Używanie programu Wireshark do badania ramek Ethernet
1.7.2. Adres MAC Ethernetu
Adres MAC składa się z 48 bitów zapisanych za pomocą 12 cyfr systemu heksadecymalnego, 6 par po 2 cyfry. Dwie cyfry heksadecymalne to 1 bajt. Poprzedzającje zera są również zapisywane, aby każda z grup miała te 8 bitów. Cyfry heksadecymalne mogą być czasem zapisywane z przedrostkiem 0x lub z przyrostkiem H/h.
Ethernet był projektowany z myślą o tym, że urządzenia sieciowe są podłączone do współdzielonego medium (magistrali) i adresacja MAC pozwala na identyfikacje takiego hosta. Ze tego powodu wszyskie adresu MAC muszą być unikatowa w obrębie całej sieci. W tym celu każdy z dostawców sprzętu działającego w sieci Ethernet muszą zarejestować się w IEEE aby uzyskać 6 cyfrowy (heksadecymalnych) kod nazwany unikalnym indentyfikatorem organizacji (OUI). Każdy adres MAC składa się z kodu OUI przypisanego do producenta sprzętu oraz pozostałych 6 cyfr przypisanych przez producenta do konkretnej sztuki produktu.
Przetwarzanie ramek ma swój początek już na komputerze źródłowym. Każda ramka zawiera adres źródłowy oraz adres docelowy. Kiedy karta sieciowa odbierze taką ramkę porówna jej adres docelowy MAC z z adresem swojej kartym, jeśli adres jest taki samy oznacza to, że ramka jest przeznaczona dla tego hosta. Ramka dekapsulowana i przekazana do warstw wyższych. Obecnie większość urządzeń wykorzystuje Ethernet, więc tego typu przetwarzanie danych jest podstawą wszlakiej komunikacji w sieci. Warto wspomnieć o tym, że karty sieciowe akceptują rownież ramki typu broadkast oraz multikast tych grup, do których ten host należy.
W Ethernecie różne adresy MAC są wykorzystywane do transmisji unikast, broadkast oraz multikast w warstwie drugiej. Adres MAC unikastowy jest wykorzystywany do transmisji między pojedynczymi hostami w sieci. Adresy MAC są powiązane z adresami warstwy sieciowej, są one uzyskiwane za pomocą protokołów ARP (dla IPv4) lub ND (IPv6). Przy tych wszystkich rodzajach adresów, a co za tym idzie rodzajach transmisji adresem źródłowym zawsze adres unikastowy.
Ramkę ethernetową transmisji broadkast odbierze każdy host znajdujący się w tej samej sieci Ethernet LAN. Broadkastowy adres MAC składa się wyłącznie z samych cyfr F. Przez przełączniki jest on przekazywany na wszystkie porty poza tym z którego ta ramka została przysłana. Oczywiście transmisja broadkast w Ethernecie zawiera w sobie pakiet IP z tym samym rodzajem transmisji, oznacza to, że dane zawarte w tej transmisji zostaną przetworzone przez wszystkie host w tej sieci lokalnej (domenie rozgłoszeniowej), które ten pakiet otrzymają.
Przypadek transmisji multikast w Ethernet jest trochę bardziej skomplikowany. Taką ramkę odbiorą hosty, które należą do tej samej grupy. Transmisja multikast w Ethernet jest powiązana z rodzajem tego typu transmisji w protokole IP, dla wersji 4 mamy adres (początek): 01-00-5E, a dla wersji 6 33-33. Innym rodzajem multikastu w Ethernecie jest protokół STP, nie jest on protokołem warstwy 3, a drugiej i zawiera swój adres docelowy typu multikast. Transmisje multikast opuszczają przełącznik w ten sam sposób co transmisja broadkast, chyba że urządzenie skonfigurowano inaczej (mechanizm multicast snooping), transmisja ta nie jest przekazywana przez router, chyba że został poinstuowany aby trasować pakiety multikast. Ze względu na to, że adresy multikast reprezentują grupe hostów, mogą zostac użyte tylko i wyłącznie jako adres docelowy, adresem źródłowym musi być adres unikast. Tak jak w przypadku transmisji unikast oraz broadkast, transmisja multikast wymaga odpowiadających adresom Ethernet, adresów IP.
Laboratorium
Odczytywanie adresów MAC urządzeń sieciowych
1.7.3. Tablica adresów MAC
Ethernetowy przełącznik warstwy drugiej dokonuje swoich decyzji o przełączaniu na podstawie adresu MAC, który jest zapisany w tablicy adresów MAC przełącznika, na podstawie informacji tam zapisanych przełącznik wie na jaki port należy przesłać dane, adresowane do komputera o takim adresie MAC. W momecie włączenia urządzenia jego tablica nie zawiera żadnych wpisów i musi się ich nauczyć. Tablica MAC często nazwyana jest CAM (ang. content addressable memory table).
Nauka adresów MAC przez przełącznik, czy też uzupełnienie tablicy polega na badaniu każdej przychodzącej do urządzenia, ramki w celu uzyskania nowych informacji. Badany jest przede wszystkim adres źródłowy oraz port, na którym te dane dotarły do przełącznika, następnie te informacje są konfrontowane z tabelą jeśli taki adres MAC pod takim portem nie występuje wówczas te dane są dopisywane lub poprawiane w zależności od tego czy w przeciągu czasu ważności wpisów w tablicy MAC ruch sieciowych przechodził przez ten port. W przeciwnym wypadku wpis jest odświerzany co powowduje, że jego czas jego ważności został zresetowany. W przypadku większości przełączników czas wazności wpisów w tablicy to 5 minut. W przypadku przepięcia hosta do innego portu, w tablicy we wpisie z adresem zostanie zamieniony port, pod którym ten MAC może występować.
W przypadku przekazywania ramek, działa to w sposób analogiczny, tylko przełącznik zamiast zapisywać odczytuje informacje z tablicy MAC. Jeśli adres docelowy jest unikastowy, to jest on sprawdzany w tablicy, w celu ustalenia portu docelowego przełącznika dla docelowego hosta. Jeśli wpis zostanie odnaleziony, to ramka zostaje przezkazna na ten port. W przeciwnym wypadku zostanie on przekazany na wszystkie porty poza tym źródłowym (z którego trafił do przełącznika). Podobnie przełącznik zachowuje się w przypadku transmisji broadkast oraz multikast.
Laboratorium
Przeglądanie tablicy adresów MAC przełącznika
1.7.4. Przepustowość przełącznika oraz metody przekazywania.
Przełączniki używają jednej z poniższych metod przełączania danych danych między portami.
- Przełączanie store-and-forward - w tej metodzie przełącznik musi otrzymać całą ramkę, następnie oblicza jej CRC. Jeśli CRC jest prawidłowe, wówczas dochodzi do przełączania znanego z poprzednie podrozdziału.
- Przełączanie cut-through - tutaj przełącznik nie czeka całą ramkę, wystarczy mu odczytać adres docelowy, aby dokonać przełączenia.
Zaletą metody store-and-forward jest możliwosc wykrycia błędów zanim ramką zostanie przekazana dalej. Jeśli błąd zostanie wykryty przełącznik odrzuci ramkę. Odrzucanie uszkodzonych ramek pozwala zredukować żużycie przepustowści na przesyłanie uszkodzonych ramek. Metoda store-and-forward jest również wymaga przez metody priorytetyzacji ruchu takie jak QoS.
Metoda przełączania cut-through przełącza dane zanim w całości dotrą do przełącznika, jego bufor jest na tyle duży, że może odczytać docelowy adres MAC i na podstawie tego dokonuja przełącznia. Ta metoda występuje w dwóch wariantach:
- Przełączanie fast-forward - ta metoda przełączania oferuje najmniejsze opóźnienia. Jeśli zostaną przekazane uszkodzone ramki, to zostaną one odrzucone przez docelową kartę. Jest to domyślny wariant dla metody cut-through.
- Przełączanie fragment-free - jest kompromis między cut-through oraz store-and-forward. Przełacznik pobiera i sprawdza pierwsze 64 bajty ramki przed przełączeniem. W większości sieci błedy są do wykrycia już tych pierwszych 64 bajtach ramki, przez co przełącznik może mieć pewność, że te ramki są całe i można je przekazać dalej.
Wspominając o sposobach przełączania, warto również omówić pamięć bufora w przełączniku. Bufor jest wykorzystywany gdy port docelowy może być zbyt zajęty, żeby przyjmować kolejne ramki, do dyspozycji mamy:
- Pamięc portów - Ramki są przechowywane w kolejkach powiązanych z portami wejściowymi oraz wyjściowymi. Ramka jest przekazywana na port wyjściowy tylko wtedy gdy ramki przed nią zostały poprawnie przesłane. Mozliwe jest opóźnienie transmisji wszystkich ramek w pamięci przez pojedyńczą ramkę, ze względu na obciążenie portu docelowego. Opóźnienia występują nawet wtedy gdy inne ramki mogą zostać przesłane na otwarte porty docelowe.
- Pamięć współdzielona - przechowuje wszystkie ramki we ogólnym buforze pamieci współdzielonym ze wszystkimi portami przełącznika, ilość pamięci potrzebna dla konkretnego portu jest przydzielana dynamicznie. Ramki w buforze dynamicznie powiązane z portami docelowymi. Pakiet może nadejść z jednego portu i być przekazywany do innego to niezostanie on przeniesiony do innej kolejki.
Buforowanie w pamięci współdzielonej pozwala na transmisję większych ramek z mniejszymi stratami. Jest ważne dla przełączania asymetrycznego, które pozwala na różne prędkości danych na różnych portach. Dzięki czemu większa przepustowość może zostać przypisana do niektórych portów, np. porty serwerów.
Dwoma najbardziej podstawowymi ustawieniami przełącznika są przepustowość (przełączniki mogą działać w standardach wstecznych Eternetu) oraz duplex (możliwość nadawania i odbierania danych w tym samym momencie). Do dyspozycji mam full-duplex - oba urządzenia końcowe mogą nadwać i odbierać dane jednocześnie lub half-duplex - tylko jedna ze stron może nadawać w tym czasie.
Prawdopodobnie nie będzie trzeba konfigurować tych ustawień. Tym zajmuje się mechnizm autonegocjacji, urządzenia miedzy sobą ustalają najlepsze ustawienia dla warunków fizycznych. Gigabitowy Ethernet do działania wymaga full-duplex-u.
Nie pasujący duplex jest przyczną większości problemów z z wydajnościa w sieciach Ethernetowyc 10/100Mbps. Przyczyna tych problemów może być ustawienie portu przełącznika w half-duplex natomiast druga strona ma ustawiony full-duplex, dzieje się tak gdy połączenie między tymi stronami zostanie zresetowane a autonegocjacja nie będzie wstanie ustalić takie samej konfiguracji dla obu stron lub gdy zmienimy konfigurację na jednym urządzeniu i zapomnimy to zrobić na drugim urządzeniu. Najlepszą praktyką to albo włączyć na obu autonegocjację, albo na obu wyłączyć. Można również ustawić na portach przełącznika na stałe full-duplex.
Połaczenia między urządzeniami mogą wymagać różnego rodzaju połączeń.
mowa tutaj o kablach prostych oraz o kablach skrosowanych. Zazwyczaj
połączenia między routerami wymagają kabli skrosowanych jak połączenia
bezpośrednie między dwiema stacjami. Obecnie mało kto pamiętam o tym
ponieważ mamy do dyspozycji funkcję Auto-MDIX, która
mimo połączenia urządzeń za pomocą prostych przewodów, dokona
skrosowania już wewnatrz interfejsu. W sprzętach marki Cisco,
a szczególnie w przełącznikach ta funkcja jest raczej włączona, ale
to może być różnie (w zależności jak stare jest to urządzenie). Więc
warto
zawsze używać wymaganych przewodów lub też możemy spróbować włączyć
tę funkcję za pomocą polecenia: mdix auto
w trybie konfiguracji interfejsu.
Podsumowanie
W tym rodziale przybliżliśmy sobie szczegóły technologii Ethernet, poznaliśmy adres MAC oraz tablice MAC przełączników. Dowiedzieliśmy też jakie są metody przełączania oraz podstawowe ustawienia przełącznika.
1.8. Wartstwa sieciowa
Warstwa sieciowa dostarcza usługi pozwalające na wymianę danych między hostami. Podstawowym jej protokołem jest protokół IP zarówno w wersji 4 jak i 6. Warstwa sieciowa odpowiada adresacje urządzeń końcowych, enkapsulację, routing oraz deenkapsulacje.
1.8.1. Charakterystyki warstwy sieciowej
Protokół IP enkapsuluje segmenty z wartstwy transportowej, nie ma znaczenia czy użyjemy wersji 4 czy 6 protokołu IP, na ten segment nie będzie to miało wpływu. Pakiet IP będzie analizowany przez wszystkie urządzenia warstwy 3 (lub mogące w niej działać) na swojej drodze do punktu docelowego. Generalnie to adres protokołu IP nie powinny się zmienić na drodze między hostem źródłowym a hostem docelowym, wyjątkiem od tej reguły jest mechanizm NAT. Protokół IP opisywany jest jako bezpołączeniowy, niezależny od medium transmisyjnego oraz najlepszej możliwości.
Protokół IP jest bezpołączeniowy. IP nie ustanawia żadnego połączenia ze stroną docelową przed wysłaniem pakietu, nie potrzeba żadnych informacji kontrolnych. Host docelowy otrzyma pakiet kiedy on nadejdzie, nie ma żadnych wcześniejsych powiadomień. Jeśli wymagane jest połączenie, wówczas jest to powierzane warstwie wyższej, warstwie transportowej, a konkretnie protokołowi TCP.
Protokół IP jest uznawana za protokół najlepszej możliwości porzez zmniejszenie narzutu spowodowanego brakiem mechnizmów retransmisji, nie ma potwierdzeń o tym, że pakiet dotarł. IP nawet na nie, nie oczekuje. Protokół również nie ma informacji na temat czy host w ogóle funkcjonuje i otrzymuje wysłane do niego pakiety.
Ze względu na to, że protokół IP jest protokołem najlepszej możliwości uznawany jest za nierzetelny. Jednak te funkcje nie sprawdzają się w każdym możliwym przypadku, dlatego też brak ich w protokole IP, który w obenych czasach musi obsłużyć 99% ruchu w sieci. Protokół IP jest protokołem niezależnym od medium transmisjynego oznacza to, że może on przesyłać dane przez dowolne połączenie między dwoma hostami. Przyczym wprowadza on pojęcie MTU (Maximum Transmission Unit). Ten protokół utrzymuje informacje o tym jakie MTU ma ustawić od warstwy łącza danych. Innym mechanizmem protokołu IP jest fragmentacja, pozwala ona dzielić pakiety na mniejsze części, na przykład gdy nasza technologia WAN ma mniejsze MTU.
1.8.2. Pakiet IPv4
Protokół IP wersji 4 jest podstawowym protokołe komunikacyjnym w warstwie sieciowej, a sam nagłówek jest dość istotny w całej transmisji. Zapewnia, że pakiet zostanie wysłany do właściwego odbiorcy, zawiera w swoich polach wiele informacji ważnych dla przetwarzania pakietów. Informacje z nagłówka wykorzystują wszystkie urządzenia mogące przetwarzać dane z warstwy sieciowej. W nagłówku IP mimo wszystko najważniejszą informacją są pola a zawierające adresy, dość ciekawy polem tutaj jest pole Protocol, gdyż może mieć więcej niż jedną funkcję. Poniżej znajduje się bardziej szczegółowy opis poszczególnych pól:
- Wersja - 4-bitowe pole zawierające wersję IP w tym przypadku: 0100 = 4.
- Zróżnicowane usługi - pole wykorzystywane przez QoS, może mieć rózne oznaczenie: DS, DiffServ lub IntServ czy ToS Type of Service.
- Suma kontrolna nagłówka - pole wykorzystywane do detekcji uszkodzeń nagłówka.
- Pole TTL - licznik skoków w warstwie 3. Kiedy zostanie wyzerowane router odrzuci pakiet.
- Protokoł - wskazuje na protokół, którego dane są niesione w tym pakiecie, np.: ICMP, TCP czy UDP.
- Adres źródłowy IPv4 - adres IPv4 hosta wysłającego pakiet.
- Adres źródłowy IPv6 - adres IPv4 hosta docelowego.
1.8.3. Pakiet IPv6
Protokół IPv4 posiada swoje ograniczenia. Pierwszym z nich jest wyczerpanie się adresów IP w swojejwersji, inna przeszkodą może być brak bezpośrednich połaczeń, obecnie łączymy się z pośrednictwem adresów prywatnych oraz NAT-u, a użycie mechnizmu NAT powoduje potrzebę zmiany nagłówków, co może powodować opóźnienia oraz zwiększać złożoność sieci.
Remedium na powyższe ograniczenia jest globalne wdrożenie IPv6. IPv6 zwiększa długość adresu z 32-bitów do 128 przez co ich ilość zwiększa o bardzo duża liczbę (340 x 10^36), gdzie adresów IPv4 mamy lekko powyżej 4 miliardy. Zmniejsza się również nagłówek pakietu, zostaje pozbawiony kilku pól. Ze względu na ilość operowalnych adresów nie ma potrzeby stosowania NAT-u.
Sam nagłówek IPv6 został uproszczony, ale nie zmniejszony. Nagłówek IPv6 ma długość 40B, wiele z pól zostało zostało usuniętych aby zwiększyć wydajność. Ponizej znajduje się opis poszczególnych pól nagłówka IPv6.
- Wersja - wersja protokołu 4 bity dla IPv6 to: 0110.
- Klasa ruchu - pole dla QoS.
- Etykieta przepływu - 20-bitowe pole informujące urządzenia, aby przetwarzały pakiety z tą samą wartością tego pola w ten sam sposób.
- Długość ładunku - 16-bitowe pole określa długość danych niesionych przez ten pakiet.
- Następny nagłówek - wskazuje na protokół warsty wyższej, której dane niesie.
- Limit skoków - licznik skoków w warstwie sieciowej
- Adres źródłowy IPv6 - 128-bitowy adres źródłowy.
- Adres docelowy IPv6 - 128-bitowy adres docelowy.
Dodatkowo pakiety IPv6 mogą zawierać rozszerzenie nagłówka, które może zawierać dodatkowe informacji warstwy sieciowej takie jak fragmentacja, informacje odnośnie bezpieczeństwa czy wsparcie dla mobilności. To rozszerzenie jest opcjonalne i umiesczone jest między danymi a nagłówkiem. W przeciwieństwie do IPv4 routery IPv6 nie fragmentują pakietów.
1.8.4. W jaki sposób host przesyła pakiety
Każdy host posiada w swojej konfiguracji TCP/IP tablicę routingu. Pakiety przez niego wygenerowane mogą być wysłane do siebie po przez adres pętli zwrotnej: 127.0.0.1 (IPv4), ::1 (IPv6); do hostów lokalnych znajdujących się w tej samej sieci czy też do hostów zdalnych znajdujących się poza naszą siecią lokalną.
To host źródłowy decyduje o tym czy adres docelowy jest adresem lokalnym czy też pochodzącym z poza sieci. W zależności od wersji protokołu są dwie metody. Host konfrontuje swój adres oraz maskę obliczając adresy sieciowe (adres sieci i broadcast) z adresem docelowym w przypadku IP w wersji 4. W przypadku IP w wersji 6, host wykorzystuje adres sieci oraz prefix przedstawiony mu przez najbliższy router. Ruch lokalny opuszcza kartę sieciową hosta i jest przetwarzany przez urządzenia pośredenie, takie jak przełączniki. Jeśli ruch jest ewidentnie adresowany na zewnątrz, jest on kierowany do prosto do bramy oczywiści z pośrednictwem urządzeń po drodze do routera.
Urządzenia warstwy 3, takie jak routery lub przełączniki L3 mogą być domyślną bramą dla hostów w sieci lokalnej. Cechami domyślnej bramy są na pewno: adres IP urządzenia/interfejsu musi znajdować się w tej samej sieci lokalnej, urządzenia tego typu przyjmują ruch z sieci lokalnej i kierują ją po za nią, mogą trasować ruch do innych sieci. Jeśli hosty w sieci nie posiadają skonfigurowanej bramy lub jej adres adres jest niepoprawny nie będą wstanie przesyłać danych poza sieć.
Host adres bramy może mieć zapisany w swojej konfiguracji statycznie lub otrzymać go wraz z dzierżawą adres IP z serwera DHCP, w przypadku protokołu IPv6 adres bramy może zostać otrzymany z komunikatów router advertisement (RA) lub skonfigurowany ręcznie.
Za pomocą poleceń netstat -r dla
(systemy MS Windows) czy ip route
(dystrybucje Linuksa). Możemy wyświetlić tablicę routingu zapisaną
na systemie hosta.
xf0r3m@laptop-026253a/ ~/ ip route default via 192.168.8.1 dev enp0s31f6 proto dhcp src 192.168.8.133 metric 100 192.168.8.0/24 dev enp0s31f6 proto kernel scope link src 192.168.8.133 metric 100
1.8.5. Wprowadzenie do routingu
Załóż czysto hipotetycznie, że chcemy przesłać pakiet do sieci obok, co sie stanie? Taki pakiet jeśli osiągnie router, ponieważ nasz host wysłał tę ramkę do bramy domyślnej, to router sprawdzi adres docelowy i wzależności czy posiada trasę do tego hosta, to wyśle go na pierwszy router w tej trasie, lub jeśli sieć docelowa jest wpięta do tego samego routera zostanie przekazana na interfejs obsługjący tę sieć. Router dokonuje tych decyzji opierając się o zapisaną w swojej pamięci tablicę routingu.
W routerach możemy spotkać trzy rodzaje tras w ich tablicach.
- Podłączone bezpośrednio (ang. Directly Connected) - te trasy są dodwane domyślnie bazując na aktywnych interfejsach i powiązanych z nimi adresach.
- Zdalne (ang. Remote) - trasy bez połączenia bezpośrednie (niepodłączone lokalnie), router nauczył się ich albo przy użyciu dynamicznych protokółów routingu lub zostały mu one zapisane ręcznie przez administratora (trasy statyczne)
- Trasa domyślna - trasa wykorzystywana w momencie, gdy nie ma innej pasującej do adresu docelowego.
Cechami tras statycznych są: potrzeba ręcznej konfiguracji, potrzeba ręcznego dostosowania do zmienającej się topologii sieci. Trasy statyczne mogą być dobrym wyborem dla małych sieci. Za pomocą tras statycznych mimo wykorzystywania protokołów dynamicznych ustala się bramy domyślne dla routerów.
W przypadku routingu dynamicznego, routery same odnajdują sieci, aktualizują informacje, wybierają najlepsze ścieżki czy dostosowują się do topologii. Dynamiczny routing może być wykorzystywany do współdzielnia statycznej trasy bramy domyślnej.
W systemach Cisco IOS, szczególnie na routerach możemy zobaczyć dość obszerną informacje podobną do tej przedstawionej na poniższym przykładzie. Nie będzie ona tak obszerna jak w tym przypadku. Nie mniej warto się jednak zapoznać z oznaczeniami poszczególnych tras.
route-views>show ip route
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
a - application route
+ - replicated route, % - next hop override, p - overrides from PfR
Gateway of last resort is 128.223.51.1 to network 0.0.0.0
S* 0.0.0.0/0 [1/0] via 128.223.51.1
1.0.0.0/8 is variably subnetted, 3781 subnets, 17 masks
B 1.0.0.0/24 [20/0] via 12.0.1.63, 12:59:24
B 1.0.4.0/22 [20/0] via 114.31.199.16, 12:59:24
B 1.0.5.0/24 [20/0] via 114.31.199.16, 12:59:24
...
Zatem:
- L - podłączony bezpośrednio adres IP interfejsu.
- C - sieć podłączona bezpośrednio.
- S - trasa statyczna.
- O - protokół OSFP.
- D - protokół EIGRP.
- R - protokół RIP.
- B - protokół BGP.
Chcąc przypasować te oznaczenia do wspomniany wcześniej rodzajów wpisów w tablicy routingu routera to:
- Podłączone bezpośrednio (ang. Directly Connected) - C i L.
- Trasy zdalne (ang. Remote Routes) - O, D, R B.
- Trasy domyślne (ang. Default routes) - S*.
Podsumowanie
Tym rozdziałem rozpoczeliśmy omawianie warstwy sieciowej. Poznaliśmy jej główny protokół jakim jest protokół IP oraz nagłówki pakietów zarówno dla wersji 4 jak i 6. Dowiedzieliśmy się jak działa trasowanie oraz jakie są jego rodzaje oraz charakterystyki metody statycznej oraz dynamicznej.
1.9. Rozwiązywanie adresów
Chcąc wysłać jakieś informacje przez sieć, nasz komputer musi w jakiś sposób zaadresować jakoś te pakiety z danymi. Pierwszą warstwą jaka będzie wymgać adresu jest warstwa sieciowa, tam potrzeba adresu IP, który może zostać uzyskany za pomocą system DNS. Następna warstwą jak wymaga adresu jest wartstwa fizyczna/łącza danych oraz rozpowszechniony na większość sieci protokół Ethernet, który wymaga adresów MAC (adresów fizycznych), kiedy pakiet IP jest enkapsulowany w ramkę Ethernet wymagana jest zamiana adresów IP na adresy MAC i temu służą dwa tematy tego rozdziału: ARP oraz IPv6 Neighbor Discovery.
Zadanie praktyczne - Packet Tracer
Identyfikacja adresów MAC i IP - scenariusz Identyfikacja adresów MAC i IP - zadanie
1.9.1. Protokół ARP
Protokół ARP jest wykorzystywany do określenia adresu MAC dla adresów IP lokalnych urządzeń w sieci. Protokół ten ma dwie zasadnicze funkcje zmianę adresów IPv4 na adresy MAC oraz utrzymania mapowań adresów w tabeli.
Kiedy host musi wysłać ramkę przeszukuje swoją tablicę ARP w poszukiwaniu pasującego adres MAC do docelowego adresu IPv4, jeśli host docelowy znajduej się w tej samej sieci. Jeśli znajduje się w innej wówczas host będzie szukać w tablicy ARP adresu bramy. Pasujący adres zostanie użyty jako adres docelowy w ramce Ethernet. Jeśli nie uda się odnaleźć adresu MAC, to wówczas host wyśle zapytanie ARP.
Wpisy w tabeli ARP znajdują się tam tylko przez określony czas, po jego upłynięciu wpis zostaje wymazany. Ilość tego czasu zależy od systemu operacyjnego, mimo to administrator ma możliwość ręcznego usunięcia wpisu z tablicy ARP.
Na urządzeniach z systemami IOS tablice ARP możemy sprawdzić za pomocą
polecenia: show ip arp. Na natomiast
w urządzeniach z system MS Windows tablice ARP możemy wyświetlić
za pomocą polecenia arp -a.
Pakiety ARP są przesyłane przez hosty nie mal przez wszystkie hosty w sieci, a wiele transmisji ARP na raz może powodować spadki wydajności całej sieci. Warto też wspomnieć, że odpowiedzi ARP mogą być fałszowane przez atakującego przeprowadzającego atak zatruwanie tablicy ARP, jednak przełączniki klasy Enterprise zawierają funkcję ochronne przed tego typu atakami.
Zadanie praktyczne - Packet Tracer
Badanie tablicy ARP - scenaiusz Badanie tablicy ARP - zadanie
1.9.2. Protokół IPv6 Neighbor Discovery
Protokół IPv6 Neighbor Discovery dostarcza nam takich funkcji jak rozwiązywanie adresów, znajdowanie routerów oraz usługi przekierowań. Cały ten protokół jest częścią protokołu ICMPv6 i wykorzystuje jego konkretne rodzaje komunikatów takie jak Neighbor Solicitation (NS) i Neigbor Advertisement (NA) wykorzystywane do wymiany informacji między urządzeniami, np. takich jak rozwiązywanie adresów. Innymi komunikatmi są Router Solicitation (RS) oraz Router Advertisement (RA) służące do wymiany informacji pomiędzy hosta a routerami te komunikaty biorą udział w zapytaniach o adres routera oraz o rozgłoszeniu informacji o istniejącym w sieci routerze. Pozostałymi komunikatami są informacje o przekierowaniach, są one używane przez routery do wyboru lepszego następnęgo skoku.
Wykorzystujące IPv6 urządzenia wykorzystują komunikaty ND w celu uzyskania adresów MAC dla znanych adresów IPv6. W odpowiedzi uzyskują adres MAC żądanego urządzenia, przyczym odpowiedzi wysyłane są na specjalny adres Ethernetowy oraz adres multikastowy IPv6.
Zadanie praktyczne - Packet Tracer
Wykrywanie sąsiadów IPv6 - scenariusz Wykrywanie sąsiadów IPv6 - zadanie
Podsumowanie
W tym jakże krótkim rodziale poznaliśmy w jaki sposób rozwiązywane są adresy IPv4 jak i IPv6 na adresy warstwy niższej - adresy MAC.
1.10. Podstawowa konfiguracja routera
Kontynuując poznawanie warstwy sieciowej pora poznać kilka poleceń, a ze względu, że to warstwa 3 czy to modelu OSI czy TCP/IP, to będzie to router - urządzenie, które w tej warswie poniękąd rezyduje.
1.10.1. Konfiguracja podstawowych ustawień routera
Prze rozpoczęciem właściwej konfiguracji interfejsów sieciowych czy routing warto pochylić się na takimi rzeczami jak określenie jego nazwy, wybór ewentualnej metody dostępu zdalnego do jego konsoli oraz zabepieczenie dostępu do niego hasłem. Zaczniemy od czynności, którą wykonuje się bardzo łatwo a może mieć dość duże znaczenie. Mianowicie od konfiguracji, nazwy urządzenia.
Do zmiany urządzenia służy polecenie hostname, polecenie to wydajemy w trybie globalnej konfiguracji:
Router(config)#hostname R1 R1(config)#
Następnym ważnym elementem jest zablokowanie możliwości przejścia w
tryb uprzywilejowany przez osoby do tego nieupoważnione, dokonujemy
tego za pomocą polecenia
enable secret hasło
w trybie konfiguracji globalnej:
R1(config)#enable secret 2up3r74jn3Has!0 R1(config)#
Teraz zabezpieczymy dostęp do trybu EXEC użytkownika, dokonamy tego
za pomocą kilku poleceń, na początku musimy przejść do konfiguracji
połączenia konsolowego, dokonujemy tego w trybie konfigracji globalnej
za pomocą poniższego polecenia:
line console 0, następnie ustawiamy
hasło dostępu za pomocą polecenia
password hasło oraz wymuszamy
logowanie za pomocą polecenia
login
R1(config)#line console 0 R1(config-line)#password 1234User! R1(config-line)#login R1(config-line)#end
Jeśli zabezpieczyliśmy konsole to warto zabezpieczyć, również dostęp
zdalny (na tym etapie, zrobimy to w podstawowym stopniu, w rozdziale
poświęconym bezpieczeństwu, zrobimy to tak jak należy). Konfigurację
rozpoczynamy od przejścia w trybie konfiguracji globalnej do trybu
konfiguracji konsoli wirtualnych, w tym poleceniu należy wskazać
również ile jest możliwych jednoczesnych połączeń, do konfiguracji
konsoli wirtualnych, przechodzimy za pomocą poniższego polecenia:
line vty 0 4, następnie identycznie
jak w przypadku połączenia konsolowego ustawiamy hasło:
password hasło oraz
wymuszamy logowanie: login
Dodatkowym polecenie jakie należy wydać jest wybranie protokołu
zdalnego dostępu, do dyspozycji mamy Telnet oraz SSH. Wybór
raczej jest prosty, a dokonujemy go za pomocą poniższego:
transport input ssh
R1(config)#line vty 0 4 R1(config-line)#password 1234User! R1(config-line)#login R1(config-line)#transport input ssh R1(config-line)#end
Odnośnie tej ilość jednoczesnych połączeń to odpowiadają za to te cyfry w pierwszym wierszu przykładu, w tym przypadku pozwoliśmy na 5 jednoczesnych połączeń.
Wpisane przez nas hasła za pomocą polecenia
password, są niestety przechowyane
czystym tekstem, jeśli wyświetlimy sobie obecną konfigurację. Jednak
za pomocą polecenia:
service password-encryption wydanego
w trybie konfiguracji globalnej możemy włączyć szyfrowanie haseł.
R1(config)#service password-encryption R1(config)#
Ostatnią czynnością, jaką należy wykonać na tym etapie jest
ustawienie informacji, tzw. baneru informującego o głównie o tym
nieautoryzowany dostęp jest zabroniony. Dokonać tego możemy za pomocą
polecenia: banner motd następnie
umieszczając między krzyżykami (#) rzeczoną
informacje. Polecenie to wydajemy w trybie konfiguracji globalnej.
R1(config)#banner motd # Nieautoryzowany dostep jest zabroniony! # R1(config)#
Teraz przed logowaniem każdy zobaczy taki napis i to nieważne czy
przez konsole czy SSH. Na chwile obecną konfiguracja naszego urządzenia
znajduje się w pamięci RAM. A wiemy jako to jest z pamięcią RAM, tak
więc aby zapisać nasza konfigurację do NVRAM-u. Musimy wydać poniższe
polecenie:
copy running-config startup-config
w trybie uprzywilejowanym EXEC.
R1(config)#end R1#copy running-config startup-config Destination filename [startup-config]? Building configuration... [OK] R1#
Zadanie praktyczne - Packet Tracer
Konfiguracja ustawień początkowych routera - scenariusz Konfiguracja ustawień początkowych routera - zadanie
1.10.2. Konfiguracja interfejsów i polecenia podgladu
Mając zapisaną początkową konfigurację routera w pamięci NVRAM możemy
przejść do konfiguracji interfejsów routera, na początku zanim jednak
skonfigurujemy jakiś interfejs musimy dowiedzieć się jakie są dostępne
na urządzeniu. Do tego może nam posłużyć polecenie:
show ip interface brief w trybie
uprzywilejowanym EXEC.
R1#show ip interface brief Interface IP-Address OK? Method Status Protocol FastEthernet0/0 unassigned YES unset administratively down down FastEthernet0/1 unassigned YES unset administratively down down Vlan1 unassigned YES unset administratively down down R1#
Przy okazji tego narzędzia warto wspomnieć dlaczego są dwie kolumny z
napisem administratively down oraz
down. Pierwsza kolumna
Status mówi nam jaki jest status
faktyczny interfejsu, jeśli wartość tego pola jest jak na przykładzie
oznacza to interfejs jest wyłączony przez administatora. W przypadku
kolumny Protocol oznacza, że protokół
warstwy niższej nie odpowiada - po drugiej stronie nic nie ma.
Więcej szczegółów na temat interfejsów możemy uzyskać za pomocą
polecenia:
show interfaces interfejs
R1#show interfaces FastEthernet0/0
FastEthernet0/0 is administratively down, line protocol is down (disabled)
Hardware is Lance, address is 0060.472c.e901 (bia 0060.472c.e901)
MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Full-duplex, 100Mb/s, media type is RJ45
ARP type: ARPA, ARP Timeout 04:00:00,
Last input 00:00:08, output 00:00:05, output hang never
Last clearing of "show interface" counters never
Input queue: 0/75/0 (size/max/drops); Total output drops: 0
Queueing strategy: fifo
Output queue :0/40 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
0 packets input, 0 bytes, 0 no buffer
Received 0 broadcasts, 0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort
0 input packets with dribble condition detected
0 packets output, 0 bytes, 0 underruns
0 output errors, 0 collisions, 1 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
--More--
Warto pamiętać o tym poleceniu, powieważ zwraca kilka przydatnych statystyk. Po odświerzeniu informacji, jak wyświetlać informacje o interfejsach, możemy przejść do ich konfiguracji. Konfiguracja nie będzie szczególnie różnić się od konfiguracja wirtualnego interfejsu Vlan1 znanego z konfiguracji przełącznika. Dodamy jedynie polecenie konfigurjące adres IPv6.
A więc jeśli chcemy skonfigurować dajmy na to interfejs
FastEthernet0/0
to w trybie konfiguracji globalnej wydajemy polecenie:
interface FastEthernet0/0, wówczas
nasz znak zachęty powinien pokazać nam, że zmieniliśmy tryb. Następnie
należy dodać opis dlatego interfejsu, za pomocą polecenia:
desc. Teraz możemy dodawać nasze
adresy IP, kolejno dla IPv4 poleceniem:
ip addr adres maska-dziesietnie
oraz dla IPv6 poleceniem:
ipv6 addr adres/prefix
na koniec podnosimy (uruchamiamy) ten interfejs poleceniem:
no shutdown.
R1(config)#interface FastEthernet0/0 R1(config-if)#desc WAN R1(config-if)#ip addr 209.165.200.225 255.255.255.252 R1(config-if)#ipv6 addr 2001:db8:acad:10::1/128 R1(config-if)#no shutdown R1(config-if)# %LINK-5-CHANGED: Interface FastEthernet0/0, changed state to up
Po wydaniu polecenia no shutdown,
otrzymaliśmy na konsoli informacje o tym, że interfejs się
uruchomił. Aby sprawdzić nasze ustawienia możemy wydać ponownie
polecenia show ip interface brief,
show ip interface FastEthernet0/0 oraz
dla IPv6
show ipv6 interface FastEthernet0/0.
R1(config-if)#end
R1#
R1#show ip interface brief
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 209.165.200.225 YES manual up down
FastEthernet0/1 unassigned YES unset administratively down down
Vlan1 unassigned YES unset administratively down down
R1#
R1#show interfaces FastEthernet0/0
FastEthernet0/0 is up, line protocol is down (disabled)
Hardware is Lance, address is 0060.472c.e901 (bia 0060.472c.e901)
Description: WAN
Internet address is 209.165.200.225/30
MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Full-duplex, 100Mb/s, media type is RJ45
ARP type: ARPA, ARP Timeout 04:00:00,
Last input 00:00:08, output 00:00:05, output hang never
Last clearing of "show interface" counters never
Input queue: 0/75/0 (size/max/drops); Total output drops: 0
Queueing strategy: fifo
Output queue :0/40 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
0 packets input, 0 bytes, 0 no buffer
Received 0 broadcasts, 0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort
0 input packets with dribble condition detected
0 packets output, 0 bytes, 0 underruns
0 output errors, 0 collisions, 1 interface resets
--More--
R1#
R1#show ipv6 interface FastEthernet0/0
FastEthernet0/0 is up, line protocol is down
IPv6 is tentative, link-local address is FE80::260:47FF:FE2C:E901 [TEN]
No Virtual link-local address(es):
Global unicast address(es):
2001:DB8:ACAD:10::1, subnet is 2001:DB8:ACAD:10::1/128 [TEN]
Joined group address(es):
FF02::1
MTU is 1500 bytes
ICMP error messages limited to one every 100 milliseconds
ICMP redirects are enabled
ICMP unreachables are sent
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds
Zanim przejdziemy dalej, warto omówić sobie oznaczenia interfejsów
w nomenklaturze Cisco, oprócz natywnego protokołu używanego przez ten
interfejs typu FastEthernet itd. mamy takie cyferki odzielone
ukośnikami FastEthernet0/0. W
urządzeniach Cisco można dodawać interfejsy na specjalnych kartach, te
karty umieszcza się w slotach urządzenia i ten slot
to może być jedna z cyfr. Następną cyfrą może być moduł, póki co do
głowy przychodzą mi tylko wkładki SFP, gdzie może być więcej modułów
w slocie, lub też moduł przełącznika może być podzielon na dwa
podmoduły - kiedy druga wartość może by inna niż 0. Ostatnią cyfrą
jest numer portu. Tak więc maksymalnie mogą być trzy cyfry w oznaczeniu
interfejsu np. GigabitEthernet0/1/0.
Innym przydatnym przydatnym poleceniem przy konfiguracji router może być wyświetlenie tablicy routingu za równo dla IPv4 jak IPv6.
R1#show ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static route
Gateway of last resort is not set
209.165.200.0/30 is subnetted, 1 subnets
C 209.165.200.224 is directly connected, FastEthernet0/0
R1#
R1#show ipv6 route
IPv6 Routing Table - 2 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
C 2001:DB8:ACAD:10::1/128 [0/0]
via ::, FastEthernet0/0
L FF00::/8 [0/0]
via ::, Null0
R1#
1.10.3. Konfiguracja bramy domyślnej na routerze
Kiedy wysyłamy pakiet do sieci, której nasz router nie obsługuje
wysyła on ten pakiet dalej do swojej bramy domyślnej. Identycznie
robią nasze domowe routery. Bez adresu bramy domyślnej dostęp do
Internetu byłby niemożliwy. Aby skonfigurować bramę na routerze Cisco
w trybie konfiguracji globalnej wydajemy polecenie:
ip default-gateway adres bramy
R1(config)#ip default-gateway 209.165.200.254 R1(config)#
Zadanie praktyczne - Packet Tracer
Podłączanie routera do sieci LAN Rozwiązywanie problemów z bramą domyślną - scenariusz Rozwiązywanie problemów z bramą domyślną - zadanie
Podsumowanie
W tym rozdziale poznalismy podstawową konfigurację routera Cisco w tym: początkowe ustawienia, konfigurację interfejsów oraz wyświetlenie ich stanu ze szczegółami i konfigurację domyślnej bramy.
Zadanie praktyczne - Packet Tracer
Podstawowa konfiguracja urządzenia - scenariusz Podstawowa konfiguracja urządzenia - zadanie
Laboratorium
Budowanie sieci w oparciu o przełącznik i router
1.11. Adresacja IPv4
Protokół IPv4 ten ma tyle lat, że chyba każdy powinien znać podstawy jego działania. Dla nas w tej wartstwie może i najważniejszą rzeczą jest adres IPv4 potocznie nazywany poprostu adresem IP. Adres ten jest unikalny i jednoznacznie wskazuje na hosta w sieci. W tym rozdziale zapoznamy się tym adresem i dowiemy się jak liczy się takie adresy oraz dzieli ich pulę na podsieci.
1.11.1. Struktura adresów IPv4
Adres IPv4 jest długości 32-bitów oraz ma hierarchiczną budowę, na którą składa się część sieciowa oraz część hostów. Przy określaniu tych części warto przyjrzeć się temu adresowi w postaci binarnej. Ważna również jest w tym przypadku maska podsieci.
Chcąc poznać poszczególne części adresu IP należy skonfrontować jego zapis binarny z maską, wówczas występujące na masce 1, oznaczają część sieciową, a 0 oznaczają część hosta. Taki proces nazywa się ANDing-iem.
Prefiksem możemy nazwać maskę zapisaną za pomoca liczby występującej na niej bitów o wartości 1. Taki prefiks zapisujemy za przy użyciu ukośnika (/, notacji ukośnika).
Adres sieci, czyli adres wskazujący na początek zakresu naszego adresów możemy uzyskać za pomocą przeprowadzenia logicznej operacji AND (mnożenia, mnożymy bity adresu IP hosta, przez bity maski.
192 . 168 . 10 . 10 1100 0000 | 1010 1000 | 0000 1010 | 0000 1010 255 . 255 . 255 . 0 1111 1111 | 1111 1111 | 1111 1111 | 0000 0000 ---------------------------------------------- AND 1100 0000 | 1010 1000 | 0000 1010 | 0000 0000 192 . 168 . 10 . 0
Na każdą sieci przypada przypadają adresy dwa adresy, których nie można użyć do adresowania hostów. Jeden z nich adres sieci poznalismy przed chwilą. Drugim jest adres broadcast, adres ten reprezentuje wszystkie hosty w danej podsieci, wskazuje on także koniec puli adresowej. W zapisie binarnym wyróznia się on tym, że w części hostowej ma on same jedynki.
1.11.2. Adresy IPv4 Unicast, Broadcast oraz Multicast
Adresem unikastowym IPv4 możemy nazwać dowolny adres hosta w sieci IP, w przypadku adresów unikastowych transmisja odbywa się od jednego nadawcy do jednego odbiorcy. Przy czym transmisja Broadcast polega na przesłaniu wiadomości z jednego źródła do wszystkich hostów w sieci Adres broadcast dla IPv4 jest 255.255.255.255. Transmisja może odbyć do wybranej grupy hostów, do tego służą adresy multikast, adresem, zarezerwowany do tworzenia grup multikastowych, jest zakres adresów od 224.0.0.0 do 239.255.255.255. Adresy te służą tylko temu celowi i nie powinny być wykorzystywane w innych celach.
1.11.3. Rodzaje adresów IPv4
Adresy IP można podzielić na publiczne, które mogą być trasowane pomiędzy różnymi sieciami łącząc je ze sobą. Są również adresy prywatne, które są wyłącznie do użytku wewnątrz sieci i nie są one routowalne. To za pomocą adresów prywatnych, adresujemy nasze hosty w sieci. Do dyspozycji mamy trzy klasy w zależności od wielkości naszej sieci.
- 10.0.0.0/8 - 10.0.0.0 - 10.255.255.255
- 172.16.0.0/12 - 172.16.0.0 - 172.31.255.255
- 192.168.0.0/16 - 192.168.0.0 - 192.168.255.255
Aby hosty zaadresowane adresami z klas prywatnych mogły uzyskać dostęp do internetu, potrzebna jest zamiana tych adresów na adresy publiczne. Za to odpowiada funkcja NAT - Network Address Translation. Ta funkcja najcześciej załączona jest na routerze brzegowym podłączonym do Internetu.
Protokół IP w wersji 4 wyróżnia kilka zakresów adresów specjalnych jednym z nich są adresy pętli zwrotnej - pozwalają na komunikację ze samym sobą oraz sprawdzenie poprawności działania stosu TCP/IP. Zakres tych adresów to 127.0.0.0/8 (127.0.0.1 - 127.255.255.254), zazwyczaj będziemy spotykać tylko jeden adres tego typu - 127.0.0.1. Drugą grupą są adresy typu Link-local, 169.254.0.0/16 (169.254.0.1 - 169.254.255.254), te adresy są wykorzystywane przez automatyczną adresację adresów IP prywatnych (tzw. APIPA), jest mechanizm pozwalający na adresowanie interfejsów sieciowych w przypadku gdy serwer DHCP jest niedostępny.
Cała przestrzeń adresowa IP w wersji 4 jest podzielona na klasy, które zawierają poszczególne zakresy adresów, zatem mamy:
- Klasa A (0.0.0.0/8 - 126.0.0.0/8)
- Klasa B (128.0.0.0/16 - 191.255.0.0/16)
- Klasa C (192.0.0.0/24 - 223.255.255.0/24)
- Klasa D (224.0.0.0 - 239.0.0.0)
- Klasa E (240.0.0.0 - 255.0.0.0)
Klasowy podział został zastąpiony poprzez adresowanie bezklasowe, przez co zakresy w klasach A, B i C mogą okazać się już nie aktualne.
Podziałem adresów IP zajmuje się organizacja IANA, podzieliła ona bloki adresów na 5 oddziałów regionalnych. Te oddziały regionalne są odpowiedzialne przydzielanie adresów do ISP oraz do innych organizacji. Za Polskę oraz Europę odpowiada organizacja RIPE ncc.
1.11.4. Segmentacja sieci
Wiele protokołów wykorzystuje transmisje broadkast oraz multikast. Przełączniki rozporowadzają transmisje broadkast na wszystkie swoje interfejsy po za tym, z którego ten ruch został otrzymany. Routery zatrzymuje te transmisje i nie propagują ich dalej. Routery dzielą sieci na domeny rozgłoszeniowe ograniczając wymienione wcześniej transmisje tylko do określonych domen.
Duże domeny rozgłoszeniowe mogą być problematyczne ponieważ wiele hostów, może generować wiele transmisji broadkastowych, co wpływa negatywnie na sieć. Rozwiązaniem tego problemu może być podzielenie duzych sieci na mniejsze podsieci z wykorzystaniem routerów.
Podział dużej sieci na mniejsze podsieci, obniża wielkość nadmiarowego ruchu i poprawia wydajnosć sieci. Pozwala na zastosowanie odbrębnych polityk bezpieczeństwa dla odrębnych podsieci. Podsieci zmniejszają liczbę urządzeń, które mogą generować dużo transmisji broadkast lub multikast.
1.11.5. Podsieci protokołu IPv4
Sieci IP jesteśmy w wstanie bez trudu podzielić na mniejsze podsieci wykorzystując do tego oktety. Adres IP ma długość 32-bitów i jest podzielony na 4 oktety, których zakres jest od 0 do 255. W postaci binarnej te wartości można zapisać za pomocą 8 bitów. W zależności od tego jak dużej sieci potrzebujemy możem przesuwać tę granicę między częścią sieciowa a częścią hostową w lewo lub w prawo. Nieznając innych metod najprościej jest przesunąć tę granicę o całe 8-bitów. Przez co możemy podzielić taki zakres adresów IP: 172.16.0.0/16 na 256 podsieci po 254 hosty. Przesuwając maskę o 8 bitów w prawo.
172.16.0.0/16: 1. /24 172.16.0.0 - 172.16.0.255: 172.16.0.1 - 172.16.0.254 2. /24 172.16.1.0 - 172.16.1.255: 172.16.1.1 - 172.16.1.254 3. /24 172.16.2.0 - 172.16.2.255: 172.16.2.1 - 172.16.2.254 4. /24 172.16.3.0 - 172.16.3.255: 172.16.3.1 - 172.16.3.254 5. /24 172.16.4.0 - 172.16.4.255: 172.16.4.1 - 172.16.4.254 6. /24 172.16.5.0 - 172.16.5.255: 172.16.5.1 - 172.16.5.254 ...
Oczywiście sieć z maską 24-bitową, można dzielić dalej, aby jak najlepiej wykorzystać ilość przydzielonych nam adresów. Dzieląc tą podsieć na mniejsze fragmenty. Poniżej znajdują się table, które mogą pomóc nam podzielić czy to sieci 24-bitową czy 16.

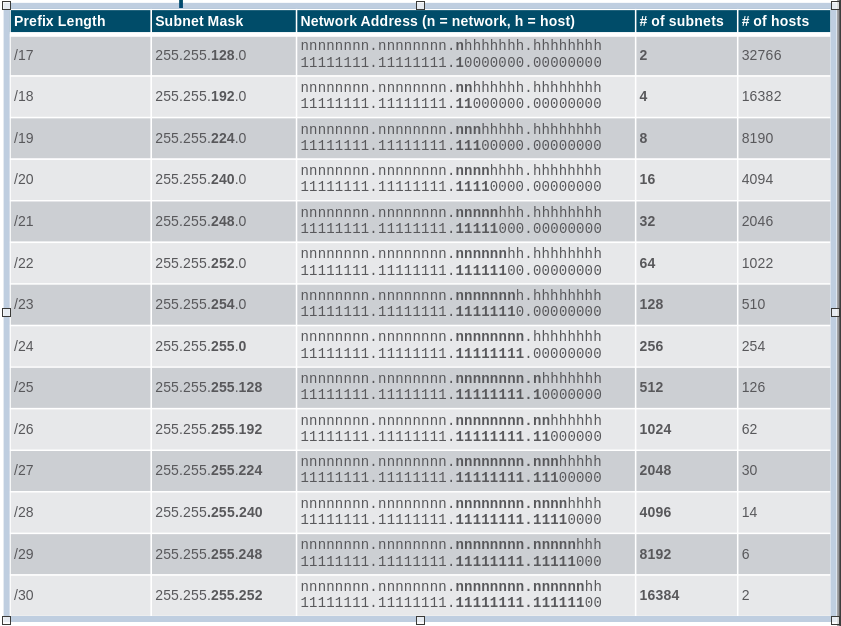
Przy podziale podsieci, niekoniecznie o całe 8 bitów, warto sobie wziąć pod uwagę zasadę, że ile bitów zabieramy (przekazujemy je na część sieciową) - X to mamy 2^X podsieci. Jeśli mamy ilość podsieci to należy podzielić ilość hostów z wyjściowej klasy przez ilość podsieci. Te rozważania mogą nam być potrzebne do rozważań na temat adresacji oraz w przypadku VLSM.
Zadanie praktyczne - Packet Tracer
Podział sieci IPv4 na podsieci - scenariusz Podział sieci IPv4 na podsieci - zadanie
1.11.7. Podział na podsieci a wymagania
W przedsiębiorstwach możemy spotkać różne wymagania. Jednym z nich może być to że firma posiada dwie podsieci, jedna z nich jest siecią lokalną natomast druga to DMZ (wydzielona sieć dla serwerów, w tej sieci urządzenia mogą wykorzystywać adresy publiczne). To wówczas dla tej sieci lokalnej możemy wykorzystać pule adresów prywatnych a DMZ, niech korzysta z adresów publicznych.
Sprawa zaczyna się komplikować, gdy dostajemy już jakieś wytyczne. Posiadamy klasę adresów 172.16.0.0/22, co daje 1022 hosty. Firma posiada 5 lokalizacji, każda z nich ma mieć dostep do Internetu. Największa sieć w tych pięciu lokalizacji będzie miała nie więcej niż 40 hostów. Potrzebne jest zatem 10 podsieci, o wielkości nie mniejszej niż 40 hostów, dla naszych potrzeb wystarczy maska o długości 26-bitów da to po 62 hosty na sieć, a na każdą z lokalizacji będziemy co najmniej dwie podsieci. Jedna podsieci będzie adresować hosty natomiast druga połaczenie do ISP. Mamy zatem
Lokalizacja 1: Do ISP: 172.16.0.0/26 LAN: 172.16.0.64/26 Lokalizacja 2: Do ISP: 172.16.0.128/26 LAN: 172.16.0.192/26 #Tutaj wyczerpują się 254 hosty dla 172.16.0, dlatego trzeba przejść o jeden #dalej na 172.16.1. Lokalizacja 3: Do ISP: 172.16.1.0/26 LAN: 172.16.1.64/26 Lokalizacja 4: Do ISP: 172.16.1.128/26 LAN: 172.16.1.192/26 Lokalizacja 5: Do ISP: 172.16.2.0/26 LAN: 172.16.2.64/26
Wmiarę prosty sposób połączyliśmy te lokalizacje, tylko jest jednen mały szczegół. Trochę szkoda adresów na połączenie do ISP, 62 adresy na połaczenie dwóch hostów.
Laboratorium
1.11.7. VLSM
W podanej topologii wymagane jest 7 podsieci (cztery LAN-y oraz 3 WAN-y), Największą siecią jest sieć w budynku D ma 28 hostów. Do tego celu wybieramy maskę /27, ona da 8 podsieci po 30 hostów IP. Jednak w ogólnym rozrachunku, zmarnujemy 84 adresy. Tak więc tradycjne podejście nie jest zbyt wydajne. Rozwiązaniem może być VLSM, który pozwoli nam na podział już podzielonej podsieci. Dzięki VLSM możemy dla tych trzech WAN-ów zastosować maskę /30, co da nam tylko dwa hosty w tej podsieci, reszta pozostanie do wykorzystania. Takie krótkie sieci warto wydzielać od końca, np. żeby adres broadcast całej puli był np. adresem broadcast tej podsieci i te mniejsze wydzielać, kolejno cofając się po puli.
1.11.8. Projekt strukturalny
Planowanie sieci IP jest istotnym elementem opracowywania skalowalnego rozwiązania dla sieci przedsiębiorstwa. W celu określenia schematu adresacji musimy zdobyć wiedzę na temat tego ile potrzebujemy podsieci oraz określenie ilości hostów w każdej z nich. Trzeba równiez przestudiować zapotrzebowanie na ruch sieciowych organizacji oraz określić w jaki sposób te podsieci będą mieć strukturę. Trzeba pod uwagę wziąć segmentaryzacje sieci oraz zapotrzebowanie na adresy IP dla różnych urządzeń (jak np. serwery lub urządzenia sieciowe) oraz pule VLAN-ów.
Zadanie praktyczne - Packet Tracer
Praktyka projektowania i wdrażania VLSM - scenariusz Praktyka projektowania i wdrażania VLSM - zadanie
Podsumowanie
W tym rozdziale poznaliśmy strukturę adresów IP, ich rodzaje oraz czym jest broadcast, unicast oraz multicast. Poznaliśmy zakresy adresów publicznych, prywatnych oraz tych specjalnych. Dowiedzieliśmy się jakie dzielić domeny rozgłoszeniowe oraz zakresy adresów IP na podsieci. Na koniec nauczyliśmy się jak korzystać VLSM, aby oszczędzać adresy podczas podziału.
Zadanie praktyczne - Packet Tracer
Projektowanie i stosowanie adresacji VLSM - scenariusz Projektowanie i stosowanie adresacji VLSM - zadanie
Laboratorium
Projektowanie i wdrażanie schematu adresacji VLSM
1.12. Adresacja IPv6
Obecnie sieci komputerowe opierają się na podwójnym stosie. Nasze komputery są konfigurowane zarówno przy użyciu IPv4 oraz IPv6. IPv6 nie jest nowym wynalazkiem, ma już kilka lat. Jedną z przeszkód dlaczego używamy IPv4 zamiast IPv6 jest fakt, że protokół IP ma już coś około 40 lat. Pakiet mknąc przez przestrzeń może napotkać naprawdę różny sprzęt i dostosowanie się usługodawców internetowych do IPv6 jest tak główną przeszkodą do odejścia od IPv4 i zmiany głównego protkołu internetowego. W tym rozdziale spróbujemy przybliżyć sobie jak wygląda adresacja IPv6. Odpowiemy również na pytanie czy ja muszę rzeczywiście pisać te wszystkie cyfry?
1.12.1. Problemy IPv4
Adresy IPv4 są nawyczerpaniu. IPv6 jest następcą IPv4. IPv6 ma o wiele większą przestrzeń adresową niż IPv4. Implementacja IPv6 posiada wiele ulepszeń i znosi wiele ograniczeń IPv4. Pula adresowa przeznaczona dla krajów europejskich wyczerpała się we wrześniu 2012 roku. Wszystkie obecnie nowoprzydzielane pule są zaporzyczeniami z puli przeznaczonej dla kontynentu afrykańskiego.
Organizacja IETF stworzyła wiele protokołów oraz narzędzi mających pomóc administratorom w migracji ich sieci na IPv6. Opracowane techniki migracji można opisać za pomocą trzech kategorii:
- Podwójny stos - urządzenie używają obu stosów jednocześniej.
- Tunelowanie - metoda przenoszenia pakietów IPv6 przez sieć IPv4. Pakiet IPv6 jest enkasulowany w pakiecie IPv4.
- Translacja - mechnizm NAT64 (taki NAT tylko dla IPv6) pozwala na komunikowanie się urządzeń używających IPv6 z urządzeniami korzystającymi z IPv4.
Warto dodać, że tunelowanie powinno być wykorzystywane tylko tam gdzie jest to niezbędne. Naszym celem powinno być zapewnienie domyślnej komunikacji z pośrednictwem protokołu IPv6.
1.12.2. Reprezentacja IPv6
Adres IPv6 mają długość 128-bitów, zapisywane są za pomocą liczb
systemu heksadecymalnego (szesnastkowego). Zapis adresu nie jest
wrażliwy na wielkość znaków, cyfry reprezentujące liczby od 10 (A) do
15 (F), można zapisać małymi lub wielkimi literami. Preferowanym
formatem zapisu jest x:x:x:x:x:x:x:x,
gdzie każdy x jest czterema cyframi
heksadecymalnymi, jeden taki x jest również nazywany
nieoficjalnie hekstetem. Poniżej znajdują się przykładowe
adresu IPv6.
2001:0db8:0000:1111:0000:0000:0000:0200 2001:0db8:0000:00a3:abcd:0000:0000:1234
Powyższy zapis jest niewygodny, wymaga więcej czasu na jego zapisanie na stacji roboczej. Dlatego też wymyślono dwie zasady za pomocą, których możemy skracać zapis tego typu adresów. Zasady operają się na cyfrze 0. Pierwszą z nich jest ponięcie wiodącego zera
Zatem jeśli mamy na początku hekstetu cyfrę 0, to możemy ją pominąć, a hosty same ją poźniej uzupełnią, tak aby każdy hekstet mam 4 znaki. Po zastosowaniu tej metody powyższe przykłady wygłądały by nastepująco.
2001:db8:0:1111:0:0:0:200 2001:db8:0:a3:abcd:0:0:1234
Zapis jest już krótszy i w pełni poprawny. Drugą zasadą jest wykorzystanie podwójnego dwukropka (::). Ta zasada mówi, że możemy zastąpić następujące po sobie hekstety zer, podwójnym dwukropkiem. Ta zasada ma jednak ograniczenia, otóż może zostać w jednym adresie użyta tylko raz. Tak więc nasze adresy możemy zapisać
2001:db8:0:1111::200 2001:db8:0:a3:abcd::1234 #lub jeśli zmodyfikujemy 4 hekstet z 00a3 na 0000, to wówczas taki adres #możemy zapisać tak: 2001:db8:0:0:abcd::1234 #albo 2001:db8::abcd:0:0:1234
1.12.3 Typy adresów IPv6
Istnieją trzy kategorie adresów IPv6, są to m. in.:
- Unicast - adres unikalny dla każdego hosta używającego IPv6.
- Multicast - adres wykorzystywany do wysłania jednego pakietu IPv6 do wielu urządzeń.
- Anycast - dowolny unikastowy adres IPv6, który może być przypisany do wielu urządzeń. Pakiet wysłany pakiet na ten adres zostanie przekierowany do urządzeń, które go posiadają.
W przeciwieństwie do IPv4 w IPv6 nie ma czegoś takiego jak adres broadcast, jednak że istnie adres multikastowy kierowanych do wszystkich hostów, co w rezultacie daje takie same efekty.
Prefiks oraz jego długość wykorzystywane są do wskazywania sieciowej części adresu IPv6. Przedstawiany jest jak maska IPv4 w notacji CIDR. Prefiks może mieć długośc od 0 do 128. Jednak rekomendowaną długością prefiksu dla sieci LAN oraz innych są 64-bity (/64). Jest to wręcz standard, ze względu na ty, że metoda SLAAC (będzie opisana poźniej), wykorzystuje pozostałe 64-bity na identyfikator interfejsu użytkownika. Użycie takie prefiksu, łatwia podział na podsieci oraz poźniejsze nimi zarządzanie.
W przeciwieństwie do IPv4, urządzenia korzystające z IPv6 mają po dwa adresy przypisane do interfejsów. Pierwszym z nich jest Global Unicast Address (GUA) - adres ten jest podobny do publicznego adresu IPv4, jest unikalny w skali świata oraz osiągalny z Internetu. Drugim adresem jest Link-local Address (LLA) - jest on wymagany przez wszystkie urządzenia, które korzystają z IPv6 i sa wykorzystywane do komunikacji tylko w sieci lokalnej przez co są nie routowalne.
IPv6 posiada unikalne adresy lokalne (zakres od fc00::/7 do fdff::/7), (Unique Local Adress) które posiadają pewne podobnieństwa do adresów prywatnych IPv4, ale również istnieje znaczące różnice. Tego rodzaju adresy sa używane do adresacji wewnątrz organizacji lub pomiędzy ograniczoną ich liczbą. Urządzenia wykorzystujące te adresy nigdy nie będą mieć dostępu do innych sieci za ich pośrednictwem. Unikalne adresy lokalne nie są ani routowalne, ani zamieniane na adresy globalne IPv6.
Niektóre organizacje korzystały sieci prywatnych IPv4, aby ukryć swoje sieci przed zagrożeniami z Internetu, jednak to nigdy nie było motywacją do stoswania adresów ULA w IPv6.
Adresami unikastowmi o zasiągu globalnym są tzw. adresy Global Unicasts Address - GUA. Tego typu adresy są swojego rodzaju adresy publiczne osiagne z Internetu. Obecnie przypisane są tylko adresy GUA rozpoczynające sie od 2000::/3, przydzielone (zarezerowane) zostały tylko trzy bity. Przy tych trzech bitach można rozpisać tylko 2 cyfry 2 oraz 3. Zatem obecny zakres GUA rozpoczyna się od 2000 a kończy 3fff.
Adresy GUA posiadają określoną strukturę. Składa się on z globalnego prefiksu routing, który może być prefiksem, siecią lub pulą adresów. Ten prefiks routingu jest przydzielny organizcjom lub klientom przez ISP. Następną cześcią adresu jest identyfikator podsieci, znajduje się między globalnym prefiksem a identyfikatorem interfejsu. Identyfikator podsieci wykorzystywany identyfikacji podsieci wewnątrz organizacji. Ostatnią cześcią adresu jest identyfikator interfejsu, jest to część adresu odpowiedzialna za identyfikację hosta. Identyfikator hosta ma długość 64-bitów, dlatego też rekomendowane jest aby stosować 64-bitowe prefiksy.
IPv6 pozwala na przypisanie hostom adresów składajacych się z samych 0 lub z samych 1, jednakże adres składajacy się z samych 0 jest zarezwowany jako adres anycast Subnet-Router i powinnien być przypisany tylko do routera.
Ostatnim typem adresu IPv6 jest Link-local address - LLA.
Ten pozwala na komunikację wewnątrz tej samej podsieci. Pakiet
zaadresowane przez LLA nie są routowalne. Każdy interfejs sieciowy
działający przy użyciu IPv6 musi mieć skonfigurowane LLA, jesli nie
jest przypisane, urządzenie przypisze je sobie samo, automatycznie.
Prefiksem dla adresów LLA jest
fe80::/10
1.12.4. Statyczna konfiguracj GUA oraz LLa
Chcąc skonfigurować ręcznie adres IPv6 GUA, w systemie IOS po przejściu do konfiguracji wybranego intefejsu wydajemy poniższe polecenie:
Router(config-if)# ipv6 address 2001:db8:acad:1::1/64
Następnie podnośimy interfejs za pomocą polecnia
no shutdown. Gotowe.
W przypadku konfiguracji stacji roboczych, to konfiguracja wygląda podobnie do konfiguracji IPv4, tylko zamiast "Protokoł Internetowy w wersji 4" wybieramy "Protokoł Internetowy w wersji 6". Jeśli podajemy adres bramy, to najlepszą praktyką jest ustawienie adresu LLA routera.
Konfigurując LLA na jednym z interfejsów w systemie IOS korzystamy z tego samego polecenia. Nie podajemy przy tego rodzaju adresie prefiksu. To specjalny adres, który go nie wymaga. Dodajemy również specjalne słowo kluczowe: link-local.
Router(config-if)# ipv6 address fe80::1:1 link-local
Konfigurując LLA dla każdego z interfejsów routera warto pamiętać o tym aby były one unikalne (wymagane jest aby były unikalne w obrębie jednej podsieci).
1.12.5. Dynamiczne adresowanie GUA w IPv6
Urządzenia mogą uzyskąć adres GUA dynamicznie wykorzystując do tego komunikaty ICMP w wersji 6. Host może wysłać zapytanie o router (komunikat RS Router Solicitation). W informacji zwrotnej w postaci (komunikatu RA Router Advertisment) od routera, host dowiaduje się w jaki sposób może uzyskać GUA oraz otrzymuje kilka dodatkowych informacji takich jak:
- Prefix sieci oraz jego długość.
- Adres domyślnej bramy.
- Adresy DNS oraz nazwę domenowa.
Komunikat RA dostarcza trzy metody dla konfiguracji GUA:
- SLAAC
- SLAAC z bezstanowym serwerem DHCPv6
- Stanowy serwer DHCPv6 (bez SLAAC)
Metoda SLAAC pozwala na skonfigurowanie GUA bez usługi DHCPv6. Urządzenia uzyskują informacje do konfiguracji GUA z komunikatów RA protokołu ICMP. Prefix również znajdujący się w komunikatach RA jest również używany do generowania identyfikatora interfejsu czy to w przypadku metody EUI-64 lub metody losowej.
W przypadku metody SLAAC i bezstanowego serwera DHCPv6, komunikat RA instruuje klientów aby wykorzystali mechnizm SLAAC to utworzenia GUA. LLA routera, które jest adresem źródłowym pakiety RA zostaje zapisany jako adres bramy. Używa się bezstanowego serwera DHCPv6 do uzyskania takich informacji jak adres DNS oraz nazwę domenową.
Ostatnią metodą jest poinstruowanie przez pakiet RA do użycia stanowego serwera DHCPv6. Stanowe DHCPv6 jest podobne do DHCP dla IPv4. Urządzenie automatycznie otrzymuje GUA, długość prefiksu oraz adresy serwerów DNS z serwera DHCPv6. Komunikat RA sugeruje aby urządzenia użyły adresu źródłowego komunikatu RA, którym jest LLA jako adresu bramy oraz serwera DHCPv6 do uzyskania innych informacji
Nie zależnie czy w RA będzie sugerowane SLAAC czy SLAAC z uzyciem bezstanowego DHCPv6, klient musi wygenerować identyfikator interfejsu. Taki identyfikator jest tworzony za pomocą metody EUI-64 lub za pomocą wygenerowanych losowo 64-bit liczb.
Instytucja IEEE określa EUI (Extended Unique Identifier) lub jego zmodyfikowaną wersję EUI-64, która polega na utworzeniu identyfikatora umieszczając 16-bitową wartość heksadecymalną fffe w środku adresu MAC interfejsu, korzystającego z tej metody, oraz odwróceniu w siódmego bitu adresu MAC z wartości binarnej 0 na 1.
Alternatywną metodą jest wygenerowanie 64-bitów liczb heksadecymalnych zamiast generowania identyfikatora za pomocą metody EUI-64. Tak dzieje się w wszystkich współczesnych systemach MS Windows.
Aby zapewnić unikalnosć adresów, hosty mogą użyć mechanizmu DAD (Duplicate Address Detection). Jest to podobne do protokołu ARP, żądanie o swój adres. Jeśli odpowiedź nie nadejdzie to oznacza, że adres jest unikatowy.
1.12.6. Dynamiczna adresacja LLA w IPv6
Wszystkie interfejsy IPv6 muszą mieć przypisane LLA (Link-local Address). Podobnie do GUA, LLA może zostać przypisane dynamicznie. Jak pamiętamy LLA składa się z prefiksu fe80::/10, pozostałe bity są dopełniane zerami. Następnie występuje identyfikator interfejsu (zazwyczaj jest 64-bity liczb heksadecylmanych).
Systemy operacyjne z rodziny Windows do konfiguracji IPv6 domyślnie wykorzysują utworzone przez SLAAC GUA oraz dynamicznie przydzielone LLA. W przypadku systemów IOS LLA jest generowane nawet wtedy gdy adres GUA nie jest skonfigurowany. Adres LLA w systemach firmy Cisco jest generowany przy użyciu EUI-64.
Zadanie praktyczne - Packet Tracer
Konfiguracja adresacji IPv6 - scenariusz Konfiguracja adresacji IPv6 - zadanie
1.12.7. Adresy typu multicast IPv6
Multikastowe adresy IPv6 posiadają prefiks ff00::/8. Istnieją dwa rodzaje adresów multikastowych:
- adres multikastowy Well-Known,
- adres multikastowy Solicited-node.
Warto zwrócić na to uwagę, że adresy multikastowe mogą być jedynie używane jako adresy docelowe, a nie źródłowe.
Adresy Well-known są adresami już przypisanymi i zarezerowanymi dla predefiniowanych grup urządzeń. Istnieje dwie powszechne grupy przypisanych adresów multikastowych:
- ff02::1 grupa multikastowa All-nodes - Jest grupa, do której należą wszysktie hosty korzystające z IPv6. Pakiet wysłany do tej grupy zostanie odebrany i przetworzony przez wszystkie interfejsy w sieci
- ff02::2 grupa multikastowa All-routers -
Grupa wszystkich routerów obsługujących routing unikastowy w dla IPv6
(router, żeby mógł dołączyć do tej grupy musi być skonfigurowany
poprze wydanie poniższego polecenia):
Router(config)# ipv6 unicast-routing
Adres multikastowy dla solicited-node jest podobny do adresu all-nodes. Adres solicited-node jest mapowany do specjalnego adresu multikastowego Ethernet. Przez to karty sieci Ethernet są wstanie odfiltrować taki pakiet sprawdzając adres docelowy zanim trafi do przetwarzania przez IPv6 w celu ustalenia czy host, do którego ten pakiet trafił jest hostem dla niego docelowym.
Laboratorium
1.12.8. Podsieci protokołu IPv6
Protokół IPv6 posiada już zaprojektowaną możliwość podziału większych sieci na podsieci. Adres GUA posiada wydzielone pole na identyfikator podsieci (subnet ID) wykorzystywane przy tworzeniu podsieci. Identyfikator podsieci znajduje się między globalnym prefiksem routingu, a identyfikatorem interfejsu.
Załóżmy, że otrzymaliśmy globalny prefiks routingu o wartości:
2001:db8:acad::/48, wraz 16-bitami
identyfikatora podsieci to daje nam 65,535 podsieci. Globalny prefiks
pozostaje dla wszystkich tych podsieci, inkrementacji natomiast będzie
ulegać jedynie kolejny po nim hekstet.
2001:db8:acad:0000::/64 2001:db8:acad:0001::/64 2001:db8:acad:0002::/64 2001:db8:acad:0003::/64 2001:db8:acad:0004::/64 2001:db8:acad:0005::/64 2001:db8:acad:0006::/64 2001:db8:acad:0007::/64 2001:db8:acad:0008::/64 2001:db8:acad:0009::/64 2001:db8:acad:000a::/64 2001:db8:acad:000b::/64 2001:db8:acad:000c::/64 ... 2001:db8:acad:ffff::/64
Posieciami IPv6 w praktyce operujemy tak samo jak w przypadku podsieci IPv4. Dla każde z nich potrzebujemy osobnego interfejsu na routerze.
Zadanie praktyczne - Packet Tracer
Implementacja schematu adresowania podsieci IPv6 - scenariusz Implementacja schematu adresowania podsieci IPv6 - zadanie
Posumowanie
W tym rodziale zostaliśmy zaznajomieni z protokołe IPv6 zobaczyliśmy jak wygląda taki adres IPv6 i w jaki sposób można go zapisać. Poznaliśmy rodzaje adresów tego protokołu oraz nauczyliśmy się konfigurować statyczne adresy GUA oraz LLA. Przedstawiono nam techiniki dynamicznego uzyskiwania adresu GUA oraz LLA. Na koniec dowiedziliśmy się jakie są adresy multikastowe dla IPv6 oraz zapoznaliśmy się z podziełem sieci IPv6 na podsieci.
Laboratorium
Konfiguracja adresów IPv6 urządzeń sieciowych
1.13. Protokół ICMP
Protokół ICMP jest protokołem diagnostyczno-kontrolnym, wspomagający protokoł IP. Przez użytkowników może zostać wykorzystany do sprawdzenia połączenia z siecią oraz weryfikacji trasy wysyłanych pakietów.
1.13.1. Komunikaty protokołu ICMP
Protokoł ICMP dostarcza informacji o problemach związanych z przetwarzaniem pakietów IP w określonych warunkach.
ICMP w wersji 4 posiada głównie funkcjonalność sygnalizacyjną na IPv4. Natomast w przypadku IPv6 funkcjonalność protokołu ICMPv6 rozszerzono o dodatkowe role.
Oczywiśćie ICMP dla IPv6 dalej pozostaje protokołem sygnalizacyjnym. Obie wersje protokółu wspierają podstawowe komunikaty takie jak:
- Osiągalność hosta
- Nieosiągalność celu lub usług
- Wyczerpanie czasu
Warto zaznaczyć, że nie ze wszystkich sieci otrzymamy odpowiedź, ponieważ w wielu z nich protokół ICMP jest blokowany przy użyciu zapory, ze względów bezpieczeństwa.
Do badania osiągalności hosta, można wykorzystać komunikat ICMP Echo. Jeden z hostów wysyła do drugiego żądanie Echo (request), jeśli ten drugi host jest osiągalny to odpowie przy użyciu komunikatu odpowiedzi Echo (reply)
W przypadku mierzenia osiagalności celów oraz usług sprawa trochę bardziej skomplikowana. Komunikat ICMP może zawierać specjalny kod, który wskaże nam dlaczego pakiety nie mogą dotrzeć.
Dla IPv4 są to kolejno:
- 0 - sieć jest nieosiągalna
- 1 - host jest nieosiągalny
- 2 - protokół jest nieosiągalny
- 3 - port jest nieosiągalny
Natomiast dla IPv6 są to kolejno:
- 0 - brak trasy do celu
- 1 - komunikacja z celem została zablokowana przez administratora (np. na komunikację nie pozwala firewall)
- 2 - poza zakresem adresu źródłowego
- 3 - adres nieosiągalny
- 4 - port nieosiągalny
Innym rodzajem komunikatu jest upłynięcie czasu. Jak możemy pamiętać z budowy nagłówka pakietu IPv4, to zawiera on pole TTL, każde przejście pakietu przez router obniża tą wartość o 1, aż do jej wyzerowania. W momecie wyzerowania pola TTL, dla np. naszego żądania Echo, możemy otrzymać komunikat o tym, że pole TTL zostało wyzerowane w trakcie przesyłu pakietu
Protokół ICMP dla IPv6 został zaktualizowany, a jego funkcjonalność została rozszerzona na 4 nowe rodzaje komunikatów jako część protokołu Neighbor Discover Protocol.
Nowe komunikaty dzielą się na wymieniane między hostem a routerem, to jest:
- Zapytanie o router - Router Solicitation (RS)
- Ogłaszanie się routera - Router Advertisement (RA)
Jak i na te wymienie między hostami, to jest:
- Zgłoszenie się hosta - Neighbor Solicitation (NS)
- Ogłoszenie się hosta - Neighbor Advertisement (NA)
ICMPv6 zawiera jeszcze inne komunikaty, ale są one np. podobne do komunikatu przekierowania (redirect) wykorzystywanego IPv4.
Komunikaty RA w IPv6 są wysyłane przez router co 200 sekund, aby dostarczyć informacje do wszystkich obsługujących IPv6 urządzeń. Poza adresami routera przekazywany jest prefix i jego długość, adresy DNS czy nazwa domenowa. Komunikaty RA są wykorzystywane do konfiguracji bramy domyślnej dla hostów, które są ustawione na samodzielną konfigurację.
Routery odpowiedzą za pomocą komunikatu RA na otrzymany komunikat RS. Hosty wysyłają RS w celu określenia informacji na temat adresacji protokołu IPv6.
Urządzenia, które mają skonfigurowane IPv6 pod GUA lub Local-Link, mogą używać mechanizmu DAD (Duplicate Adress Detection) w celu upewnienia się o unikalności adresu. W celu sprawdzenia unikalności swojego adresu host wysyła komunikat NS, ustawiając swój adres jako adres docelowy. Jeśli jeden z hostów będzie mieć taki adres, wówczas odpowie na tem pakiet komunikatem (NA).
W przypadku IPv6 protokół ICMP w wersji 6, przejął rozwiązywanie adresów IP na adresy MAC. Host, który potrzebuje adresu MAC innego hosta wysła do niego komunikat NS. W odpowiedzi host odpowiada komunikatem NA zawierającym adres MAC stacji, która go wysłała.
1.13.2. Testy ping oraz traceroute
Polecenie ping jest narzędziem testowym zarówno dla IPv4 i IPv6. Polega ono na wysłaniu kilku komunikatów echo requests i oczekiwaniu na echo reply wyswietlając każdą odpowiedź. Na koniec zwracane jest podsumowanie zawierające m. in. uśredniony czas wszystkich odpowiedzi. Polecenia ping mogą wyglądać różnie w zależności od systemu.
#MS Windows:
C:\Users\xf0r3m\Desktop>ping 192.168.8.1
Pinging 192.168.8.1 with 32 bytes of data:
Reply from 192.168.8.1: bytes=32 time<1ms TTL=64
Reply from 192.168.8.1: bytes=32 time<1ms TTL=64
Reply from 192.168.8.1: bytes=32 time<1ms TTL=64
Reply from 192.168.8.1: bytes=32 time<1ms TTL=64
Ping statistics for 192.168.8.1:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 0ms, Average = 0ms
#Dystrybucja Linuksa - immudex:
xf0r3m@laptop-45f33b2/ ~/ ping 192.168.8.1
PING 192.168.8.1 (192.168.8.1) 56(84) bytes of data.
64 bytes from 192.168.8.1: icmp_seq=1 ttl=64 time=0.591 ms
64 bytes from 192.168.8.1: icmp_seq=2 ttl=64 time=0.643 ms
64 bytes from 192.168.8.1: icmp_seq=3 ttl=64 time=0.524 ms
64 bytes from 192.168.8.1: icmp_seq=4 ttl=64 time=0.793 ms
^C
--- 192.168.8.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3078ms
rtt min/avg/max/mdev = 0.524/0.637/0.793/0.099 ms
#Cisco IOS - przełącznik (ver. 15.2):
Switch#ping 192.168.8.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.8.1, timeout is 2 seconds:
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 0/0/0 ms
Polecenie ping możemy zastosować kilku scenariuszach aby uzyskać kilka
odpowiedzi. Jeśli chcemy sprawdzić czy nasz stos sieciowy działa
poprawnie możemy zpingować swój adres pętli zwrotnej:
ping 127.0.0.1. Pozytywna odpowiedź
oznacza, że nasz host może funkcjonować we wszystkich współczesnych
sieciach. Drugim testem jaki możemy wykonać jest ping na adres bramy
domyślnej, pozwoli nam to ustalić czy nasz konfiguracja IP jest
prawidłowa. Szczególnie przydatne, gdy konfigurowaliśmy nasz interfejs
ręcznie
bez użycia serwera DHCP. Jeśli odpowiedź na ten test będzie pozytywna
to oznacza, to że nasz host ma możliwość komunikacji w sieci, do
której jest podpięty. Ostatnim trzecim testem jest sprawdzenie
dostępności jakiegoś hosta w Internecie lub w drugiej sieci. Takie
działania może mieć na celu upewnienie się, że mamy dostęp Internetu
oraz, że nasz router jest skonfigurowany jeśli obsługuje on więcej niż
dwie sieci.
Innym z narzędzi pozwalających nam testować możliwości połączenia. Jest traceroute w systematch takich jak Windows może nosić nazwę tracert. Nie koniecznie może być przedatne zwykłym użytkownikom, ale jeśli administrator ma kilka routerów, to za pomocą tego narzędzia sprawdzić możliwości komunikacji miedzy odległymi sieciami. Działa ono w oparciu o komunikat Time exceeded manipulując wartością TTL. Na początku nadawca wysyła pakiet IP z zawartością ICMP do docelowego hosta ustawia TTL na jeden i przesyła do bramy. Brama zmniejsza TTL i odsyła do klienta komunikata time exceeded, nam na ekranie pojawia się pierwszy skok. Następnie nadawca zwiększa TTL o 1 i wysyła ponownie i tak dalej, aż osiągnie cel podany podczas wydawania polecenia lub liczba skoków osiągnie 30. Zamiast nazw hostów (routerów) lub ich adresów IP zobaczymy gwiazdki (*), wówczas oznaczna to, że wysłany pakiet został utracony lub host nie jest w stanie (np. ze względów bezpieczeństwa) opowiedzieć za pomoca komunikatu time exceeded.
W przypadku nagłówków pakietów IPv6 nie mamy doczynienia z polem TTL, a z polem Hop Limit.
Zadanie praktyczne - Packet Tracer
Weryfikacja adresacji IPv4 i IPv6 - scenariusz Weryfikacja adresacji IPv4 i IPv6 - zadanie Stosowanie komendy ping oraz traceroute do testowania połączeń w sieci - scenariusz Stosowanie komendy ping oraz traceroute do testowania połączeń w sieci - zadanie
Podsumowanie
Ten rozdział zamyka warstwę trzecią. Poznaliśmy w nim protokoł ICMP, podstawowe komunikaty oraz ich rodzaje. Dowiedzieliśmy się jaką ważną rolę będzie pełnić ten protokół w sieciach opartych na IPv6. Na koniec omówiliśmy sobie sposób działania narzędzi takich jak ping czy traceroute oraz w jaki sposób wykorzystują do swojego działania komunikaty protokołu ICMP.
Zadanie praktyczne - Packet Tracer
Używanie ICMP do testowania i korygowania łączności - scenariusz Używanie ICMP do testowania i korygowania łączności - zadanie
Laboratorium
Stosowanie komendy ping oraz traceroute do testowania połączeń w sieci
1.14. Warstwa transportowa
Warstwa transportowa jest odpowiedzialna za komunikację pomiędzy aplikacjami uruchomionymi na różnych komputerach. Wraz z niższymi warstwami odpowiedzialna jest za komunikację sieciową.
1.14.1. Dostarczanie danych
Warstwa transportowa jest odpowiedzialna za takie czynności jak:
- Śledzenie indywidualnych połączeń
- Segmentacje danych i ich ponowne złożenie
- Dodanie nagłówka informacji do danych, tworząc segment
- Identyfikacje, separację oraz zarządzanie wieloma połączeniami
- Wykorzystanie segmentacji oraz multipleksacji do umożliwienia prowadzenia wielu połączeń w tej samej sieci.
Warstwa IP nie ma możliwość bezpośredniego dostarczenia danych w docelowe miejsce. Określają to protokoły warstwy transportowej są one odpowiedzialne za sposób wymiany danych między hostami oraz za spełnienie wymagań wykorzystywanych połączeń. Protokołami warstwy transportowej są TCP oraz UDP.
Protokoł TCP wybierany jest przez aplikacje wymagające niezawodnego połączenia. Funkcjonalnością warstwy transportowej, za które odpowiada protokół TCP to:
- Numerowanie oraz śledzenie segmentów danych dostarczanych do określonych hostów oraz określonych aplikacji
- Potwierdzenie otrzymania danych
- Retransmisję każego niepotwierdzonego fragmentu danych, po określonyn czasie.
- Skwencjonowane dane mogą być dostarczane w dowolnej kolejności
- Dostosowanie wysyłania danych do możliwości odbiorcy.
Protokoł UDP dostacza bardzo podstawowywch funkcji dostarczania danych między określonymi aplikacjiami, przy minimalnym obciążeniu oraz weryfikacji poprawności przesyłanych danych. Cechami, które wyróżniają ten protokoł jest:
- Protokoł UDP jest bezpołączeniowy.
- Protokół UDP uznawany jest protokoł best-effort, ponieważ nie stosuje on potwierdzeń po otrzymaniu danych.
Protokół UDP jest również wykorzystywany dla aplikacji działajacej na zasadzie żądanie-odpowiedź, gdzie ilość danych jest niewielka, nie ma tam również retransmisji, przez co taka wymiana informacji może zostać bardzo szybko zrealizowana. Przykład: transmisja głosu (VoIP), komunikacja z DNS. Wymagane cechy:
- Szybki
- Minimalne obciążenie
- Nie wymaga potwierdzeń
- Nie wysyła retransmisji
- Dostarcza dane w kolejności w jakiej dotrą do hosta docelowego
Inne aplikacje, którym bardziej zależy na jakość przesyłanych danych wybiorą transmisję opartą na protokole TCP. Przykład: Poczta elektroniczna (protokoły IMAP/SMTP) czy przeglądanie sieci WWW (HTTP). Wymagane cechy:
- Rzetelny
- Wysyła potwierdzenia otrzymania danych
- Dokonuje retransmisji zagubionych danych
- Dostarcza dane w kolejności ich wysłania przez hosta źródłowego.
1.14.2. Nagłówek TCP
Podczas ekapsulacji dane z warstwy aplikacji trafiają do wartstwy transportowej. Tutaj surowe dane z aplikacji są zamieniane w segmenty po dodaniu nagłówka wykorzystywane do transmisji protokołu warstwy transportowej. Poniżej znajduje się obraz przedstawiający nagłówek TCP.
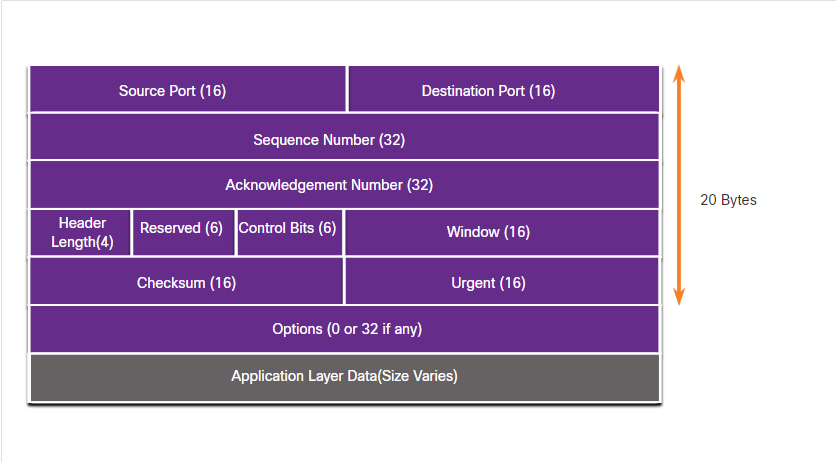
- Port źródłowy - 16-bitowe pole wykorzystywane do identyfikacji aplikacji źródłowej.
- Port docelowy - 16-bitowe pole wykorzystywane do identyfikacji aplikacji docelowej.
- Numer sekwencji - 32-bitowe pole przechowywujące numer porządkowy dla celu ponownego złożenia informacji w kolejności w jakiej została wysłana.
- Numer potwierdzenia - 32-bitowe pole wykorzysywane do wskazania danych, które zostały otrzymane oraz następny bajt oczekiwany od źródła.
- Długość nagłówka - 4-bitowe pole bardziej znane jako offset danych, wskazuje długość nagłówka segmentu TCP.
- Zarezerowane - 6-bitowe pole pozostawione do poźniejszego wykorzystania.
- Bity kontrolne - 6-bitowe pole zawierające flagi oraz kody bitowe, wskazując cel oraz funkcję tego segmentu TCP.
- Rozmiar okna - 16-bitowe pole wskazujące liczbę bajtów, która może być potwierdzona za jednym razem.
- Suma kontrolna - 16-bitowe pole używane to do ustalenia poprawności segmentu.
- Ważność - 16-bitowe pole wykorzystywane do wskazania ważności (istotności) przesyłanych danych.
1.14.3. Nagłowek UDP
Segmenty UDP rownież posiadają nagłówki, jednak nie tak rozbudowne jak w przypadku TCP. Dla porównania nagłówek UDP zawiera tylko 4 pola.
- Port źródłowy - 16-bitowe pole wykorzystywane do identyfikacji aplikacji źródłowej.
- Port docelowy - 16-bitowe pole wykorzystywane do identyfikacji aplikacji docelowej.
- Długość nagłówka - 4-bitowe pole bardziej znane jako offset danych, wskazuje długość nagłówka datagramu UDP.
- Suma kontrolna - 16-bitowe pole używane to do ustalenia poprawności datagramu.
1.14.4. Numery portów
Protokoły TCP oraz UDP wykorzystują numery portów do zarządzania działająch w tym samym czasie połączeń. Port źródłowy wskazuje aplikację źródłową na lokalnym hoście natomast port docelowy aplikację docelową na hoście zdalnym.
Porty znajdują się wewnątrz segmentów warstwy transportowej, Segmenty natomiast są enkapsulowane w pakiety IP. Kombinacja adresu IP oraz numeru portu nie ważne, z której strony w transmisji nazwany jest gniazdem. Gniazda umożliwiają klientom wielkrotne połączenia z tym samym serwerem, czy tą samą usługą.
Portów ze względu na rozmiar pola portu docelowego i źródłego ma długość 16-bitów, to bez modyfikacji nagłówków porty mają zakres od 0 do 65535. Większość portów jest już przydzielona i mozna je podzielić na trzy mniejsze zakresy,
- Dobrze znane porty - zakres: 0 - 1023 - większość znanych nam usług sieciowych, HTTP, FTP czy poczta.
- Porty zarejestrowane - zakres: 1023 - 49151 - Porty przydzielone przez IANA dla aplikacji i procesów, znane porty z tego zakresu np.: 2049/TCP NFS czy 3306/TCP serwer baz danych MySQL.
- Porty prywatne/dynamiczne - zakres: 49152 - 65535 - Porty do wykorzystywane przez klienta jako port źródłowy.
Nie będę wypisywał tutaj jakiś list. Wszystko jest dostępne w Internecie lub w dystrybucjach Linuksa w pliku /etc/services.
Warto odczasu do czasu zwrócić uwagę na to jakie połaczenia są realizowane w naszym systemie w zależności od systemu możemy wykorzystać do tego albo polecenie netstat dla MS Windows lub ss dla dystrybucji Linuksa.
1.14.5. Procesy komunikacji TCP
Każdy proces aplikacji serwera jest skonfigurowany w taki sposób, aby korzystać z portów. Dwie aplikacje na tym samym serwerze nie mogą mieć przypisanych tych samych portów. Aktywna aplikacja z przypisanym portem uznaje się za otwarą, oznacza to mniej więcej tyle, że jej proces przyjmie dane przekazane do tego portu. Oznacza to również, że każde żądanie od klientów jest akceptowane i dane przekazywane są do procesu aplikacji.
Klient nawiązuje połączenie w tzw. schemacie Three-Way-Handshake. W wygląda to mniej więcej w taki sposób
- Klient incjalizuje połaczenie w modelu klient-serwer z serwerem wysyłając do niego segment z ustawioną flagą SYN.
- Serwer odpowiada na próbę inicjalizacji połączenia odsyłając do klienta segment z ustawionymi flagami SYN, ACK.
- Klient przesyła odpowiedź do serwera z ustawiona flagą ACK i w ten połączenie zostaje nawiązane.
Zamykanie połączeń odbywa się podobny sposób. Jeśli nie ma więcej danych do przesłania, klient wysyła segment z ustawioną flaga FIN. Następnie serwer wysyła dwa segementy jeden z odpowiedzią na wysłaną flage FIN oraz drugi segment z ustawioną flagą FIN wysłaną do klienta. Kiedy klient odbierze taki segment, potwierdza za pomocą flagi ACK, jego odebranie i połącznie zostaje zakończone.
Flagi kontrone wykorzystywane do zarządzania połączeniami TCP:
- URG - Wskaźnik ważności pola Urgent.
- ACK - Flaga potwierdzająca wykorzystywana normalnej komunikacji, ale również w przy nawiązywaniu i kończeniu połączeń.
- PSH - funkcja push
- RST - restartuje połączenie kiedy napotkano błąd lub minął czas oczekiwania.
- SYN - Synchonizacja numerów sekwencyjnych, flaga wykorzystywana podczas nawiązywania połączenia.
- FIN - Wysyłający nie ma więcej danych, używane do zamykania połączeń
1.14.6. Niezawodność i kontrola przepływu transmisji TCP
W przypadku transmisji sieciowej może dojść do zgubienia części danych (pakietu) z róznych przyczny, rownie istotna może być ścieżka jaką poruszają się pakiety do miejsca docelowego, pakiety z tego samego źródła wysłane inną ścieżką mogą dotrzeć do celu poźniej niż inne. Wówczas warstwa transportowa otrzymała dane nie pokolei. Podobnie jest w przypadku utracenia danych, ponieważ muszą one zostać retransmitowane. Jednak zawarty w nagłówkach numer sekwencji pozwoli mechnizmom zawartym w protokole TCP złożyć widomość, tak aby nie różniła się niczym od tej wysłanej przez nadawcę.
Ciekawym mechnizmem może być SACK. Załóżmy taki przypadek, że mamy ustawione okno na odpowiedź po 10 segemencie, ale protokoł TCP uznał, że 3 i 4 segment są uszkodzone i wymagana jest ich retransmisja. To w normalnym przypadku nadawca dowiedział by się o tym fakcie dopiero po przesłaniu 10 segmentu. No dobrze troche by to opóźniło transmisje, ale mamy już nasz 3 i 4 segment, a to nie koniec ponieważ okno ustawione na 10 segment, to otrzymamy także segmenty od 5 do 10. To jeśli uda się ustalić w SACK czyli odpowiedź selektywna. W momecie gdy nadawca dowiaduje, że potrzebna jest retransmisja w dodatkowym polu w segemencie potwierdzenia zwracany jest numer sekwencyjny segmentu, który wymaga retransmisji ale w dodatkowym polu SACK znajdują się te numery sekwencyjne, które odbiorca już ma i uznał je za poprawne.
Kontrola przepływu polega na dostosowaniu ilości wysyłanych danych do możliwości odbiorcy. W przypadku protokołu TCP, kontrola przepływu pomoga utrzymać stabliność i niezawodność tego protokołu. W jedym z takich parametrów jest MSS, który określa wielkość danych niesionych w pakietach. Standardowo dla Etherenetu jest 1460B. Maksymalne MTU dla Ethernetu to 1500B, od tego musimy odjąć 20B dla nagłówka IP oraz 20B dla nagłówka TCP. Wiec pozostaje 1460B na dane z warstwy aplikacji.
Protokół TCP ma również dodatkowe mechanizmy dzięki, którym mocno obciażona stacja robocza, nie zostanie zalana segmentami w momencie kiedy nie jest wstanie odpowiedzieć, tym mechnizmem zarządza nadawca i nazywają sie Congestion Avoidance - unikanie zatorów.
1.14.7. Komunikacja z wykorzystaniem protokołu UDP
Protokół UDP nie zestawia połączenia. Ma on również mały narzut, ponieważ jego nagłówek jest mniejszy i nie zarządza on ruchem.
UDP nie korzysta z numerów sekwencji tak jak robi to TCP, przez co nie możliwości uprządkowania pakietów w takiej samej kolejności w jakiej zostały wysłane.
Serwery korzystające z transmisji UDP wykorzystują dobrze znane lub zarejestrowane porty. Kiedy datagram UDP dotrze do komputera docelowego jest on przekazywany do aplikacji na podstawie przypisanego jej numery portu.
Klienci transmisji UDP przypisują sobie porty dynamicznie, przeważnie z tej ostatniej grupy. Następnie ten port oraz port docelowy są używane w nagłówkach datagramów.
Zadanie praktyczne - Packet Tracer
Komunikacja z użyciem protokołów TCP i UDP - scenariusz Komunikacja z użyciem protokołów TCP i UDP - zadanie
Podsumowanie
W tym rodziale dowiedzieliśmy za co jest odpowiedzialna warstwa transportowa oraz jakie są jej funkcje. Poznaliśmy dwa protokoły tej warstwy - TCP oraz UDP, scharakteryzowaliśmy ich nagłówki. Następnie skupiliśmy się na opisaniu funkcjonalności protokołu TCP, na koniec krótko został przedstawiony protokół UDP.
1.15. Warstwa aplikacji
W warstwie aplikacji znajdują się elementy komunikacji sieciowej, z którymi użytkownik ma styczność podczas korzystania z zasobów Internetu. Na warstwę aplikacji składają się nie tylko aplikacje jakby sama nazwa miała wskazywać, ale także stojące za nimi protokoły, czy też metody prezentacji treści audio czy wideo, ale także utrzymanie połączenia między aplikacjami. W materiałach Cisco jak pamiętamy posługujemy się siedmiowarstowym modelem ISO/OSI, tak więc tutaj warstwa aplikacji, jaką możemy znać z modelu TCP/IP jest przedstawiona w postaci trzech mniejszych warstw.
1.15.1. Warstwy aplikacji, prezentacji i sesji
Warstwa aplikacji dostarcza interfejsu wykorzystywanego przez aplikacje do komunikacji oraz umożliwia korzystanie z sieci do przesyłania wiadomości między nimi.
W tej warstwie rezydują znane wszystkim protokoły takie jak HTTP, DNS, FTP, IMAP, SMTP, ale także taki protokoł jak DHCP.
Niższa wartswa prezentacji odpowiedzialna jest za formatowanie i prezentacje pozwalając dostosować dane źródłowe do postaci kompatybilnej z urządzeniem końcowym. Metody kompresji pozwalające na przyspieszenie ładowania zasosbu oraz ewentualną oszczędność miejsca jeśli taki zasób miał by zostać przechowany na naszych urządzeniach również rezydują w tej warstwie. Ostatnią cechą warstwy prezentacji jest zabzpieczenie transmisji przy użyciu metod szyfrowania, takich jak dobrze nam znany TLS.
Warstwa sesji jest natomiast odpowiedzialna za utrzymaniem wirtualnego dialogu pomiędzy aplikacjiami, tzw. sesji. Warstwa ta zajmuje się umożliwieniem jej inicjalizacji celem wymiany informacji pomiędzy aplikacjami, jej utrzymaniem oraz ewentualnym restartem jeśl będą ku temu przesłanki.
W warstwie aplikacji znajdują się protokoły określające standardy w wiekszości komunikacji sieciowej. Te protokoły muszą być stosowane przez obie strony i ich implementacje powinny być ze sobą kompatybilne, aby komunikacja mogła dość do skutku.
1.15.2. Komunikacja peer-to-peer
Obecny model komunikacji w Internecie opiera się o model klient-serwer, jego działanie opiera się na żądaniu przez klienta zasobów, które udostępnia serwer. Procesy zarówno klienta jak i serwera znajdują się w warstwie klienta. Format żądań i odpowiedzi klienta i serwera jest określany przez protokoły warstwy aplikacji.
W modelu P2P dwoje lub więcej komputerów może współdzielić zasoby takie jak pliki czy drukarki bez dedykowanego serwera. W tym modelu każdy jest serwerem oraz klientem, dla jednego połączenia dany host może być serwerem a w miedzy czasie przy użyciu innego połączenia pobierać plik z innego hosta. Popularnymi programami działającymi w trybie peer-to-peer jest klienci sieci BitTorrent, czy usługa Freenet.
1.15.3. Protokół HTTP oraz protokoły pocztowe.
Wpisująć w pasek adresu przeglądarki adres URL żądanej strony, przeglądarka nawiąże połączenie z serwerem WWW stojącym za żądaną stroną i pobierze ją. Połączenia między przeglądarką a serwerem strony zostaną zrealizowane za pomocą protokołu HTTP lub jego szyfrowanej wersji jaką jest HTTPS. Jak pamiętamy protokoły określają sposób komunikacji. W przypadku protokołu HTTP, jest on dosyć prosty więc warto sobie go opisać.
- Po wpisaniu adresu do przeglądarki np. https://www.cisco.com/index.html zostanie on zinterpretowany i podzielony na konkretne sekcje określające: protokoł (https), nazwę hosta, który udostępnia tą witrynę (www.cisco.com) oraz żądany pliki (index.html).
- Na drugim etapie przeglądarka wysła do hosta żądanie wskazanego w adresie pliku. Wcześniej określając adres IP poprzez wykorzystanie protokołu DNS. Tego typu żądanie określa się mianem żądania GET. W ten sposób sesja protokołu HTTP zostaje rozpoczęta.
- W odpowiedzi serwer wysła żądaną stronę. W tym momencie możemy uznać sesję HTTP uznać za zakończoną.
- Przeglądarką interpretuje otrzymaną stronę i wyświetla wynik użytkownikowi.
W drugim kroku wspomniano, że żądanie strony można określić jako GET, GET jest jednym z faktycznych komunikatów protokołu HTTP. Jest on używany w momencie gdy klient chce pobrać zasób z serwera, wówczas taki zasób jest mu udostępniany po przez wysłanie go do klienta. Po za klasycznym GET-em mamy do dyspozycji komunikat typu POST, jego zadaniem jest wysłanie osobnych danych na serwer lub do aplikacji, na przykład za pomocą formularza na stronie. Innym rodzajem komuniktów jest PUT, które zadaniem jest przysłanie plików na serwer WWW.
Obecnie poza sieciami lokalnymi, nie spotkamy transmisji z użyciem protokołu HTTP, ale przy użyciu protkołu HTTPS - bezpieczniejszej wersji. Oczywiście mogą zdarzyć się wyjątki, gdzie takie strony jak np. ta, kompletnie nie potrzebują HTTPS
Nieco innym rodzajem transmisji jest korzystanie z poczty elektronicznej. W dużym skrócie, przy poczcie elektronicznej wykorzystywane są trzy protokoły, jeden dla wysyłania oraz dwa do odbierania poczty. Obecnie nikt nie korzysta z gołych protokółów, choć w przypadku poczty jest jak najbardziej możliwe, to na co dzień wykorzystuje się programy pocztowe, będące klientami a ich zadaniem jest ułatwienie użytkownikowi korzystanie z poczty elektronicznej. Uruchamiając taki program, to jeśli posiadamy konfigurację konta pocztowego, to z serwera zostanie pobrana poczta ponieważ program połączy się albo z IMAP-em po porcie TCP/993 dla transmisji szyfrowanej lub po porcie TCP/143 dla transmisji nieszyfrowanej lub też z protokołem POP3 po porcie TCP/995 dla transmisji szyfrowanej oraz TCP/110 dla transmisji nieszyfrowanej. Rożnica w tych protokołach polega na tym, że protokół POP3 pobiera zawartość naszej skrzynki na serwerze, bez pozostawienia jej kopii na nim (chociaż w ustawieniach mozna wymuść, aby kopia pozostała na serwerze), z kolei działanie protokołu IMAP opiera się na synchronizacji, do klienta trafia ją szczątkowe informacje o poczcie na serwerze, w momencie gdy użytkownik kliknie w wiadomość zostanie ona pobrana z serwera i wyświetlona.
Inaczej jest w przypadku gdy chcemy wysłać wiadomość. W momencie gdy użytkownik zdecyduje się na kliknięcie przycisku wyśli zostanie on połączony z z serwerem SMTP TCP/465 dla transmisji szyfrowanej oraz TCP/25 dla transmisji nieszyfrowanej, wskazanym w konfiguracji konta. Wiadomość zostanie przekazana do serwera wraz ze wszystkimi danymi takimi jak odbiorca czy temat. Na podstawie odbiorcy nasz serwer SMTP prześle wiadomość do odpowiedniego dla odbiorcy serwera SMTP, z tam tąd odbiorca pobierze ją za pomocą jednego z wyżej opisanych protokołów.
1.15.4. Usługi adresacji IP
W obecnych czasach ciężko było by się poruszać po Internecie, przy użyciu adresów IP. Dlatego też wynaleziono specjalny rodzaj usługi, jaką jest DNS. Zadaniem tego protokołu jest rozwiązywanie nazw domenowych na adresy IP, DNS wykorzystuje tutaj transmisję UDP po porcie 53. Serwery DNS przechowują dane w postaci rekordów, rekordy te mają określony typ. Tak więc, rekordy typu:
- A - adres IPv4
- NS - adres IP serwera autorytatywnego (serwera obsługjącego tą domenę) dla domeny
- AAAA - adres IPv6
- MX - rekord wskazujący na serwer pocztowy.
System DNS używa tych samych formatów wiadomości między serwerami (uwaga, serwery DNS wymieniają informacje wykorzystując transmisję TCP na porcie 53, a UDP jak w przypadku wymiany informacji z klientami). Ten format zawiera takie informacje jak kolejno:
- Zapytanie - zapytanie do serwera DNS
- Odpowiedź - opowiedź od serwera DNS
- Autorytatywność - wskazanie serwera autorytatywnego dla zapytania.
- Dodatkowe - przechowuje dodatkowe informacje
Klient szukając adresu IP dla nazwy domenowej hosta na początku odpyta serwer DNS, który ma ustawiony w swoim systemie. Jeśli nie będzie on posiadać odpowiedzi, to wówczas rozpocznie się odpytywanie hierarchiczne.
Otóż system DNS ma budowę hierarchiczną i cała hierarchia jest zapisana w adresie URL strony. Za przykład weźmy naszą wcześniejszą witrynę jaką jest www.cisco.com. Jeśli odczytamy ją od prawej do lewej, wówczas będziemy mieć rozeznanie w hierarchi DNS. W tym przypadku najważniejszą domeną jest .com i serwer tej domeny zawiera adres serwera DNS dla subdomeny cisco, a ten z kolei zawiera adres hosta www. Tak własnie wygląda rozwiązywanie nazw, gdy nasz najbliżej położony DNS, nie posiada odpowiedzi na zadane mu pytanie. Warto dodać, że serwery trzymają taką odpowiedź (nieautorytatywną, hosta z innej domeny) w pamięci podręcznej, wrazie gdyby inny z hostów w sieci pytał o tego hosta.
Pomocnym narzędziem, które pozwoli nam odpytać system DNS jest polecenie nslookup. Polecenie to pozwala na odpytanie serwera DNS z pominięciem pamięci podręcznej urządzenia. Dostępne jest ono w każdym system operacyjnym.
Kolejnym przykładem protokołu, który pracuje wraz z adresacją IP jest DHCP. Jego zadaniem jest automatyczna konfiguracja interfejsów sieciowych hostów. Przypisanie im adresów IP oraz pozostałych parametrów pozwalających na komunikację w sieci. Konfiguracja hosta wykonana przez serwer DHCP uznawana jest za dynamiczną z racji tego, że może się zmienić, po określonym czasie. W sieci z włączonym DHCP uzyskamy dzierżawę (adresy IP z serwera DHCP uzyskuje się na konkretny, zapisany w konfiguracji serwera czas) adres IP z puli (zakresu adresów, przydzielonych do tego zadania). W wielu sieciach stosuje się mieszane podejście do konfiguracji adresów IP, niektóre urządzenia takie jak serwery czy urządzenia pośredniczące w komunikacji sieciowej, np. przełączniki posiadają statycznie (ręcznie) skonfigurowane adresy IP. Można równiez statycznie skonfigurować adresy urządzeń wykorzystując DHCP (rezerwacje adresów).
W przypadku adresów IPv6, również może działać serwer DHCP. Z tą różnicą, że nie konfiguruje on adresu bramy domyślnej, ten parametr jest pobierany z komunikatów Router Advertisement rozgłaszanych przez router.
Wymiana komunikatów między nowymi hostami w sieci serwerem DHCP wygląda następująco:
- Kiedy host z ustawioną automatyczną konfiguracją chce skonfigurować swój interfejs wysyła pakiet broadcast na port 67 zawierający komunikat DHCPDISCOVER
- Serwer DHCP odpowiada na oferując dzierżawę klientowi, komunikat DHCPOFFER.
- Klient akceptuje ofertę serwera wysyłając do serwera żądanie DHCPREQUEST
- Jeśli oferta serwera jest jeszcze aktualna serwer odsyła DHCPACK, wówczas cały proces można uznać za zakończony.
- Jeśli natomiast oferta dzierżawy nie jest juz aktualna serwer wysyła do klienta komunikat DHCPNACK, w tym przypadku cała procedurę należy powtórzy i ponownie rozpocząć od poszukiwania serwera DHCP.
Dla IPv6 proces wygląd podobnie, różnicą są nazwy komunikatów. W DHCPv6 mamy SOLICIT, ADVERTISE, INFORMATION REQUEST oraz REPLY.
Laboratorium
Obserwacja procesu odwzorowania nazw DNS
1.15.5. Usługi współdzielenia plików
Jednym z protokołów, które możemy wykorzystać do współdzielenia plików jest protokół FTP. FTP jako jedna z nielicznych usług posiada dwa porty TCP/21 oraz TCP/20. Pierwszy z nich służy do nawiązania nawiązania połączenia z serwerem i przesyłania do niego poleceń protokoł FTP. Jeśli zdecydujemy się na wysłanie lub pobranie danych z serwera, wówczas pomiędzy naszymi komputerami zostanie otwarte nowe połączenie na portcie TCP/20. Warto pamiętać o tym, że w przypadku protokołu FTP możliwe jest przesyłanie danych w obu kierunkach. Klient może pobierać dane lub ładowanie je na serwer.
Innym protokołem jaki możemy wykorzystać udostępniania plików jest protokół SMB (Server Message Block), działanie tego protokołu opiera się na żądaniach i odpowiedziach. Trzema głównymi funkcjami komunikatów SMB jest:
- Rozpoczenie oraz zerwanie sesji i autentykacja
- Kontrola plików i drukarek
- Pozwolenie na wysyłanie komunikatów do innych urządzeń (sic)
W przeciwieństwie do protokołu FTP połączenie SMB jest długoterminowe, a użytkownicy mogą korzystać z zasobów udostępnianych przez SMB, jakby były ich lokalnymi zasobami.
Podsumowanie
Ten rozdział związany był z warstwą aplikacji. Poznaliśmy definicje oraz funkcje warstw prezentacji oraz sesji modelu OSI. Dowiedzieliśmy się w jaki sposób funkcjonują najważniejsze protokoły wykorzystywane zarówno w sieciach lokalnych jak i w internecie.
1.16. Wprowadzenie do bezpieczeństwa sięci
Jak możemy sobie zdawać sprawę lub też nie zadaniem sieci w ujęciu teleinformatycznym jest umożliwienie komunikacji między jednym a drugim węzłem tej sieci. A jak wszystko na świecie, każdy kij ma dwa końce, przez co posiadanie możliwości komunikacji, może mieć negatyny wpływ na nasze urządzenia, poufne dane a co za tym idzie na nas samych. Oczywiście możemy kontragrumentować tę tezę przedstawiając przypadek połączeń między zaufanymi węzłami, jednak i one mogą w wyniku zaniedbań, ludzkiej omylności lub też celowego działania mogą zostać wykorzystane przeciwko nam, nasze zaufanie tylko ułatwi to zadanie. W tym rozdziale spróbujemy zapoznać się z rodzajami zagrożeń z jakimi możemy się spotkać.
1.16.1. Zagrożenia i podatności.
Zagrozenia mogą wynikać z wielu aspektów. Atakujący mogą wykorzystywać podatności w oprogramowaniu czy sprzęcie, jednak nie wszystkie ich działania są tak wyrafinowane. Często udaję się odgadnąć czyjeś dane logwania. Osoby wykorzystujące luki w oprogramowaniu lub w jaki kolwiek sposób będące w stanie zmodyfikować oprogramowanie aby uzyskać dostęp do systemu są nazwywane w nomenklaturze Cisco podmiotem zagrożenia.
Można natomiast określić cztery rodzaje zagrożeń na jakie mogą być narażeni użytkownicy sieci w momencie, gdy podmiot zagrożenia uzyska do niej dostęp:
- Kradzież informacji
- Utrada danych, bądź ich zmiana
- Kradzież tożsamości
- Przerwanie dostępu do usług
Podatnością możemy nazwać słaby punkt czy to w urządzeniu czy też w oprogramowaniu. Podaności na uzyskanie nieautoryzowanego dostępu może posiadać każde urządzeń, które podłączamy do sieci. Podaności można uprządkować bazując na genezie jej powstania (pominiemy podatności związane, z błędami lub niedociągnięciami programistycznymi, chociaż pierwsze dwa rodzaje w niższych wartstwach też je obejmują):
- podatność technologiczna - wynika ze słabości samych protokół sieciowych, systemów operacyjnych czy oprogramowania (firmware-u) urządzeń sieciowych.
- podatność konfiguracyjna - wynika z zaniedbań podczas wdrażania urządzeń sieciowych lub usług. Opiera się na przykład na domyślnych konfiguracjach, nie zmienionych domyślnych hasłach dostępu (w przypadku urządzeń sieciowych), ale także na złym zarządaniu użytkownikami.
- podaności polityki bezpieczeństwa - wynikające z braku lub niejednoznacności zasad bezpieczeństwa przyjętych w organizacji. Mogą również wynikać z lokalnego prawa, czy też braku jasno określonych działań podczas awarii.
Inna bardzo często pomijaną kwestią związaną z bezpieczeństwem sieci, jest bezpieczeństwo fizyczne zarówno serwerownii jak i pomieszczeń biurowych, w których może być przeprowadzany krytyczny dla organizacji proces technologiczny lub przetważane są istotne dane. Nie mniej jednak tutaj raczej skupimy się na tzw. czynnikach środowiskowych
Możemy określić cztery klasy zagrożeń fizycznych, które np. mogą prowadzić do zagrożenia przerwania dostępności usług.
- zagrożenia sprzętowe - uszkodzenia serwerów i sprzętu sieciowego.
- zagrożenia środowiskowe - praca urządzeń poza zakresem ich temperatur oraz w pomieszczeniach o niewłaściwej wilgotności powietrza.
- zagrożenia elektryczne - zniki zasilania lub niewłaściwe parametry fizczne energii elektrycznej, którą są zasilane urządzenia.
- zagrożenia konserwacyjne - brak cześci zamiennych, nieumiejętnie przezprowadzone prace serwisowe, złej jakości okablowanie oraz niejednoznacze opisy w szafach krosowniczych oraz w punktach dystrybucyjnych.
1.16.2. Ataki sieciowe
Najczęściej zadaniem ataku sieciowego jest uzyskanie nieautoryzowanego dostepu do określonego i chronionego zasobu. Można wróżnić kilka podstawowych rodzajów ataków sieciowych, które mogą wpasowywać się w zagrożenia opisane na początku tego rozdziału.
- złośliwe oprogramowanie - oprogramowanie lub
fragment kodu, którego celem jest wykonanie dowolnej niepożądanej
przez nas czynności na komputerze. Wśród nich możemy wyróżnić:
- wirusy - złośliwy samodzielny program lub fragment innego programu. Na skutek nie uwagi użytkownika może infekować wiele komputerów, do infekcji wirusem potrzebne jest działanie użytkownika, np. uruchomienie zainfekowanego programu.
- robaki - rodzaj wirusa, który nie wymaga działania użytkownika do infekcji. Robaki często wykorzystują znane podatności w systemach operacyjnych, usługach lub innych programach i replikują się na skompromitowanych hostach.
- konie trojańskie - złośliwe oprogramowanie podszywające się pod przydatne programy.
- rozpoznanie - samo w sobie rozpoznanie nie jest atakiem, a jego fazą przygotowawczą, chociaż i w tej fazie można użyć narzędzi, który przy wysokim poziomie bezpieczeństwa w organizacji mogą wywołąć alarm. Do rozpoznania można również wykorzystać dane publicznie dostępne w Internecie. Takie jak np. adresację IP sieci publicznej wykorzystywanej w organizacji.
- ataki dostępowe - ataki dostępowe polegają już
głównie na eksploatacji podatności, ale jak również takie czynności
jak odgadywanie czy łamanie haseł oraz próba przechwycenia danych
logowania. Możemy wyróżnić cztery typy takich ataków:
- ataki na hasła - mogą obejmować odgadywanie, łamanie ale jak i również przechwytywanie ciągów znaków w jakich zaszyfrowane są hasła (tzw. hash hasła), które poźniej mogą zostać złamane.
- Wykorzystanie zaufania - podmiot zagrożenia może wykorzystywać nieautoryzowane uprawnienia w celu zwiększenia dostępu do systemu, możliwe przejmując kontrolę nad celem.(sic)
- Przekierowanie portów - podmiot zagrożenia wykorzystuje przejęty host A, łącząc się z nim przez SSH (port TCP/22), następnie ze względu na to, że host a jest uprawniony do połączenia z hostem B przez Telnet (port TCP/23) napastnik to wykorzystuje (sic).
- atak Man-in-the-middle - napastnik znajduje gdzieś miedzy na drodze między jednym wezłem a drugim. Zbiera on dane wymieniane między tymi hostami, może również je zmieniać lub wpływać na ruch między nimi.
- ataki odmowy usługi - atak ten polega nawiązaniu tak dużej ilości połączeń z daną aplikacją na serwerze, że ten nie będzie w stanie obsłużyć kolejnych, przez co usługa staje się niedostępna dla innych osób. Ataki DoS są wyjątkowo łatwe w implementacji więc mogą być stosowane przez mniej doświadczone osoby. Odmianą ataków odmowy usługi (DoS) są ataki DDoS, które różnią się rozproszeniem podmiotu zagrożenia na wiele hostów. Do ataków DDoS wykorzystuję się sieci przyjętych lub zainfekowanych złośliwym oprogramowaniem hostów tzw. botnet. Do kontroli takiej sieci wykorzystuje się inne przejęte hosty tzw. Command&Control przez co napastnik może pozostać nieuchwytny.
Laboratorium
Badanie zagrożeń bezpieczeństwa sieci
1.16.3. Zabezpieczanie sieci
Aby zabezpieczyć się przez opisanymi w tym rozdziale atakami należy wdrożyć odpowiednie rozwiązania. Przed zakupem nie wiadomo jak drogiego komercyjnego systemu warto na początku zadbać o zabezpieczenie takich urządzeń jak serwery, routery, switche oraz urządzenia użytkowników końcowych. Po zabezpieczeniu tych urządzeń można wówczas pomyśleć o wdrożeniu systemów IPS/IDS, systemów AAA (sic) czy filtrów treści. Warto dodać, aby przy wyborze rozwiązań jednym z kluczowych składników było to aby jedne rozwiązania mogły współpracować z pozostałymi elementami systemu bezpieczeństwa, ale także rozwiązanimi już obecnie działającymi w naszej sieci.
Jedną z tych podstawowych czynności, jakie możemy podjąć czyniąc naszą infrastrukturę teleinformatyczną bardziej bezpieczną jest zapewnienie kopii zapasowej istotnych dla organizacji danych. Podczas rozważań na temat kopii zapasowej należy wziąć pod uwagę cztery poniższe zagadnienia:
- Częstotliwość - Kopie zapasowe należy wykonywać w regularnych odstępach czasu najlepiej codziennie. Częstotliwość kopii zapasowych powinna być ujęta w polityce bezpieczeństwa. Wykonywanie pełnych kopii może być czasochonne więc warto wydzielić czas (powiedzmy raz w tygodniu) na wykonanie takiej kopii, w pozostałe dni można robić kopie tylko tych plików, które były ostatnio modyfikowane.
- Przechowywanie kopii - jeśli organizacja obejmuje kilka budynków to warto trzymać te kopie poza budynkiem, w którym te dane są przetwarzane. Możemy tutaj posłużyć się zasadą 3-2-1 - minimum 3 kopie, w 2 różnych miejscach, a 1 poza główną siedzibą. Jeśli organizacja jest na tyle duża, to może wynająć przestrzeń dyskową w lokalnym centrum danych.
- Bezpieczeństwo kopii - Każda kopia powinna być chroniona hasłem. Tak samo jak procedura jej przywrócenia.
- Integralność kopii - Należy dbać o poprawność i integralność kopii zapasowej. Raz na jakiś czas należy jedną losową kopię przywrócić w środowisku testowym.
Jedną z najprostszych rzeczy jakie możemy wykonać na urządzeniach użytkowników jest sprawdzenie poprawności konfiguracji automatycznych aktulizacji. I jeśli brakuje poprawek w systemach to należy je niezwłocznie zainstalować. To samo tyczy się programów antywirusowych, program ten może aktualizować swoje bazy kilka razy w ciągu dnia. Dystrybucje Linuksa posiadają takie rozwiązania jak unattended-upgrades, które instalują automatycznie pakiety z takich gałezi repozytoriów jak security.
Istotne podczas zabepieczenia sieci jest również kontrola użytkownika który ma z niej korzystać i nie musi się to tyczyć wyłącznie komputerów ale jeśli jest taka możliwość to i urządzeń sieciowych i taką usługą może być serwer AAA. Najprostszą a zarazem jedną z lepszych jest protokół LDAP, zarówno jak i w wolnej implementacji Samba AD czy własnościowej MS Windows Active Directory.
Urządzenie, które powinno znaleźć się w każdej sieci to zapora. Jej zadaniem jest monitorowanie i zarządzanie ruchem na podstawie zdefiniowanych przez administratora reguł. Zapory mogą tworzyć specjalny rodzaj sieci tzw. strefę zdemilitaryzowaną - DMZ. W tej sieci umiesczane są serwery usług, które mają być osiągalne z poziomu sieci Internet. DMZ-ty najczęsciej konfigurowane są w taki sposób, że użytkownicy sieci lokalnych w organizacji mogą się łączyć bezproblemu z tymi serwerami, jednak te same serwery nie są w stanie inicjować połączeń z hostami w sieciach lokalnych. Kiedy jeden z tych serwerów zostanie przejęty przez napastnika, zostanie on ograniczony tylko do DMZ (oczywiście, nie należy takiego włamania lekceważyć) i nie będzie w stanie narobić wiecej szkód w innych sieciach. Same zapory najczęsciej są skonfigurowane tak aby blokować cały ruch pochodzący z Internetu, chyba, że przekierowano porty. Wówczas ruch na tych wybranych portach jest możliwy. Dostępnych jest kilka różnych metod filtrowania ruchu przez zapory o to cztery z nich
- Filtrowanie pakietów - filtowanie pakietów na podstawie adresów IP czy adresów MAC.
- Filtrowanie aplikacji - filtrowanie pakietów na podstawie numerów protów.
- Filtrowanie treści - filtrowanie całych domen oraz pojedynczych stron na podstawie ogólnodostępnych list w internetcie.
- Inspekcja stanów pakietów (SPI) - metoda filtrowania pakietów, która pozwala odfiltrować pakiety TCP z ustawionymi odpowiednimi flagami, przez co możliwa jest tylko przepuszczenie odpowiedzi z Internetu na połączenia, których źródłem są hosty wewnętrzne. SPI ma możliwość wykrywania i blokowania róznych ataków w tym ataków DoS.
1.16.4. Bezpieczeństwo urządzeń
Poza serwera i urządzeniam użytkowników końcowych, do zabezpieczenia pozostały nam jeszcze urządzenia sieciowe takie jak routery czy switche.
W przypadku routerów Cisco mamy dyspozycji narzędzie Cisco AutoSecure, które pomoże nam przeprowadzić proces zabezpieczania urządzenia. Mimo to czynności podejmowane w celu zabezpieczenia urządzenia sieciowego nie za bardzo różnią się od procesu zabepieczania np. serwera, zaraz po zainstalowaniu na nim systemu operacyjnego.
Oczywiście na tym poziomie do uzyskania dostępu do urządzenia sieciowego będziemy wykorzystywać hasła. Warto zatem mieć na uwadzę kilka reguł dotyczących tworzenia bezpiecznych haseł:
- Dobre hasło powinno mieć co najmniej 8 znaków, ale lepsze hasła zawierają 10 i więcej.
- Hasło powinno być dość złożone, tzn. składać losowych małych, wielkich liter, cyfr, znaków specjalnych a jeszcze lepiej jakby zawierało spację.
- Najlepiej jakby hasło nie zawiera żadnych informacji, które można znaleźć na nasz temat np. daty urodzenia czy imienia naszego zwierzaka. Najlepiej omijać także powtórzenia lub często stosowane słowa.
- Jeśli korzystamy z całych słów, to warto je urozmaicić wprowadzając błędy, podobnie brzmiące litery lub zamias konkretnych liter przypominające je cyfry.
- Hasła należy zmieniać co jakiś czas, np. co 6 miesięcy.
- Nie należy nigdzie zapisywać haseł.
Jeśli chcemy stosować spację na urządzenia Cisco, to musimy podać ją jako drugi lub kolejny znak. IOS ignoruje początkowe spacje.
Teraz znając zasady dotyczące haseł możemy wygenerować hasła i następnie ustawić je na naszych urządzeniach do dając przy tym kilka dodatkowych ustawień zapisanych poniżej (pierwsze trzy opcje, ustawiamy w trybie konfiguracji globalnej):
- Szyfrowanie haseł:
service password-encryption - Minimalna długość hasła:
security passwords min-length 10 - Blokada na N sekund po X prób logowania w ciągu Y sekund:
login block-for N attempts X within Y - Automatyczne wyjście z trybu privileged EXEC po określonym czasie:
(uwaga, tę opcję zmieniamy w konfiguracji linii)
exec-timeout min. sek.
Teraz wiedząc jak bezpiczenie ustawić dostęp oparty o hasło do urządzeń sieciowych Cisco. Możemy uruchomić bezpiecznych dostęp przez SSH. Poniżej polecenie, które trzeba wykonać (cztery pierwsze opcje są wykonywane w trybie konfiguracji globalnej):
- Ustawienie unikalnej nazwy hosta:
hostname r1 - Ustawienie nazwy domenowej:
ip domain name example.com - Wygenerowanie kluczy RSA dla SSH o długości X bitów:
crypto key generate rsa general-keys modulus X - Utworzenie użytkownika w lokalnej bazie użytkowników urządzenia:
username xf0r3m secret 5up3r74jn3Has|_0 - Włączenie uwierzytelniania przy użyciu lokalnej bazy:
(uwaga, tę opcję wprowadzamy w trybie konfiguracji linii vty)
login local - Włączenie SSH dla zdalnych połączeń:
(uwaga, tę opcję wprowadzamy w trybie konfiguracji linii vty)
transport input ssh
Po zapewnieniu prawidłowego dostępu zdalnego możemy wykonać ostatnią
czynność jaką jest wyłączenie zbędnych usług. Tutaj istotna może być
wersja IOS, jaką posiadamy na swoich urządzeniach. W starszych
urządzeniach (z przed IOS-XE) możemy podejrzeć listę otwartych portów
za pomocą polecenia:
show control-plane host open-ports.
Natomiast w nowszych wersjach (od IOS-XE) używa się nieco krótszego
polecenia:
show ip ports all
Te polecenia wydajemy w trybie uprzywilejowanym EXEC bez konfiguracji.
Chcąc wyłączyć usługę powiedzmy http, musimy przejść do trybu
konfiguracji globalnej i następnie wydać polecenie:
no ip http server
Zadanie praktyczne - Packet Tracer
Konfiguracja bezpiecznych haseł i SSH - scenariusz Konfiguracja bezpiecznych haseł i SSH - zadanie
Laboratorium
Konfiguracja urządzeń sieciowych za pomocą SSH
Podsumowanie
W tym module zapoznaliśmy się z podstawami sieci. Poznaliśmy zagrożenia oraz genezę wielu podatności. Dowiedzieliśmy się jakie są podstawowe ataki oraz jak niewiele potrzeba, aby utrudnić atakującym dostęp do naszych urządzeń. Na koniec podnieślismy poziom bezpieczeństwa haseł na naszych urządzeniach Cisco oraz w bezpieczny sposób uruchomiliśmy usługę SSH. Poniżej znajdują się ćwiczenia praktyczne do wykonania w programie Cisco Packet Tracer oraz bardziej zaawansowane zadanie w postaci laboratorium.
Zadanie praktyczne - Packet Tracer
Zabezpieczanie urządzeń sieciowych - scenariusz Zabezpieczanie urządzeń sieciowych - zadanie
Laboratorium
Zabezpieczenie urządzeń sieciowych
1.17. Budowanie małej sieci
Ostatni rozdział pierwszego modułu kursu, ma skłonić nas do refleksji na temat: Co gdyby trzeba było zbudować taką małą sieć? Oczywiście pierwsze pytanie jak się nasuwa: co to znaczy mała? czasmi może okazać się, że do budowy takiej sieci wystarczy router klasy SOHO i dostęp do ISP. A czasami do małej sieci może zaliczać się nawet kilka segmentów.
1.17.1. Projektowanie małej sieci
W tym podrozdziale zastanowimy się nad kilkoma aspektami, które trzeba rozważyć podczas projektowania małej sieci.
Pierwszym z nich jest topologia. Małe sieci są zazwyczaj proste, zasięgiem obejmują jeden poziom lub jeden nieduży budynek. Takie sieci posiadają zazwyczaj jedno połączenie do ISP, mogą posiadać łącze zapasowe w postaci połączenia np. z siecią komórkową, jednak przełączanie między tymi sieciami może odbywać się w sposób ręczny. Takie sieci są zarządzane zazwyczaj przez osoby z zewnątrz, lub co może być rzadkością posiadają oni własnego administratora IT.
Jeśli już decydujemy się, że będziemy budować sieć komputerową to należy zastanowić się nad doborem urządzeń. Istnieją cztery postawowe czynnki, które należy wziąć pod uwagę podczas wybierania urządzeń dla naszej sieci:
- Koszt urządzenia
- Wydajność oraz typ portów/interfejsów
- Możliwości rozbudowy
- Funkcje i usługi oferowane przez firmware
Tworząc projekt sieci, nie można zapomnieć o adresacji IP i jej ewentualnym podziale. Jeśli już będziemy dzielić adresy klasy prywatnej na mniejsze podsieci, to warto oprzeć się na klasach urządzeń i ich połączeniach. Dla przykładu powinniśmy wydzielić osobną klasę dla serwerów i urządzeń sieciowych, ale tutaj ciekawą opcją mogą być komputery użytkowników, często są to laptopy, którą mogą mieć więcej niż jedno połączenie. Warto mieć to na uwadze zastanawiając się nad podziałem adresów IP.
Jeśli opieramy swoją sieć o połączenia kablowe, raczej będzie to kabel UTP, ponieważ jest prostszy w obsłudze, to warto pomyśleć o nadmiarowości połaczeń, na przykład na jednego użytkownika przypadały dwa gniazda sieciowe. Warto również mieć w zanadrzu zapasowy przełącznik oraz router.
Ostatnim zagadnieniem jest zarządzanie ruchem, w przypadku małej sieci nie jest to może priorytetowy temat do czasu, aż ktoś nie zacznie nam wysycać łącza np. pobierając duży plik z Internetu. Wówczas najlepszym sposobem jest inwestycja w przełączniki, którymi możemy zarządzać, tam jest możliwość nie tyle wdrożenia QoS oczywiście jest to możliwe co przypisania konkretnej przepustowości dla danego hosta w obu kierunkach.
Nie mniej jednak przełączniki i routery powinny być skonfigurowane w taki sposób aby priorytetyzować ruch zgodnie z zapotrzebowaniem wykorzystywanych w tej sieci protokół, tak więc dobrze skonfigurowane sieci posiadają wdrożony QoS (Quality of Service - priorytetyzację ruchu) (sic).
1.17.2. Protokoły wykorzystywane w małych sieciach
Najczęsciej wykorzystywanymi protokołami w małej sieci będzie na pewno protokoł HTTP lub HTTPS w bezpieczniejszej wersji. Protokoły pocztowe również mogą mieć miejsce, jak i protokoły SMB w celu wymiany plików z innymi współużytkownikami sieci. Do administracji mogą być wykorzystywane protokoły HTTPS jak i SSH. Protokoły takie DHCP oraz DNS muszą działać inaczej sieć może być trudna w użytkowaniu. Najczęściej są one zapewniane przez takie urządzenia jak routery, przynajmniej te klasy SOHO. Warto wspomnieć, że wiele usług może wykorzystywać jeden ten sam serwer fizyczny.
Inna kwestią jest wdrożenie w sieci usług głosowych oraz video czatu. Tutaj musimy się zastanowić czy nasza infrastruktura jest w obsłużyć tego typu ruch oraz musimy wybrać jedną z trzech technologii:
- VoIP - tańszy odpowiednik dla telefonów IP, oczywiście kosztem jakoś jak i funkcjonalności.
- Telefony IP - wymagają serwerów do sygnalizacji oraz utrzymywania połączeń.
- Aplikacje czasu rzeczywistego - wszelkie aplikacje dla videoczatów oraz komunikatory głosowe. Wymagają one małych opóźnień w sieci oraz wdrożenia mechanizmów QoS. Niektóre z nich mogą być oparte o protokoły Real-Time Transport Protocol (RTP) oraz Real-Time Transport Control Protocol (RTCP).
1.17.3. Rozbudowa małej sieci
Może zajść taka potrzeba, że małą sieć będzie trzeba rozbudować i warto mieć to na uwadze już podczas projektowania małej sieci. Po co? Aby wyrobić w na przykład nawyk prowadzenia dokumentacji sieci zarówno topologii logicznej, jak i fizycznej, w której można znaleźć opisy połączeń oraz lokalizacje gdzie można znaleźć router i przełączniki. Jak i prowadzenie spisu posiadanych urządzeń, które działają w sieci.
Dośc istotnym czynnikiem związanym z rozbudową sieci jest to jakim budżetem dysponujemy, być może będziemy musieli z czegoś zrezygnować lub wręcz przeciwnie będzimy mogli wdrożyć więcej przydatnych innowacji. Ważnym czynnikiem determinującym rozbudowę może być analiza ruchu przy użyciu ogólnodostępnych narzędzi takicj jak np. Wireshark.
Aby analiza ruchu była miarodajna musi zostać przeprowadzona w odpowiedni sposób. Poniżej znajduje się kilka reguł w jaki sposób zbierać pakiety, tak aby dały jak najlepszy obraz tego co się dzieje w sieci podczas normalnego dnia pracy, kiedy użytkownicy korzystają z jej zasobów:
- Zbieranie pakietów powinno odbywać podczas najwiekszego piku z użycia jej zasobów. Powiedzmy gdzieś godzinę od rozpoczęcia pracy w dniu kiedy większość pracowników jest obecna w siedzibie firmy.
- Przeprowadzenie zbierania pakietów powinno odbyć się w różnych segmentach sieci, tak aby móc uchwycić ruch specyficzny dla tego segmentu.
- Analiza ruchu powinna być oceniana na podstawie ruchu wychodzącego, przychodzącego oraz rodzaju przesyłanego ruchu (np. wykorzystywanych protokołów).
Analiza dokonana przy zastosowaniu powyższych metod może dać nam dobrą wskazówkę w jaki sposób tym ruchem możemy zarządzać.
1.17.4. Weryfikacja łączności
Weryfikację łączności możemy stosować w momencie budowania sieci, kiedy jesteśmy pewni, że wszelakie okablowanie jest podłączone. Weryfikacja łączności na wczesnym etapie budowy sieci, może przyspieszyć uruchomienie jej w całości.
Najprostszym narzędziem jest polecenie ping, opiera się ono protokół ICMP i jest dostępne w wiekszości systemów operacyjnych podłączonych do sieci. W przypadku systemów Cisco IOS, również jest ono dostępne ma ono nieco inną formę odpowiedzi niż standardowe narzędzia znane z dystrybucji Linuksa czy systemów MS Windows. Wysyłane jest komuników i na każde z nich możemy otrzymać albo kropkę (.) w przypadku braku odpowiedzi lub też wykrzyknik (!) jeśli taka odpowiedź zostanie otrzymana. Możemy rownież uzyskać dużą literę U, która oznacza, że sieć hosta, do którego wysłaliśmy to zapytanie jest nie osiągalna (równoznaczne z destination unreachable). Polecenie ping jest uruchamiane z adresem docelowego hosta jako pierwszym argumentem. W przypadku IOS jest tak samo, ale jeśli uruchomimy to polecenie bez argumentu, to wówczas przejdzie ono do trybu rozszerzenego, w którym to będziemy mogli skonfigurować więcej parameterów poza samym podaniem adresu docelowego, np. źródłowy interfejs.
Innym poleceniem które może być przydatne podczas weryfikacji łączności w IOS jest traceroute, nazwa ta obowiązuje również w Uniksach, w przypadku systemu MS Windows jest tracert. Zadaniem tego polecenia jest przeanalizowanie trasy do hosta docelowego. Narzędzia te mogą posłużyć do analizy czy wina w braku łączności z Internetem leży po stronie naszej konfiguracji czy naszego usługodawcy.
Jeśli korzystamy z powyższych poleceń na zwykłym PC-cie, to warto pamiętać, że te polecenia posiadają komunikaty pomocy nie zależnie od systemu. W Uniksach dodatkowo istnieje nieco bardziej obszerny plik pomocy tzw. strona podręcznika.
1.17.5. Polecenia wyświetlania konfiguracji sieciowej
Podczas budowania małej sieci, gdziej pod koniec prac nad nią przyjdzie nam zacząć podłączać do niej hosty, wówczas możemy potrzebować sposóbów na sprawdzenie ich konfiguracji sieciowej.
Najczęsciej podłączanym przez nas hostem będzie MS Windows 10 i w ustawieniach karty sieciowej w aplecie "Centrum udostępniania i sieci" możemy sprawdzić parametry konfiguracji sieciowej takie jak adres IP, maska, adres bramy czy adresy serwerów DNS. Możemy również wyświetlić te informacje w wierszu polecenia, za pomoca polecenia ipconfig. Polecenie posiada kilka przydatnych opcji takich jak:
- /all - wyświetla bardziej szczegółowe informacje
- /release,/renew - zwolnienie używanego adresu IP oraz ponowna prośba o przydzielenie adresu IP.
- /displaydns - wyświetlenie wpisów w pamięci podręcznej systemowego DNS.
Może tak się zdarzyć, że chcąc wdrożyć pewne usługi w sieci organizacji będziemy mieć stycznosć z dystrybucjami Linuksa. Tutaj do wyświetlenia adresu IP używa się polecenia ip a do wyświetlania bramy wykorzystujemy polecenie ip route adres bramy będzie wówczas widnieć we wpisie dla sieci (pierwsza kolumna) 0.0.0.0. Natomiast adresy serwerów DNS możemy zobaczyć, poprzez wyświetlenie zawartości pliku /etc/resolv.conf.
W systemach MacOS na komputerach firmy Apple, listę dostępnych interfejsów możemy wyświetlić w terminalu za pomocą polecenia networksetup -listallnetworkservices. Po ustaleniu interfejsu wydajemy polecenie networksetup -getinfo nazwa interfejsu.
Innym przydatnym narzędziem może być sprawdzenie tablicy ARP. Tablica ARP ma to do siebie, że komputer w sieci nie odpowiada na ping, ponieważ może być tak skonfigurowany za pomocą pakietu programu antywirusowego, aby nie odpowiadał na te żądania. To jeśli adres IP hosta ma dowiązany MAC w naszej tablicy ARP, to znaczy, że jest on poprawnie skonfigurowany tylko nie odpowiada na ping. Tablicę ARP możemy wyświetlić za pomoca polecenia arp -a w przypadku systemów MS Windows, w przypadku dystrybucji Linuksa jest ip neighbor. Tablice ARP możemy wyczyścić w systemach MS Windows za pomocą polecenia netsh interface ip delete arpcache. To polecenie może wymagać uprawnień administratora.
W systemie Cisco IOS ze względu, że są to urządzenia sieciowe, mamy do dyspozycji kilka różnych poleceń poniżej (są one dostępne w trybie uprzywilejowanym EXEC):
- show running-config - wyświetla obecnie używaną konfigurację oraz ustawienia.
- show interface - wyświetla status interfejsów oraz ewentualne komunikaty o błędach.
- show ip interface - wyświetla informacje dla z warstwy 3 dla interfejsu.
- show arp - wyświetla tablice arp urządzenia.
- show ip route - wyświetla tablice routing urządzenia.
- show protocols - wyświetla listę dostępnych protokołów warstwy 3.
- show version - zwraca informacje o pamięci urządzenia, dostępnych interfejsach oraz licencji.
Innym wartym uwagi narzędziem jest protokół Cisco CDP,
z jego pomocą możemy z identyfikować inne urządzenia Cisco podłączone
do tego, na którym wydajemy polecenia tego protokołu. Ten protokół jest
nieroutowalny, tak więc zobaczymy urządzenia zajdujące się w tej samej
domenie rozgłoszeniowej. Aby sprawdzić z jakie są inne urządzenia
Cisco w naszej sieci należy wydać polecnie:
show cdp neighbors lub
show cdp neighbors detail.
W przypadku polecenia
show ip interface możemy dodać na
końcu jeszcze słowo kluczowe brief aby uzyskać więcej
informacji.
Zadanie praktyczne - Packet Tracer
Interpretacja wyjścia polecenia show - scenariusz Interpretacja wyjścia polecenia show - zadanie
1.17.6. Metodologia rozwiązywania problemów
Czasami może tak się zdarzyć, że coś nie będzie działać lub coś przestanie działać. Naszym zadaniem jest znalezienie usterki oraz jej usunięcie. Czasami nie jest takie proste jakby się mogło wydawać, i niektóre problemy mogą być bardziej lub mniej złożone, wiadome jest, że ile jest usterek to tyle samo może być sposób na ich usunięcie. Poniżej jednak znajduje się lista kroków, które wprowadzają nieco organizacji w metodologię rozwiązywania problemów i to nie tylko sieciowych.
- Zidentyfikuj problem - Tutaj możemy użyć wszelkich możliwych środków, które mogą przybliżyć nas do natury problemu. Istotna może być rozmowa z innymi użytkownikami.
- Określenie możliwych przyczyn problemu - po zidentyfikowaniu problemu, powinniśmy ustalić możliwe przyczyny jego powstania, co mogło i kiedy się stać, że ten problem wystąpił.
- Spróbuj potwierdzić swoje ustalenia - tutaj musimy ustalić, które z naszych przypuszeń powstania problemów, jest tą prawdziwą genezą usterki.
- Określ plan rozwiązania problemu oraz ustal właściwe rozwiązanie - skoro wiemy co spowodowało usterkę, to należy opracować rozwiązanie problemu oraz sposób w jaki to zrobimy, aby jeszcze nie pogorszyć sytuacji.
- Zweryfikuj poprawność wprowadzonych rozwiązań, wdróż rozwiązania zardcze - Po hipotetycznym pozbyciu się problemu musimy ustalić, czy naszy rozwiązanie działa i czy przypadkiem nie ma wpływu na inne rozwiązania. Warto również skonfrontować się z przyczyną problemu i wdrożyć odpowiednie środki zaracze, aby problem się nie powtarzał.
- Udokumentuj to - warto prowadzić bazę wiedzy lub chociaż notatki, wrazi gdyby podobny problem wystąpił gdzieś indziej.
Oczywiście zdaję sobie sprawę z tego, że nie zawsze uda się trzymać tego planu. Warto jednak moim zdaniem wziąć sobie do serca ostatnią zasadę. Właśnie dzięki niej ta strona w ogole powstała i dlatego też dalej ją prowadzę.
Drugą sprawą jest fakt, że pewnych problemów nie uda nam się rozwiązać, z różnych przyczyn. Warto mieć to na uwadze i poinformować o tym przełożonych oraz innych pracowników. Oszczędzimy sobie setek pytań o...
Cisco IOS posiada narzędzie, które może pomóc nam znaleźć problem lub
jego przyczynę, jednak należy traktować go jako ostatateczność. Do
dyspozycji mamy polecenie debug. Wprowadza ono
urządzenie w stan debugowania, przez co każdy pakiet jest analizowany,
a rozszerzeone komunikaty diagnostyczne o przychodzących pakietach jakie
zostały
przetworzone przez te urządzenie mogą pojawiać się na konsoli. Jednak
warto mieć to na uwadzę, że uruchomienie tego trybu spowoduje znaczne
spowolnienie transmisji przez nie, ponieważ przez większość czasu
będzie ono zajęte analizowaniem pakietów. Tryb debugowania włączamy
polecenie debug w trybie
uprzywilejowanym EXEC, a wyłączamy za pomocą polecenia
no debug.
1.17.7. Rozwiązania typowych problemów
Poniżej znalazły się rozwiązania typowych problemów jakie możemy napotkać nie tylko konfigurując małą sieć. Takie problemy mogą się pojawić zawsze gdy konfigurujemy czy urządzenie końcowe czy też urządzenie pośredniczące w komunikacji sieciowej.
Pierwszym z nich mogą być problemy z autonegocjacją interfejsów sieciowych oraz błedne przyjęte uzgodnie odnośnie kierunku transmisji (duplex). Tutaj najczęściej przyczną może być fatalnej jakość medium transmisjne, np. kabel UTP, źle zarobione końcówki RJ-45 lub uszkodzone urządzenie, które chcemy podłączyć. Urządzenia Cisco mogą wyłączać również porty, jeśli dochodzi na do błędów.
Następnym przypadkiem jest przypadek błędnej adresacji interfejsów.
Do rozwiązania tego problemu możemy wykorzystać poznane wcześniej
polecenia jak show ip interface brief.
Problem z brakiem łączności z internetem można powiązać z brakiem
lub błędnym przypisaniem adresu bramy do hosta. Za pomocą poleceń
ipconfig lub
show ip route w przypadku urządzeń
sieciowych. Warto również sprawdzić czy serwer DHCP dobrze ustawia
ten parametr.
Problemy z rozwiązywaniem nazw również mogą powodować błędnę adresy
w konfiguracji hostów. Tak jak we wcześniejszym przypadku serwer DHCP
może przydzielć adres serwera DNS, który już nie istnieje. W przypadku
systemów MS Windows, aby sprawdzić adres serwera DNS należy wydać
polecenie ipconfig /all do dyspozycji
mamy również takie narzędzie jak
nslookup
Laboratorium
Rozwiązywanie problemów z łącznością Projektowanie i budowanie sieci małej firmy
Zadanie praktyczne - Packet Tracer
Rozwiązywanie problemów z łącznością - scenariusz Rozwiązywanie problemów z łącznością_- zadanie Wyzwanie dotyczące rozwiązywania problemów - scenariusz Wyzwanie dotyczące rozwiązywania problemów - zadanie
Podsumowanie
W tym rodziale dowiedzieliśmy się w jaki sposób projektować małe sieci czy weryfikować konfigurację sieciową hostów znajdujących się nie tylko w małych sieciach, ale podłączonych do sieci ogólnie. Poznalismy również zasady jakim należy kierować się podczas chęci rozbudowy takiej małej sieci. Na koniec usystematyzowaliśmy swoją wiedze na temat metodologi rozwiązywania problemów oraz poznaliśmy scenariusze typowych błędów jakie możemy napotkać. Ten rozdział zamyka pierwszy moduł kursu Cisco CCNA.
Zadanie praktyczne - Packet Tracer
Zadanie podsumowujące umiejętności - scenariusz Zadanie podsumowujące umiejętności - zadanie
1. Egzamin próbny - ITN
Przed przystąpieniem do egzaminu finałowego, będziemy mogli a wręcz musieli podejść do egzaminu próbnego. Egzamin próbny jest bardzo podobny do egzaminy finalnego, gdyż jego zakres obejmuje całość przerobionego na kursie materiału. Wynikiem tego egzaminu jest wartość procentowa poprawnych odpowiedzi ze wszystkich 55 pytań, poniżej rozpisane zostały również wartości procentowe ze wszystkich działów, dzięki temu kursant wie co musi sobie powtórzyć przed przystąpieniem do finala. Egzamin ten niepodlega ocenie, to znaczy że nie dostaniemy informacji zwrotnej, z pokazanymi odpowiedziami, na które odpowiedziliśmy źle z zaznaczonymi odpowiedziami oraz jego wyniki nie jest brany do kryterium ukończenia modułu.
1. Egzamin finałowy - ITN
Egzamin finałowy może składać z testu, w którym do wyboru możemy mieć pytania jednokrotnego lub wielokrotnego wyboru wymagające 2 lub 3 odpowiedzi. Mogą również zdarzyć się zadania polegające na przyporządkowaniu słów kluczowych, terminów, a nawet adresów do poszczególnych pól, jakimś opisem. W przypadku adresów możemy mieć rownież polecenie, gdzie będzie trzeba przyporządkować do adresów opis w stylu adres broadcast podsieci 1. Mając podane adres np. hostów oraz maskę w notacji CIDR.
W pytanich wielkrotnego wyboru, istnieje pewnego rodzaju haczyk. Czy też zmuszenie zdającego do posiadania podstaw do zazanaczenia takich odpowiedzi (w postaci wiedzy), że jeśli zaznaczym jedną dobrą odpowiedź i jedną złą, to wówczas za całe to zadanie mamy 0 punktów. Dlatego też, jeśli niemamy pewności do pozostałych, a jednej jesteśmy pewnii to lepiej zaznaczyć tę jedną i iść dalej. Taki mechanizm, żeby nie zgadywać.
Ilość pytań na egzaminie wacha się między 50, a 60 pytaniami, na zdanie których mamy 2 i pół godziny. W tym egzaminie nie uświadczymy zadań praktycznych wykonywanych w Packet Tracerze, tak jak to miało miejsce w egzaminach cząstkowych.
Czy są szanse na zdanie egzaminu, bazując tylko na tym materiale? Jeśli czytelnik, nie posiada żadnej wiedzy na temat sieci to raczej w to wątpie. Materiał ten ma za zadanie jedynie odświeżenie wiedzy zdobytej podczas kursu. Coś na zasadzie intensywnego powtórzenia. Problemy również mogą mieć osoby posiadające już jakąś wiedzę oraz doświadczenie w praktycznej konfiguracji sieci. Wymaga się od zdającego, zmiany sposobu myślenia na rozumienia pewnych pojęć tak jak sobie życzy tego Cisco. Z jednej strony przygotowuje nas to pracy z konkretną technologią, jednak nie od dziś wiadomo, że raczej z jedną nie będziemy zawsze i wszędzie pracować. Dlatego też zapoznanie się z materiałamia dostępnymi na kursie może być wymagane.
1. Finałowy egzamin praktyczny - Packet Tracer - ITN
Egzamin praktyczy jest podobny do ćwiczeń, które wykonywaliśmy w trakcie tego kursu. W przypadku tegorocznego zdania możemy dostać podłączoną już sieć która wymaga konfiguracji. Ale zanim do niej przejdziemy dostajemy na początku zadanie z określeniem odpowiedniej adresacji. Na przykład 192.168.1.0/24 i wytyczne mówią, aby podzielić tę pulę na podsieci o X ilości hostów przy jak najmniejszym zmarnowaniu adresów. Np. 30 hostów w sieci i dla sieci powiedzmy administracji mamy wykorzystać 4-tą podsieć z tego podziału. Następnie od 5-tej podsieci, podzielić pule na jescze mniejsze zawierające 12 czy 14 hostów i dla sieci działu IT wykorzystać podsieć 7 czy 8. Z tych podsieci mogą być również wytyczne, aby wykorzystać ostatni adres dla interfejsu routera, następny, przedostatni dla przełącznika i na koniec dowolne, inne dla hostów w tej sieci. Tak wygląda adresacja IPv4 w przypadku IPv6, adresy są już przypisane w tabeli. Tabele należy uzupełnić, aby nie pogubić się podczas konfiguracji urządzeń. Nie uzupełniamy jej w zadaniu. Nie ma takiej możliwości. Tak się kończy krok pierwszy.
Krok drugi polega na skonfigurowaniu interfejsów hostów w sieciach. Dla IPv4 oraz IPv6. Nie jest on zbyt wymagających.
Krok trzeci polega na konfiguracji routera. Do konfiguracji możemy mieć:
- Nazwę urządzenia.
- Zabezpieczenie dostępu do urządzenia. Tj. zabezpieczenie połączeń konsolowych, zabezpieczenie trybu uprzywilejowanyego EXEC za pomocą szyfrowanego hasła. Hasła musimy wymyśleć sami. Tutaj należy pamiętać o banerze. Warto zabepieczyć je jak najbardziej się da, najwyżej, niektóre z poleceń nie zostaną ocenione.
- Zaszyfowanie haseł.
- Ustawienie min. 10 znaków dla nowych haseł.
- Konfigurację dostępu przez SSH, przy czym może być informacja sugerująca utworzenie klucza RSA, ale nie będzie informacji na temat domeny. Bez tej informacji klucz nie zostanie utworzym. W tym celu musimy wykonać wszystkie kroki, aby to polecenie wykonało się poprawnie.
- Utworzyć użytkownika w lokalnej bazie na podstawie informacji podanych w zadaniu oraz użycie lokalnej bazy uwierzytelniania użytkowników łączycych się po SSH.
- Na koniec należy skonfigurować interfejsy w raz z ich podniesiem oraz z opisem description. Tutaj ważne może być włącznie routingu dla IPv6.
Krok czwarty (prawdopodobnie ostatni) polega na konfiguracji przełącznika i przy czym ta konfiguracja jest banalna. Musimy skonfigurować go do dostępu za pomocą protokołu Telnet z możliwością połączenia się z nim z innej sieci (tej drugiej) niż lokalna.
Ostatnią rzeczą jaką należy wykonać przed złożeniem zadania, jest sprawdzenia łączności oraz czy faktycznie mamy możliwość połączenia się z przełącznikiem po przez Telnet z sieci zdalnej.
W trakcie egzaminy praktycznego mamy zablokowane zakładki CLI lub w ogóle dostęp do urządzeń z poziomu osobnego okna Packet Tracera. Z urządzeniami należy łączyć się poprzez dowolnego hosta korzystając z połaczenia szeregowego oraz terminala. Egzamin ten oraz jego scenariusz jest tylko i wyłącznie w języku angielskim.
Koniec modułu pierwszego
Słowem wstępu
Po zdaniu egzaminu, kontunuacja w takiej jak dotychczas formie kursu Cisco CCNA, zawisła na włosku. No i z niego spadła. Z grupy wypisały 3 osoby, a rektor wydziału nie pozwolił wykładowcy na kontynuację kursu. Zostalismy bowiem z jednym modułem...
Nie mniej jednak dwa dni poźniej jeden z kolegów z kursu, znalazł kurs CISCO CCNA w innym mieście. Taniej, ale jednak trzeba dojechać. Pomijając inne aspekty. Kurs będzie kontynuowany, w innym miejscu i ja już wiem, że trochę z innym podejściem. Co na minus, ale tutaj liczy się dostęp do materiałów oraz możliwość zaliczenia kolejnych semestrów (modułów).
2. Moduł 2: Podstawy przełaczania, routingu oraz sieci bezprzewodowych - SRWE
Moduł drugi czyli podstawy przełączania, routingu oraz sieci bezprzewodowych. Na tym etapie zapozanymy się z takimi technikami sieciowymi jak VLAN-y, agregacja łącza, podstawy łączności bezprzewodowej oraz statyczny routing. Tematy te już są bardziej zaawansowane niż to co mogliśmy spotkać w poprzednim module. Pierwsze dwa tematy będą przypomnieniem sobie kilku zagadnień z poprzedniego modułu.
2.1. Podstawowa konfiguracją urządzenia
Każde dostaczone urządzenie zawiera już jakąś konfigurację. Bez tego nie mogło by działać. Oczywiście ta konfiguracja ma z zadanie przygotować urządzenie do pracy i umożliwić dostosowanie go do obecnych potrzeb. Przy okazji przypominy sobie część poleceń jakie do tej pory poznaliśmy. Rozszerzymy wiedzę zawartą w podstawowej konfigurację przełącznika oraz routera o kilka nowych informacji.
Wiekszość urządzeń techniki komputerowej, niezależnie od tego jak prymitywne one nie są i jakie realizują zadania, oparto o schemat działania ówczesnych komputerów. Podobnie w przypadku przełączników firmy Cisco, są one prymitywnymi komputerami zawierającymy duże ilości kart sieciowych (mniej więcej).
Przełączniki nie posiadają nawet włącznika. Startuje zaraz podaniu zasilania. Zamysł takiego projektu przełącznika opiera się na tym, że ten sprzęt powinien zostać zasilony i działać do momentu swoje żywota.
- Po podłączeniu zasialania przełącznik przeprowadza procedurę POST, w której oprócz podstawowych komponentów takich jak CPU czy RAM sprawdzany jest także stan systemu plików, w który zawiera system operacyjny przełącznika.
- Przełącznik ładuje z pamięci ROM program ładujący (bootloader), uruchamiany jest on w momencie pozytywnego przejścia procedury POST.
- Program ładujący przy urzyciu procesora przygotowuje pamięc.
- Bootloader montuje system plików znajdujący się dysku flash w przełączniku.
- Na końcu bootloader, odszukuje na powyższej pamięci obraz IOS i uruchamamia go i przekazuje mu kontrolę nad urządzeniem.
Jak w przypadku większości komputerów, czy to mniej lub bardziej
prymitywnych możemy kontrolować ich rozruch, jednym ze sposobów zmiany
sekewncji startowej urządzenia jest uzycie odpowiednich poleceń
systemu IOS.
Polecenie boot system służy do
ustawienia zmiennej środowiskowej BOOT. Przechowuje ona bowiem ścieżkę
wskazującą na plik z system operacyjnym w tym wypadku z IOS. Jeśli
takiej zmiennej będzie brakować w systemie, wówczas program ładujący
uruchomi pierwszy napotkany plik wykonywalny. Dostęp do zmiennej BOOT
możemy uzyskać po przez polecenie
show boot. Poniżej przykład.
Switch#sh boot
BOOT path-list :
Config file : flash:/config.text
Private Config file : flash:/private-config.text
Enable Break : no
Manual Boot : no
HELPER path-list :
Auto upgrade : yes
NVRAM/Config file
buffer size: 65536
Jak wydzimy na powyższym przykładzie, przełączniki domyślnie nie mają ustawionego, żadnego pliku z systemem operacyjnym. Korzystają z możliwości przeszukiwania pamięci flash i użycia pierwszego napotkanego pliku wykonywalnego. W celach przezentacji wykorzystałem emulowany przełącznik z programu PacketTracer, w przypadku urządzeń fizycznych, możemy mieć zdefiniowaną domyślną ścieżkę do pliku z systemem, ponieważ na przestrzeni lat działania, w pamięci flash może znajdować się kilka, takich plików. Spróbujmy teraz ustawić opisywany tutaj parameter i ponownie wyświelimy informację o rozruchu.
Switch#dir flash:
Directory of flash:/
1 -rw- 4670455 <no date> 2960-lanbasek9-mz.150-2.SE4.bin
Switch(config)#boot system flash:/2960-lanbasek9-mz.150-2.SE4.bin
Switch#sh boot
BOOT path-list : flash:/2960-lanbasek9-mz.150-2.SE4.bin
Config file : flash:/config.text
Private Config file : flash:/private-config.text
Enable Break : no
Manual Boot : no
HELPER path-list :
Auto upgrade : yes
NVRAM/Config file
buffer size: 65536
Na początku wyświetliłem zawartość pamięci flash, aby sprawdzić
dokładną nazwę pliku z obrazem systemu, następnie użyłem polecenia
boot system jak parametr polecenia
podałem scieżkę z lokalizacją pliku z system operacyjnym. Na koniec
ponownie wyświetliłem informacje rozruchowe i w pierwszym wierszu
widzimy naszą wskazaną ścieżkę.
Przełączniki serii Catalist (powszechnie używane modele) firmy Cisco, nie posiadają wyświetlaczy, a jedynie zestaw diód nad portami oraz diody z lewej strony urządzenia na odrębnym panelu. Na tym panelu również znajduje się jedyny przycisk tego urządzenia. Przełącznik tak jak już może wspomniałem albo nie, nie posiadają wyłącznika. Cisco zakłada, że raz podłączony przełącznik ma działać do momentu, aż się nie uszkodzi. Ten nie pozorny zestaw diód, może nam zdradzić znacznie więcej informacji, niż inne przełączniki, innych firm również wyposażone w diody prezentujące stan oraz aktywność poszczególnych portów.
Diody w urządzeniach Cisco, mają 5 stanów: wyłączony - dioda się nie swieci, zielony stały - dioda swieci się na kolor zielony, pomarańczowy stały - dioda swieci się na kolor pomarańczowy, zielony migający - dioda miga kolorem zielonymm, pomarańczowy migający - dioda miga kolorem pomarańczowym.
Za pomocą przycisku MODE, wybieramy jeden z trybów informacyjnych, przezentowany za pomocą diód LED nad portami, sam wybrany tryb również jest sygnalizowany za pomocą diód nad przyciskiem po lewej stronie urządzenia. Omówimy sobie te diody po kolei:
- SYST - dioda wskazuje na stan zasilania. Jeśli dioda jest wyłączona, oznacza to, że urządzenie najzwyczajniej w świecie niedziała i nie dochodzi do niego zasilanie. W przypadku normalnej pracy dioda świeci na zielono, natomiast jeśli przełącznik będzie mieć awarię, wówczas będzie to sygnalizować ta dioda w kolorze pomarańczowym.
- RPS - dioda nadmiarowego zasilania (ang. Redundant Power Supply). Dioda wskazuje stan zasilania RPS, jeśli jest ona: wyłączona - oznacza to, że RPS jest wyłączony lub nie jest podłączony prawidłowo; zielona stała - RPS jest podłączony i gotowy do zapewnienia zasilania awaryjnego; zielona miga - RPS jest podłączony, ale jest niedostępny, ponieważ zasila inne urządzenie; pomarańczowa stała - RPS jest w trybie gotowości lub w stanie błędu; pomarańczowa miga - wewnętrzne źródło zasilania uległo awarii, a RPS dostarcza energię.
- STAT - dioda statusu portu. Ta dioda na panelu, zawsze ma kolor zielony stały. Natomiast wybranie tego trybu powoduje modyfikację informacji zwracanych przez diody nad portami. Po wybraniu tego trybu, diody nad portami będą: wyłączone - port nie ma fizycznego połączenia lub został wyłączony przez administratora; zielone stałe - jest połączenie fizyczne (ten stan jest przejściowy występuje przez kilka, kilkanaście sekund); zielone migające - połączenie tego portu jest aktywne, wysyła i odbiera dane; migać naprzemiennie zielony, pomarańczowy - oznacza to błąd połączenia; pomarańczowe stałe - porty zablokowane (ten stan występuje prawie zawsze podczas uruchamiania urządzenia przez ok. 30 sek.); pomarańczowe migające - porty są zablokowane, aby zapobiec możliwej pętli. Tryb ten, często jest domyślny trybem urządzenia.
- DUPLX - dioda dupleksu portu, gdy ta dioda na panelu jest zielona, to wówczas diody nad portami będą wskazywać ustawiony tryb dupleksu danego portu. Jeśli dioda nad portem jest: wyłączona - oznacza to, że port działa w trybie Half-duplex, a jeśli jest zielona - to w trybie Full-duplex.
- SPEED - dioda prędkości portu. Jeśli ten tryb jest włączony, to wówczas diody nad portami mogą być: wyłączone - port działa z prędkością 10Mb/s; zielone stałe - port przesyła dane z prędkością 100Mb/s; zielone migają - port przesła dane z prędkością 1000Mb/s, 1Gb/s.
- PoE (nie dotyczy wszystkich urządzeń) - dioda zasilania przez Ethernet (technologii PoE). W przypadku PoE to dioda trybu może być: wyłączona - żaden z portów nie jest zasilany lub jest w trybie uszkodzenia; pomarańczowa migająca - że tryb PoE nie został wybrany, ale co najmniej jednemy portowi nie dostarczono zasilania lub wystąpił błąd PoE. Zielona - tryb PoE został wybrany, wówczas diody portów są wyłączone - to oznacza, że PoE jest wyłączone; zielone stałe - PoE jest włączone. Migają naprzemiennie zielony, pomarańczowy - PoE jest niedostępne, ponieważ zapotrzebowanie podłączonego urządzenia przewyższa możliwości przełącznika; pomarańczowe migają - PoE jest w stanie awarii; pomarańczowe stałe - tryb PoE dla portu został wyłączony.
Z tych trybów i przełączania się między nimi, może wyniknąć dość zabawna sytuacja. Otóż podczas przepinania przewodów, możemy omyłkowo naciśnąć przycisk MODE i zmienić tryb. W szczególności pod STAT-em (domyślnym trybem) jest informacja o dupleksie. Patrząc po tem na porty, możemy uznać, że przełacznik się zawiesił. Zanim jednak odłączym go od prądu, naciśnijmy przycisk MODE kilka razy. Zawieszony przełącznik nie mógł by zmienić trybów.
Jednym z celów, dla których uczestniczymy w kursie CCNA jest poznanie możliwości wykorzystania sprzętu firmy Cisco, więc jeśli pracujemy na sprzęcie, to czasami może zdarzyć się potrzeba przywrócenia go do ustawień fabrycznych, przyczym nie wygląda to tak jak w przypadku zwykłych urządzeń klasy SOHO.
W pierwszym module na pewno słyszeliśmy, że urządzenia firmy Cisco
są wyposażone
w pamięć NVRAM, w której przechowywana jest konfiguracja. Jest to
prawdą,
połowicznie. To stwierdzenie jest prawdziwe w przypadku gdy mówimy
o routerach. Przełączniki przy najmniej te serii Catalist
nie mają takich udogodnień jak NVRAM. Tam zastosowano pamięć
flash, którą mogliśmy się zetknąć podczas omawiania polecenia
boot system. Tam mimo tego, że do
kopii konfiguracji wykorzystaliśmy nazwę startup-config, to
ten rodzaj konfiguracji jest przechowany w pamięci flash pod
nazwą config.text. I to on będzie celem naszej operacji.
- Odłączamy od urządzenia zasilanie, a podłączamy konsole.
- Przytrzymując przycisk MODE, podłączamy zasilanie. trzymamy tak długo, aż dioda SYST nie mignie na pomarańczowo. Wtedy puszczamy przycisk.
- Na konsoli zostanie wyświetlonych kilka informacji, z możliwymi
opcjami do wprowadzenia oraz promptem:
switch:. Jeśli nie ma opcji to wówczas możemy wpisać znak zapytania (?) i wtedy zostanie nam wyświetlona lista.switch: ? ? -- Present list of available commands boot -- Load and boot an executable image delete -- Delete file(s) dir -- List files in directories flash_init -- Initialize flash filesystem(s) help -- Present list of available commands rename -- Rename a file reset -- Reset the system set -- Set or display environment variables unset -- Unset one or more environment variables - Tryb edycji wiersza poleceń, w tym przypadku jest bardzo prymitywny
nie mamy do dyspozycji strzałek czy dopełnienia. Musimy uważnie
wpisywać polecenia. Zaczniemy od zamontowania systemu plików na
pamięci flash.
switch: flash_init Initializing Flash... flashfs[0]: 2 files, 0 directories flashfs[0]: 0 orphaned files, 0 orphaned directories flashfs[0]: Total bytes: 64016384 flashfs[0]: Bytes used: 4671638 flashfs[0]: Bytes available: 59344746 flashfs[0]: flashfs fsck took 1 seconds. ...done Initializing Flash.
- Teraz za pomocą polecenia dir i podania mu urządzenia
w tym przypadku jest pamięć flash, może przejrzeć zawartość
tej pamięci.
switch: dir flash: Directory of flash:/ 1 -rw- 4670455
2960-lanbasek9-mz.150-2.SE4.bin 2 -rw- 1183 config.text 59344746 bytes available (4671638 bytes used) - Teraz w zależności od awarii, albo kasujemy plik
config.text, albo ustawiamy zmienną BOOT, aby wybrać
właściwy obraz systemu operacyjnego.
switch: delete flash:config.text Are you sure you want to delete [flash:config.text] (y/n)?y File "flash:config.text" deleted
W drugim przypadku definiujemy, zmienną BOOT, a jej ustawienie możemy zweryfikować za pomocą poleceniasetswitch: BOOT=flash:2960-lanbasek9-mz.150-2.SE4.bin switch: set BOOT=flash:2960-lanbasek9-mz.150-2.SE4.bin
- Po wykonaniu pożądanej czynności może przejść już do uruchomienia
przełącznika. Za pomocą polecenia
boot.switch: boot C2960 Boot Loader (C2960-HBOOT-M) Version 12.2(25r)FX, RELEASE SOFTWARE (fc4) Cisco WS-C2960-24TT (RC32300) processor (revision C0) with 21039K bytes of memory. 2960-24TT starting... Base ethernet MAC Address: 000D.BDB0.4E5E Xmodem file system is available. Initializing Flash... flashfs[0]: 1 files, 0 directories flashfs[0]: 0 orphaned files, 0 orphaned directories flashfs[0]: Total bytes: 64016384 flashfs[0]: Bytes used: 4670455 flashfs[0]: Bytes available: 59345929 flashfs[0]: flashfs fsck took 1 seconds. ...done Initializing Flash. Boot Sector Filesystem (bs:) installed, fsid: 3 Parameter Block Filesystem (pb:) installed, fsid: 4 Loading "flash:/2960-lanbasek9-mz.150-2.SE4.bin"... ########################################################################## [OK]
Uruchamiając przełącznik w trybie opisanym powyżej, przechodzimy do czegoś, co można porównać do trybu awaryjnego.
Reguła ta nie tyczy się tylko przełączników, ale i większości urządzeń firmy Cisco. Te urządzenia nie są skonfigurowane, do zdalnego zarządzania. Pierwsza konfiguracja wymaga dostępu fizycznego do urządzenia użycia interfejsu konsoli. Jeśli kupujemy nowe urządzenia to kabel konsolowy będzię w zestawie. Problemem może okazać dostępność portów COM w obecnych komputerach. W przypadku komputerów stacjonarnych możemy jeszcze je spotkać, ale w nowych laptopach to głównie w seriach tych wzmanianych. Remedium dla tego problemy jest za opatrzenie się w adapter USB - RS232, dostępne są one za parę złotych na serwiach aukcyjnych czy sklepach internetowych.
Bawiąc się przełącznikami w porzednim module, wykorzystwaliśmy domyślny VLAN 1, jako SVI. Jednak ze względów bezpieczeństwa nie jest to dobrym rozwiązaniem. Dlatego zmienimy trochę koncepcję. Ten podrozdział wystarczy sobie przeczytać, ponieważ realizacja przykładu będzie wymagać nieco więcej wiedzy, którą poznamy w poźniejszym etapie tego kursu. Poniżej znajduje się lista poleceń, która jest już raczej znana:
S1> S1>enable S1#configure terminal Enter configuration commands, one per line. End with CNTL/Z. S1(config)#interface vlan 99 S1(config-if)#ip address 172.17.99.11 255.255.255.0 S1(config-if)#ipv6 address 2001:db8:acad:99::1/64 S1(config-if)#no shutdown S1(config-if)#end S1#copy running-config startup-config Destination filename [startup-config]? Building configuration... [OK]
Uwaga! Aby móc wpisać adres IPv6 przełącznikowi, należy na początek skonfigurować w nim IPv6. Nie jest to skomplikowana czynność. Wymaga podania jednego polecenia w trybie konfiguracji globalnej oraz uruchomienia ponownie urządzenia. Poniższe polecenia przedstawią co trzeba zrobić.
S1# %SYS-5-CONFIG_I: Configured from console by console S1#configure terminal Enter configuration commands, one per line. End with CNTL/Z. S1(config)#sdm prefer dual-ipv4-and-ipv6 default Changes to the running SDM preferences have been stored, but cannot take effect until the next reload. Use 'show sdm prefer' to see what SDM preference is currently active. S1(config)#do reload
W ostatnim poleceniu użyto polecenia
do reload, przerostek
do pozwala na uruchamianie poleceń
bez względu na tryb. Oczywiście nie takich specyficznych dla danego
trybu. Dzięki nie mu możemy uzyskać dostęp do polecenia
show np. podczas konfigurowania
interfejsu. Taki pro tip.
Jeśli nasz przełącznik będzie znajdować się w innej podsieci to do komunikacji z nim wykorzystamy bramę, ale on sam musimy mieć wpisany adres bramy. Poniżej znajduje się seria poleceń, służąca konfiguracji bramy na urządzeniach Cisco.
S1#configure terminal Enter configuration commands, one per line. End with CNTL/Z. S1(config)#ip default-gateway 172.17.99.1 S1(config)#end S1# %SYS-5-CONFIG_I: Configured from console by console S1#copy running-config startup-config Destination filename [startup-config]? Building configuration... [OK]
Ćwiczenie praktyczne - Laboratorium
Podstawowa konfiguracja przełącznika
2.1.2. Konfiguracja portów przełącznika
Pomimo tego, że portom na przełącznikach, nie ustawia się adresu IP to można skonfigurować kilka innych parametrów i to tym się zajmmiemy w w tym podrozdziale.
Konfigurację portów rozpoczniemy od skonfigurowania warstwy fizycznej, a w niej znajdują się takie pojęcia jak dupleks - rodzaj transmisji umożliwiający dwukierunkową transmisję danych, w którym mamy dwie możliwości: full-dupleks - umożliwiający odbierania i nadawanie jednocześnie oraz half-dupleks - umożliwiający jedynie nadawanie lub odbieranie. Obecnie nie stosuje się pół-dupleksu i urządzenia zazwyczaj działają w trybie pełnego dupleksu. Jeśli urządzenie przestawia się w tryb pół-dupleksu, to zazwyczaj oznacza to, że ma uszkodzoną kartę sieciową, albo jest naprawdę stare.
Co więcej gigabitowy i 10Gb Ethernet wymagają pełnego dupleksu. W tym trybie wyłączony jest obwód detekcji kolizji na karcie sieciowej.
Poza dupleksem w warstwie fizycznej występuje jeszcze nominalna prędkość z jaką pracuje port - 1Gb/s, 100Mb/s czy 10Mb/s. Te omawaiane funkcję są możliwe do ustawienia w trybie konfiguracji interfejsów.
Switch#configure terminal Enter configuration commands, one per line. End with CNTL/Z. Switch(config)#interface FastEthernet 0/1 Switch(config-if)#duplex full Switch(config-if)#speed 100 Switch(config-if)#end
Na szczęście nie musimy tego robić, a wręcz nie powiniśmy. Istnieją mechanizmy autonegocjacji tych parameterów, a nie poprawna konfiguracja dupleksu, może spowodować problemy z połączeniem między przełącznikiem, a urządzeniem.
Inną funkcją warstwy fizycznej jest auto-MDIX, czyli automatyczne
ustalenie potrzebnego rodzaju kabla i wykonanie przeplotu jeśli to
konieczne już w samym porcie urządzenia. Funkcję możemy wyłączyć
za pomocą polecenia: mdix auto, w
trybie konfiguracji interfejsu. Jednak to też jedna z tych domyślnie
włączonych funkcji w przełącznikach serii 2960 (powszechnie stosowany
model) oraz 3560 (przełącznik L3) posiadają tę opcję włączoną.
Natomiast ich starsze odpowiedniki nie posiadają tej funkcjonalności
wcale, więc tutaj będzie wymagane stosowanie odpowiednich kabli.
Poniżej znajduje się lista poleceń wykorzystywana do weryfikacji przełącznika:
- Wyświetlenie informacji o stanie i konfiguracji interfejsu -
S1# show interfaces [id interfejsu] - Wyświetla konfigurację startową -
S1# show startup-config. - Wyświetla bieżącą konfigurację -
S1# show running-config. - Wyświetla informacje o systemie plików pamięci flash -
S1# show flash - Wyświetla status sprzętu i oprogramowania -
S1# show version - Wyświetla historię wprowadzonych poleceń -
S1# show history - Wyświetla informacje związane z adresem IP interfejsu -
S1# show ip interface [id interfejsu]lubS1# show ipv6 interface [id interfejsu] - Wyświetla tablicę adresów MAC przełącznika -
S1# show mac-address-tablelubS1# show mac address-table
Przypomnijmy sobie wyjście polecenia
S1# show ip interface brief, ostatnie
dwie kolumny wkazywały na status portu. Pierwsza kolumn
Status pokazywała nam status połączenia w warstwie fizycznej
(1), natomiast druga kolumna Protocol, wskazywała czy
urządzenia dogadują się na poziomie warstwy łącza danych (2).
W niektórych przypadkach, możemy spotkać się z takim stanem jak
up/down, oznacza to, coś jest nie tak w warstwie drugiej.
Często tego typu przypadki mają miejsce w przypadku łączy szeregowych,
jednak w jest to najczęsciej związane z nieustawieniem zegara.
Więcej informacji na ten temat może z wrócić nam polecenie
show interface [id-interfejsu]
Switch#show interface FastEthernet0/1
FastEthernet0/1 is up, line protocol is up (connected)
Hardware is Lance, address is 00e0.f9d0.6101 (bia 00e0.f9d0.6101)
BW 100000 Kbit, DLY 1000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, 100Mb/s
input flow-control is off, output flow-control is off
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:08, output 00:00:05, output hang never
Last clearing of "show interface" counters never
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue :0/40 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
956 packets input, 193351 bytes, 0 no buffer
Received 956 broadcasts, 0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort
0 watchdog, 0 multicast, 0 pause input
0 input packets with dribble condition detected
2357 packets output, 263570 bytes, 0 underruns
0 output errors, 0 collisions, 10 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffers swapped out
Pierwsza linia wyjścia polecenia zwraca nam te informacje o których mówiłem wcześniej. Port jest w stanie up/up. Jeśli jednak byłby w stanie up/down, to warto spojrzeć na informacje w licznikach na końcu danych wyjściowych. Mamy tam wiele informacji, np. takich o wielkości ramek (runts - za małych, giants - za dużych) o błedach w CRC (CRC), poniżej znajduje się informacje na temat kolizji (collisions, late collisions). Informacje na ten temat mogą być pomocne, w diagnozowaniu stanu up/down.
2.1.3. Bezpieczny zdalny dostęp
Pracując przy administracji sieciami komputerowymi, może zdażyć się taka sytuacja, że trzeba będzie skonfigurować urządzenia, do których dostęp fizyczny, aby podłączyć się konsolą może być utrudniony lub w ogóle niedostępny. Na szczęście urządzenia firmy Cisco zapewniają zdalny dostęp swoich urządzeń. To powinniśmy pamiętać z poprzedniego modułu.
Do wyboru mamy przestarzały Telnet (23/TCP), który nie zapewnia bezpieczeństwa transmisji, nie szyfruje przesłanych za jego pośrednictwem informacji. Raczej nie jest już stosowany.
Inną opcją jest użycie lepszego protokołu, jakim jest SSH (ang. Secure SHell). SSH wykorzystuje silną krytpografię do zabezpieczenia transmisji pomiędzy naszym komputerem, a urządzeniem. Jeśli używamy protokołu SSH w wersji 2, szanse na podsłuchanie transmisji, są nie mal, że nikłe. SSH wykorzystuje transmisję protokołu TCP na porcie 22.
Nie wspominałbym gdyby nie to, że nie wszystkie urządzenia posiadają obsługę kryptografii - przez co SSH może być dostępne. Jak to sprawdzić? Otóż obsługę kryptografii możemy poznać po nazwie pliku z systemem operacyjnym jeśli w nazwie pliku występuje sekwencja k9 oznacza to, że w wersji IOS dla tego urządzenia zaimplementowano kryptografię, a co za tym idzie i obsługę SSH. Poniżej przedstawiam listing zawartości pamięci flash z urządzeń, które mają możliwość wykorzystać SSH oraz takich, w których nie ma takiej możliwości (wg. powyższej zasady).
# Przełącznik Catalyst 2960:
Switch#dir flash:
Directory of flash:/
1 -rw- 4670455 <no date> 2960-lanbasek9-mz.150-2.SE4.bin
64016384 bytes total (59345929 bytes free)
# Przełącznik Catalist 2950:
Switch#dir flash:
Directory of flash:/
1 -rw- 3058048 <no date> c2950-i6q4l2-mz.121-22.EA4.bin
64016384 bytes total (60958336 bytes free)
W przypadku pierwszego przełącznika, sekwencja k9 znajduje się
w drugiej części nazwy pliku po ciągu znaku
lanbase. Inny sposobem na sprawdzenie
nazwy pliku z IOS jest wydanie polecenia
show version.
Uruchomienie SSH, było w podkoniec zeszłego modułu, ale, żeby ten
moduł był kompletny, przypmnimy sobie jak się to robi. Na początek
wydamy sobie polecenie: show ip ssh.
W przypadku urządzenie ze wsparciem kryptograficznym odpowiedź powinna
być następująca:
Switch#show ip ssh SSH Disabled - version 1.99 %Please create RSA keys (of atleast 768 bits size) to enable SSH v2. Authentication timeout: 120 secs; Authentication retries: 3
A jeśli polecenie wydamy na urządzeniu, które nie ma takich funkcji (wg. opisywanej wcześniej zasady), jego odpowiedź będzie następująca:
Switch#dir flash:
Directory of flash:/
1 -rw- 3058048 <no date> c2950-i6q4l2-mz.121-22.EA4.bin
64016384 bytes total (60958336 bytes free)
Switch#show ip ssh
SSH Enabled - version 1.99
Authentication timeout: 120 secs; Authentication retries: 3
Generalnie pomysł z rozponawaniem możliwości kryptograficznych wersji IOS po nazwie pliku, nie jest złym pomysłem. Jest nowym pomysłem, ale jego twórca, prawdopodobnie zapomniał, że wcześniej istniał inny sposób. Dlatego też, nie warto tracić czasu na analizę nazwy pliku. Najlepiej od razu powyższe polecenie. W urządzeniach z obsługą SSH oraz silnej kryptografii, zwróci na ono takie informacje na jak na powyższych przykładach. Jeśli takiego wsparcia nie będzie, to wówczas to polecenie nie zostanie rozpoznane w ogóle.
Wracając do konfiguracji SSH. Musimy ustawić nazwę hosta oraz nazwę domeny.
Switch(config)#hostname C2950 C2950(config)# C2950(config)#ip domain-name example.com
SSH w wersji 1, zawiera znane podatności i nie jest już wykorzystywane,
ani rozwijane. Więc aby użyć tej lepszej - 2 wersji SSH, musimy
wygenerować nową parę kluczy, o długości co najmniej 768 bitów, aby
móc włączyć SSH 2. Sugeruje nam to nawet informacja zwraca przez
polecenie show ip ssh:
%Please create RSA keys (of atleast 768 bits size) to enable SSH v2.
Aby wygenerowac parę kluczy, wydajemy poniższe polecenie w trybie
konfiguracji globalnej. Polecenie po uruchomieniu zapyta się o długość
klucza. Generalnie przyjęło się, że taką dolną bezpieczną granica są
klucze o długości 1024 bitów. Chociaż obecnie skłaniamy się do
tworzenia dwa razy dłużyszch kluczy - 2048 bitów. Ze względu na
powszchną dostępność dużej mocy obliczeniowej, tak krótkie klucze mogą
nie wystarczać. Jednak należy pamiętać, że dłuższy klucz spowoduje
większe obciążenie procesora urządzenia. Decyzja należy do nas.
C2950(config)#crypto key generate rsa The name for the keys will be: C2950.example.com Choose the size of the key modulus in the range of 360 to 4096 for your General Purpose Keys. Choosing a key modulus greater than 512 may take a few minutes. How many bits in the modulus [512]: 1024 % Generating 1024 bit RSA keys, keys will be non-exportable...[OK] C2950(config)#
Powyższe informacje, tak jak nazwa host oraz domeny, służą do nazwania pary kluczy. SSH wymaga do uwierzytelniania nazwy użytkownika oraz hasła. Urządzenia Cisco mogą do uwierzytelniania wykorzystać specjalny serwer (RADIUS), lub lokalną bazę danych. Dla celów szkoleniowych wykorzystamy lokalną bazę danych. Utworzymy użytkownika admin z hasłem ccna. W trybie konfiguracji globalnej wydajmy poniższe polecenie.
C2950(config)#username admin secret ccna
Teraz możemy skonfigurować linie VTY, przełączniki Catalyst 2950 mają zakres tych linii od 0 15. Aby skonfigurować linie VTY, tak aby używały SSH wydajemy poniższe polecenia w trybie konfiguracji globalnej oraz w trybie konfiguracji linii.
C2950(config)#line vty 0 15 C2950(config-line)#transport input ssh C2950(config-line)#login local C2950(config-line)#exit
Na koniec pozostaje nam wymusić wersję 2 protokołu SSH. Za pomocą poniższego polecenia wydane w trybie konfiguracji globalnej:
C2950(config)#ip ssh version 2
Przełączenie wersji, możemy zweryfikować za pomocą polecenia
show ip ssh. Przed wymuszeniem wersja
była 1.99, a obecnie jest:
C2950#show ip ssh SSH Enabled - version 2.0 Authentication timeout: 120 secs; Authentication retries: 3
Weryfikacji działania SSH, możemy dokonać próbując się podłączyć,
przy użyciu PuTTY lub innego klienta SSH. Obecnie są one wbudowane
we większość systemów operacyjnych. Połączenia SSH na urządzeniach
Cisco możemy sprawdzić za pomocą polecenia
show ssh.
Ćwiczenie praktyczne - Packet Tracer
Konfiguracja SSH - scenariusz
Konfiguracja SSH - zadanie
2.1.4. Podstawowa konfiguracja routera
Do tej pory skupialiśmy się głównie na przełącznikach, teraz zajmiemy się routerem. Konfigurację routera, możemy podzielić na dwie części część pierwsza skupia się głównie na konfiguracji i podstawowym zabezpieczeniu systemu operacyjnego, bez konfiguracji interfejsów sieciowych. Część druga skupia się na właśnie na tej części sieciowej, ustawieniu interfejsów oraz ewentualnie tras.
Pierwszą część wałkowaliśmy na pierwszym module, drugą również dlatego przedstawię je w postaci zwięzłego bloku kodu, jeśli coś będzie wymagało wyjaśnienia to umieszcze je pod nim.
Router>ena Router#configure terminal Enter configuration commands, one per line. End with CNTL/Z. Router(config)#hostname R1 R1(config)#enable secret class R1(config)#line console 0 R1(config-line)#password cisco R1(config-line)#login R1(config-line)#exit R1(config)#line vty 0 4 R1(config-line)#password cisco R1(config-line)#login R1(config-line)#exit R1(config)#service password-encryption R1(config)#banner motd # Nieautoryzowany dostep jest zabroniony! # R1(config)#end R1# %SYS-5-CONFIG_I: Configured from console by console R1#copy running-config startup-config Destination filename [startup-config]? Building configuration... [OK]
Innym dość ważnym zadaniem podczas egzaminu może być ustawienie
aktualnej daty i czasu na urządzeniu. Dokonujemy tego za pomocą
polecnia clock set w
trybie uprzywilejowanym.
R1#clock set 18:20:00 6 Jul 2024
Myślę, że te powyższe proste polecenia nie wymagają dodatkowego omówienia. Teraz zajmiemy się częścią sieciową. Na kursie CCNA będziemy operować na podwójnym stosie IP - dla IPv4 oraz IPv6 i w taki sposób skonfigurujemy nasze interfejsy sieciowe. Na początku warto się rozejrzeć, jakie interfejsy mamy dostępne w naszym urządzeniu.
Nieautoryzowany dostep jest zabroniony! User Access Verification Password: Password: R1>ena Password: R1#show ip interface brief Interface IP-Address OK? Method Status Protocol GigabitEthernet0/0 unassigned YES NVRAM administratively down down GigabitEthernet0/1 unassigned YES NVRAM administratively down down Serial0/0/0 unassigned YES unset down down Serial0/0/1 unassigned YES unset down down Vlan1 unassigned YES NVRAM administratively down down R1#
Kiedy już mniej więcej wiemy gdzie co ma być podłączone, możemy przejść do właściwej konfiguracji portów.
R1#configure terminal Enter configuration commands, one per line. End with CNTL/Z. R1(config)#interface gigabitethernet 0/0 R1(config-if)#ip address 192.168.10.1 255.255.255.0 R1(config-if)#ipv6 address 2001:db8:acad:1::1/64 R1(config-if)#description LAN1 R1(config-if)#no shutdown R1(config-if)# R1(config-if)#exit R1(config)#interface gigabitethernet 0/1 R1(config-if)#ip address 192.168.11.1 255.255.255.0 R1(config-if)#ipv6 address 2001:db8:acad:2::1/64 R1(config-if)#description LAN2 R1(config-if)#no shutdown R1(config-if)#exit R1(config)#interface Serial 0/0/0 R1(config-if)#ip address 209.165.200.225 255.255.255.252 R1(config-if)#ipv6 address 2001:db8:acad:3::225/64 R1(config-if)#description WAN1 R1(config-if)#no shutdown R1(config-if)#exit
EXAM TIP: Warto używać polecenia description
podczas ustawiania interfejsów, nawet jeśli nas o to nie proszą czy nie
podanej wprost treści opisu interfejsu ważne, że polecenie zostało
wydane w trybie konfiguracji interfejsu.
Podczas konfiguracji routera, być może będzie potrzeba skonfigurowania adresu pętli zwrotnej. Loopback fizycznie nie istnieje, jest adresem programowym, konfigurowanych w celach testowych lub pozostawnienia jednego co najmniej aktywnego portu na urządzeniu. Pętlę zwrotną konfiguruje się w poniższy sposób.
R1(config)#interface loopback 0 R1(config-if)#ip address 10.0.0.1 255.255.255.0 R1(config-if)#exit
2.1.4. Ćwiczenie praktyczne - Packet Tracer
Konfiguracja interfejsów routera - scenariusz
Konfiguracja interfejsów routera - zadanie
2.1.5. Polecenia weryfikacji interfejsu
Czasami po ustawieniu interfejsów, czy zmianie innej konfiguracji w urządzeniach Cisco, chcielibyśmy zobaczyć czy gdzieś nie popełniśmy błedu lub też znajdujemy się w sytuacji, w której coś jest nie tak, coś nie działa jak należy i trzeba sprawdzić gdzie popełniliśmy błąd. Poniżej znajduje się lista przydatnych poleceń:
show ip interface briefishow ipv6 interface brief- wyświetlenie podsumowania wszystkich interfejsów wraz z adresami IPv4 i IPv6 oraz ich bieżącym stanem.show running-config interface interface-id- polecenia zastosowane do konfiguracji podanego interfejsu.show ip routeishow ipv6 route- wyświetlenie tablicy routingu. Od wersji 15 IOS, dla interfejsów będą dwie trasy podłączona (C) i lokalna (L). We wcześniejszych wersjach IOS, będzie występować jedynie trasa podłączona (C)show ip interface interface-idishow ipv6 interface interface-id- wyświetla szczegółowe informacje na temat podanego interfejsu. Identyfikator można pominąć wówczas wyświetlone zostaną wszystkie szczegóły wszystkich interfejsów w urządzeniu, po kolei.
Wyjścia polecenia show podelgają filtrowanie, podobnie jak na Uniksach, stosuje się tutaj znak potoku (|), po znaku filtrowania (potoku), może wystąpić jedno z czterech poleceń filtrujących, a każde z nich przyjmuje jako argument wyrażenie filtrujące.
section- pokazuje całą sekcję rozpoczynjące się od wyrażenia filtrującegoinclude- wyświetla linie pasujące do wyrażenia filtrującegoexclude- wyklucza linie pasujące do wyrażenia filtrującegobegin- pokazuje pozostałe linie z wyjścia polecenia od określonego przez wyrażenie filtracyjne wiersza.
Jak mogliśmy spostrzec lub nie, IOS posiada historię. Historia poleceń
domyślnie przechowuje tylko 10 wprowadzonych poleceń, a poruszać się
poniej możemy albo zapomocą strzałek (góra - dół) lub kombinacji
klawiszy Ctrl+p i Ctrl+n (GNU Readline). Wielkość
bufora możemy kontrolować, wydając w trybie uprzywilejowanym polecenie
terminal history size N,
gdzie N jest ilością przechowywanych wierszy.
R1#terminal history size 200 R1#show history ena show history terminal history size 200 show history
Innym polecenie dotyczącym historii, jest
show history, wyświetla cały bufor
historii poleceń.
2.1.5. Ćwiczenie praktyczne - Pakiet Tracer
Weryfikacja bezpośrednio podłączonych sieci - scenariusz
Weryfikacja bezpośrednio podłączonych sieci - zadanie
Podsumowanie
W tym rodziale dowiedzieliśmy się w jaki sposób uruchamiany jest system IOS na przełącznikach oraz ile informacji są nam stanie przekazać zwykłe diody LED tych urządzeń. Nauczyśliśmy się co robić w przypadku, kiedy zapisaliśmy w stałej pamięci wadliwą konfigurację czy zapomnieliśmy haseł dostępowych. Poznaliśmy metody konfiguracji dupleksu, domyślniej prędkości portu oraz mechnizmu Auto-MDIX. Na koniec przypomnieliśmy sobie podstawową konfigurację przełącznika i routera.
2.2. Koncepcje przełączania
Koncepcje przełączania i przekazywania ramek są uniwersalne dla dla różnego rodzaju sieci. Nie tylko tych informatycznych ale telekomunikacyjnych. Wstępują różne typy przyłączników, a wybór metody zależy od przeływu tego ruchu. Z przełączaniem wiązą się dwa terminy: ingress - określenie stosowane dla portu, z którego nadchodzi ramka oraz egress - określenie dla portu, którego ramki będą używać do opuszczenia przełacznika.
2.2.1. Przekazywanie ramek
Podczas przełączania przełączniki wykorzystują tablicę przełącznia. Ramki przełączane są na podstawie adresów MAC zapisanych w tej tablicy. Tablica wiąże ze sobą porty oraz adresy MAC, przez co ramka z określonym adresem docelowym zostanie skierowana na port powiązany w tablicy, bez względu na to jaki był port wejściowy. Ramka nigdy nie zostanie przekazana na port, z którego została odebrana.
Tablica przełączania składa się numeru lub identyfikatora portu oraz adresu MAC urządzenia do niego podłączonego. Czyli ramki odebrane na tym porcie będą zawierać adres źródłowy tego urządzenia. Podczas przełączania przełącznik sprawdza adres docelowy czy istnieje przypisany do niego port przełącznika. Jeśli tak ramka jest przekazywana na ten port. Tablica przełączania czasami nosi nazwę tabeli CAM od rodzaju pamięci zastosowanej do jej przechowywania.
Tablica MAC przełącznika jest uzupełniana na podstawie metod uczenia się. Przełącznik analizuje źródłowy adres MAC ramki i zapisuje ją tablicy przypisując jej port, z którego została odebrana. Następnie w celu przełączenia ramki analizuje adres docelowy. Jeśli takiego adresu nie ma w tablicy wówczas przełącznik zachowuje się jak koncentrator i przekazuje ramkę na wszystkie pozostałe porty. Przez kilka pierwszych sekund działania, każdy przełącznik zachowuje się koncentrator, ze względu na pustą tablicę. Proces uczenia się nie kończy się na przypisaniu MAC-u do portu. Ze względu na to, że tablice MAC ma ją skończoną pojemność, więc trzeba usuwać nieaktywne już dowiązania. Jeśli z danego portu ramka nie nadejdzie w ciągu 5 minut (300 sekund), to port zostaje w tablicy zwolniony, inaczej ma się to w przypadku przepięcia innego urządzeń do tego samego portu na przełączniku, w tym przypadku dodawny jest nowy wpis. Wpis poprzedniego hosta pozostanie w tablicy do upływy wspomnianej ilości czasu . Jeśli w ciągu tych 300 sekund, na tym porcie pojawi się ramka, z adresem źródłowym przypisanym w tablicy wówczas licznik zostanie zresetowany.
Ze względu na użyte układy ASIC (ang. Application Specific Integrated Circuits), przełączniki bardzo szybko dokonują decyzji, redukując tym samym czas obsługi pakietu oraz umożliwiając urządzeniom wydajną obsługę wielu urządzeń. Mimo to możemy wyróżnić dwa rodzaj metod przełącznia.
- store-and-forward - przy tej metodzie przełącznik dokonuje decyzji o przełączeniu w momencie odebrania całej ramki. Sprawdzona ona zostaje pod kątem błedów, na podstawie sumy kontrolnej CRC. Jest to domyślna metoda przełącznia ramek stosowana nawet przez najtańsze przełączniki, w tym również przełączniki Cisco.
- cut-through - bardzo szybka metoda, przełącznie rozpoczyna się w momecie gdy przełącznik odbierze adres docelowy.
Z najważniejszch cech przełączania store and forward jest na pewno sprawdzanie błędów, ale również automatyczne buforowanie, jeśli między portami występuje różnica w prędkości, ramki są zachowywane przez przełącznik, sprawdzane pod kątem błędów, przekazywane do bufora portu wyjściowego, i następnie przesyłane dalej do odbiorcy.
Metoda cut-through, nie sprawdza ramek pod kątem błędów. Może przekazać je dalej. Metoda ta jest bardzo szybka nie czeka nawet na odebranie całej ramki. Decyzje podjemuje, gdy odbierze adres MAC docelowy. Tego rodzaju przełączania dokonuje się w środowiskach HPC wymagających opóźnien na poziomie 10 mikrosekund i mniejszych. Metoda ta może mieć negatywny wpływ na wydajność sieci, poprzez zapychanie jej nie poprawnymi ramkami, dlatego jeśli ilość błedów zwiększa się ta metoda przełącza się w metodę fragment-free - ta metoda wydłuża nieco ilość odebranej ramki (do pola Typ), zanim podejmie decyzje pozwala to lepsze sprawdzenie błędów, niż w przypadku zwykłej metody cut-through nie wprowadzając przy tym dodatkowych opóźnień.
2.2.2. Domena przełączania
W obecnych sieciach zbudowanych na bazie przełącznika, domena kolizyjna sprowadza się do pojedyńczego połączenia między urządzeniami. Tym przypadku kolizje nie występują i termin ten można uznać za przestarzły. Jednym przypadkiem, w którym mogło by dojść do kolizji w takich warunkach jest przypadek, gdzie urządzenia nie dogadają się w sprawie dupleksu. Jeden port na jednym urządzeniu ustawi się w tryb half a drugi w full. Raczej jest jakiś problem z urządzeniem, może jego uszkodzenie. Przełączniki domyślnie lobbują wyłącznie full-duplex.
Inną domeną, w której komputery i przełączniki biorą czynny udział jest domena rozgłoszeniowa. Sieci krążą ramki rozgłoszeniowe, aby komputery i inne urządzenia znały swoje adresy oraz ewentualnie zasoby jakie mogą zaoferować (nie które usługi wysyłają ramki broadcastowe). Duża ilosc takich transmisji może spowodować znaczny spadek wydajności. Do podziału domen rozgłoszeniowych na mniejsze części może służyć router lub podział sieci na mniejsze sieci wirtualne - VLAN-y (o vlanach będzie przyszły rozdział).
Chcąć mieć wydajną sieć musimy zaopatrzyć się w dobrej jakości przełączniki. Poniżej znajduje się kilka cech, które należy sprawdzić wybierając przełączniki.
- Szybkość portów - obecnie sieci 100Mb/s ochodzą w niepamięć. Obecnie mamym szybie łącza swiatłowodowe lub trasmisję sieci komórkowej w standardzie 5G. Gdzie transfery rzędu 100Mb/s mogą być nie zadawalające. A przełączniki 1Gb/s są dość powszechne i coraz tańsze. Osobiście jeśli nie chcemy sprędzać czasu na analizowaniu ruchu to 1 gigabitowy przełącznik z uplinkami światłowodowymi do 10Gb/s powinien wystarczyć.
- Szybkie przełączanie wewnętrzne - prędkość wewnętrznej magistrali
- Duży bufor ramek - ilość pamięci przeznaczona na bufor.
- Wysoka gęstość portów - ilość portów wymaganych oraz ile portów pozostanie nadmiarowo i czy to wystarczy na potrzeby ewentualnej późniejsz rozbudowy.
Podsumowanie
W tym rodziale przypomnieliśmy sobie o metodach przełącznia oraz o tym jak przełączniki przekazują ramki. Na koniec wyjaśnniliśmy sobie czym jest domena przełączania oraz na jakie cechy przełączników zwrócić uwagę podczas ich zakupu.
2.3. Sieci VLAN
W poprzednim rozdziale omawialiśmy, taką definicję jaką jest domena rozgłoszeniowa. Jednym z sposobów dzielenia domeny rozgłoszeniowej są VLAN-y. VLAN-y to nic innego jak wydzielona (a zarazem odizolowana) podsieć wirtualna w sieci przełączanej (opartej na przełącznikach). Do komunikacji między różnymi (to jest istotne) VLAN-ami, potrzebny jest router.
VLAN-y poza podziałem na mniejsze domeny rozgłoszeniowe, umożliwiają udostępnienie tych samych zasobów sieciowych, nie zależnie od miejsca umiejscowanie stanowiska pracy w firmie, oznacza to, że nie które działy mogą zajmować różne pokoje w budynkach firmy, ale pozostawać wpięci do tej samej fizycznej sieci lokalnej. To nie wszystkie zalety wykorzystywania VLAN-ów w sieci LAN. Poniżej znajduje się cała lista.
- Mniejsze domeny rozgłoszeniowe - podział sieci na sieci VLAN zmniejsza liczbę urządzeń w domenie rozgłoszeniowej.
- Poprawa bezpieczeństwa - tylko użytkownicy w tej samej sieci VLAN mogą się ze sobą komunikować.
- Zwiększona efektywność IT - VLAN-y upraszczają zarządzanie siecią, ponieważ użytkownicy o tych samych wymaganiach mogą się ze sobą komunikować. Sieci VLAN posiadają identyfikatory, które ułatwiąją ich rozróżnienie.
- Redukcja kosztów - VLAN-y zmieniejszają zapotrzebowanie na kosztowne uaktualnienia sieci i korzystają z istniejącej przepustowości, a upliniki są lepiej wykorzystywane.
- Lepsza wydajność - mniejsze domeny rozgłoszeniowe zmniejszają ilość nie potrzebnego ruchu.
- Prostszy projekt i ułatwione wdrażanie aplikacji - sieci VLAN agregują użytkowników i urządzenia sieciowe w celu obsługi biznesu lub wymagań geograficznych. Posiadanie oddzielnych funkcji sprawia, że zarządzania projektem lub praca ze specjalistycznymi aplikacjami jest łatwiejsza.
Rodzaje VLAN-ów można podzielić na klasę ruchu jaki przesyłaja ale również na funkcję jaką pełnią i tutaj możemy wyróżnić:
- VLAN domyślny - na urządzeniach Cisco VLAN domyślny ma identyfiktor 1. Do niego przypisane są wszystkie dostępne na urządzeniu porty. Ruch kontrolny warstwy drugiej odbywa się w sieci VLAN-u 1. Istotną rzeczą związana z tym VLAN-em są takie fakty jak: wszystkie porty są domyślnie przypisane do tego VLAN-u, VLAN-em natywnym jest VLAN 1, VLAN-em zarządzania jest 1. Nazwy sieci VLAN 1 nie można zmienić, a samego VLAN-u usunąć.
- VLAN danych - VLAN-y danych są skonfigurowane w celu oddzielenia ruchu generowanego przez użytkownika. Sieć VLAN danych są używane do wydzielenia w sieci grup użytkowników i urządzeń. Nowoczesna sieć może mieć wiele sieci VLAN danych. W zależności od wymagań organizacyjnych. Należy pamiętać, że ruch głosowy i zarządzania nie powien być dozwolony w sieci VLAN danych.
- Natywna sieć VLAN - Ruch sieci VLAN, jeśli ma zostać przesłany do innego przełącznika, to wykorzystywane są do tego porty magistralne, tzw. trunki, ruch wówczas określany jest jako znakowany. Port ustawiony jako trunk 802.1Q wstawia 4-bitowy znacznik w nagłówku ramki Ethernet, w celu zindentyfikowania sieci VLAN, do której należy ta ramka. Przełacznik może jednak chcieć przesłać nieoznakowany ruch przez łącze trunk. Tego typu ruch generowany może byc przez przełączniki lub inne urządzania starszego typu. Porty trunk umieszczaja taki ruch w VLAN-ie natywnym. Domyślnie jest to VLAN 1. Ustawiając VLAN natywny najlepiej jest skorzystać z jakiegoś wysokiego identyfikatora. Tak zdefiniowany natywny VLAN, jest często stosowany dla wszystkich portów trunk w całej sieci.
- VLAN zarządzania - tego typu VLAN jest konfigurowany specjalnie na potrzeby konfiguracji urządzeń oraz ich protokołów, takich jak: SSH, Telnet, HTTPS, HTTP czy SNMP. Domyslnym VLAN-em zarządzania jest VLAN 1.
- VLAN głosowy - wymagany do obsługi technologii VoIP, ze względu na jego wymagania co do priorytetu ruchu. Warto pamiętać, że do poprawnej obsługi VoIP, cała sieć musi być zaprojektowana pod jej kątem. Najczęściej do transmisji głosowej wykorzystywany jest VLAN 150.
Ćwiczenie praktyczne - Packet Tracer
Kto odbiera ruch rozgłoszeniowy? - scenariusz
Kto odbiera ruch rozgłoszeniowy? - zadanie
2.3.1. Sieci VLAN w infrastrukturze z wieloma przełącznikami
Jak wspomnieliśmy wcześniej, aby przesłać informacje tej samej sieci VLAN, między przełącznikami potrzebne są porty magistralne - trunk-i, które za pomocą enkapsulacji 802.1Q umieszczają w ramkach identyfikator sieci VLAN, aby przełączniki mogły rozróżnić, z której sieci pochodzą transmitowane dane. Utworzone na przełącznikach trunk-i domyślnie przekazuje wszystkie zdefiniowane na przełącznikach VLAN-y.
Porty trunk enkapsulują ramke Ethernet II w ramkę 802.1Q, dodając po źródłowym adresie MAC, tzw. tag - pole ze znacznikiem VLAN-u. Sam tag zawiera kilka mniejszych pól:
- Typ - 2-bajtowa wartość, zwana wartością TPID
(Tag Protocol ID). Dla sieci Ethernet ma wartość
szesnastkową
0x8100. - Priorytet użytkownika - 3-bitowa wartość, obsługująca poziom oraz usługę.
- CFI (Canonical Format Identifier) - 1 - bitowy identyfikator (flaga), który umożliwia przenoszenie ramek Token Ring przez Ethernet.
- VLAN ID (VID) - 12-bitowy numer identyfikacyjny VLAN. Ze względu na to, że to pole ma 12-bitów. To maksymalny identyfikator VLAN-u to 4096.
Po dodaniu pola znacznika, przełącznika przelicza na nowo FCS i wstawia nową wartość do ramki.
W przypadku natywnego VLAN-u, znakowanie wygląda trochę inaczej. Ramki znakowane, znacznikiem natywnego VLAN-u odebrane przez port trunk są odrzucane. Więc trzeba pamiętać aby urządzenia podłączone do tego typu portu były skonfigurowane w taki sposób, aby nie wysyłały znakowanych ramek, tag-iem natywnego VLAN-u.
Inaczej jest gdy na port trunk trafi ramka nieoznakowana, jeśli tak już sie zdarzy to przełącznik przekaże ją do natywnej sieci VLAN. Jeśli na przełączniku nie ma urządzeń w natywnej sieci VLAN i nie ma innych portów magistrali to ramka jest odrzucana. Podczas konfiguracji portu magistrali 802.1Q, mamy możliwość ustawienia natywnego VLAN-u.
Dla usług VoIP wymagany jest osobny VLAN, aby zapewnić odpowiednie wymagania QoS i zasad bezpieczeniastwa dla ruchu głosowego. Telefony IP firmy Cisco łączy się bezpośrednio z portem przełącznika. Komputer natomiast można połaczyć do telefonu IP, aby także uzyskać połączenie sieciowe. Port dostępowy przeznaczony dla telefonu IP można skonfigurować w taki sposób, żeby korzystał z dwóch oddzielnych sieci VLAN. Jeden VLAN dla obsługi ruchu głosowego, a drugi VLAN danych dla obsługi ruchu hosta.
Port dostępowy przełącznika za pomocą CDP instruuje telefon IP, aby wysyłał ruch głosowy za pomocą jednej z trzech metod:
- Ruch z Voice VLAN musi być znakowany odpowiednią wartością priorytetową klasy usług (CoS) warstwy 2.
- Ruch dostępowej sieci VLAN, można również znakować za pomocą wartości priorytetowej CoS warstwy 2.
- VLAN dostępowy nie jest znakowany (bez wartości priorytetowe CoS warstwy 2)
Ćwiczenie praktyczne - Packet Tracer
Badanie implementacji sieci VLAN - scenariusz Badanie implementacji sieci VLAN - zadanie
2.3.3. Konfiguracja sieci VLAN
Omawiając tag ramek 802.1Q, mówiliśmy o polu VLAN ID, jest ono 12-bitowe. Tyle przewiduje standard, którym opisane są ramki ze znacznikiem. Jednak nie wszystkie przełączniki obsługują tak samo sieci VLAN. Tutaj mówimy o zakresach, o zakresie normalnym i zakresie rozszerzonym. Spójrzmy jak wygląd lista sieci VLAN na takim urządzeniu, na którym nie zdefiniowano żadnych sieci VLAN.
Switch#show vlan brief
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Fa0/1, Fa0/2, Fa0/3, Fa0/4
Fa0/5, Fa0/6, Fa0/7, Fa0/8
Fa0/9, Fa0/10, Fa0/11, Fa0/12
Fa0/13, Fa0/14, Fa0/15, Fa0/16
Fa0/17, Fa0/18, Fa0/19, Fa0/20
Fa0/21, Fa0/22, Fa0/23, Fa0/24
Gig0/1, Gig0/2
1002 fddi-default active
1003 token-ring-default active
1004 fddinet-default active
1005 trnet-default active
Sieci VLAN w normalnym zakresie:
- Są stosowane we wszystkich małych i średnich sieciach biznesowych i korporacyjnych.
- Ich identyfikatory (VLAN ID) zawiera się w przedziale od 1 do 1005.
- Identyfikatory od 1002 do 1005 są zarezerowane dla starszch technologii sieciowych (tj. Token Ring i Fibre Distributed Data Interface).
- Identyfikatory 1 i od 1002 do 1005 są tworzone automatycznie i nie można ich usunąć.
- Konfiguracje są przechowywane w pamięci flash przełacznika w pliku bazy danych VLAN o nazwie vlan.dat.
- Po skonfigurowaniu, protokół VTP (VLAN Trunking Protocol) pomoga z synchronizować bazę danych VLAN między przełącznikami.
Sieci VLAN o rozszerzonym zakresie:
- Wykorzystywane przez ISP lub globalne przedsiębiorstwa, wystarczająco duże, aby potrzebować tak dużej ilości VLAN-ów.
- Ich identyfikatory (VLAN ID) zwiera się w przedziale od 1006 do 4096.
- Konfiguracje są domyślnie zapisywane w konfiguracji bierzącej.
- Obsługują mniej funkcji VLAN niż sieci w normalnym zakresie.
- Wymaga konfiguracji trybu transparentnego VTP do obsługi sieci VLAN o rozszerzonym zakresie.
Aby skonfigurować sieci VLAN na przełączniku w trybie konfiguracji globalnej wydajemy poniższe polecenia:
Switch(config)#vlan 20 Switch(config-vlan)#name student Switch(config-vlan)#exit
Polecenie vlan wymaga podania numeru
VLAN-u (identyfikatora). Nazwa nie jest wymagana jednak, pozwala na
łatwiejsze rozpoznanie VLAN-ów. Jeśli jej nie podamy przełącznik,
przypisze ją sobie automatycznie, tworząc ją ze słowa VLAN i jeśli
identyfikator jest dość niski (normalny zakres sieci VLAN) to do
nazwy zostanie dodany identyfikator poprzedzony zerami. Jak na
poniższym przykładzie.
Switch#show vlan brief
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Fa0/1, Fa0/2, Fa0/3, Fa0/4
Fa0/5, Fa0/6, Fa0/7, Fa0/8
Fa0/9, Fa0/10, Fa0/11, Fa0/12
Fa0/13, Fa0/14, Fa0/15, Fa0/16
Fa0/17, Fa0/18, Fa0/19, Fa0/20
Fa0/21, Fa0/22, Fa0/23, Fa0/24
Gig0/1, Gig0/2
20 student active
30 VLAN0030 active
1002 fddi-default active
1003 token-ring-default active
1004 fddinet-default active
1005 trnet-default active
Utworzenie VLAN-ów na przełącznikach do tylko połowa pracy do wykonania podczas tworzenia sieci VLAN. Teraz trzeba przypisać do tych VLAN-ów, odpowiednie porty. W trybie konfigracji globalnej wydajmy poniższe polecenia.
Switch#configure terminal Enter configuration commands, one per line. End with CNTL/Z. Switch(config)#interface fastEthernet0/6 Switch(config-if)#switchport mode access Switch(config-if)#switchport access vlan 20 Switch(config-if)#end
Na początek trochę teorii. Na przykładzie widzmy polecenie
switchport. To nie jest tylko takie
polecenie. Ale porty przełączników Cisco mają różne reprezentacje
w zależności od warstwy ISO/OSI:
L3 -> SVI
|
L2 -> Switchport
|
L1 -> Fa0/6
Przypisując port do VLAN-u, konfigurujemy jego warstwę drugą. Za pomocą
polecenia:
switchport mode access, ustawiamy
port jako dostępowy, następnie za pomocą polecenia:
switchport access vlan 20
przypisujemy, dla którego VLAN-u ten port ma być portem dostępowym.
I to tyle. W ten sposób utworzylismy sieć VLAN z jednym portem, dla
pewności możemy wyświetlić sobie podsumowanie dotyczące VLAN-ów.
Switch#sh vl br
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Fa0/1, Fa0/2, Fa0/3, Fa0/4
Fa0/5, Fa0/7, Fa0/8, Fa0/9
Fa0/10, Fa0/11, Fa0/12, Fa0/13
Fa0/14, Fa0/15, Fa0/16, Fa0/17
Fa0/18, Fa0/19, Fa0/20, Fa0/21
Fa0/22, Fa0/23, Fa0/24, Gig0/1
Gig0/2
20 student active Fa0/6
30 VLAN0030 active
1002 fddi-default active
1003 token-ring-default active
1004 fddinet-default active
1005 trnet-default active
Jak możemy zauważyć na powyższym przykładzie port Fa0/6, został zabrany z domyślnego VLAN-u 1 i przypisany do VLAN-u 20.
W przypadku gdy chcemy przygotować port dostępowy dla telefonii a przy okazji do komputera. Musimy wykonać poniższe polecenia.
Switch(config)#vlan 40 Switch(config-vlan)#name office Switch(config-vlan)#vlan 150 Switch(config-vlan)#name VOICE Switch(config-vlan)#exit Switch(config)#int fa0/18 Switch(config-if)#switchport mode access Switch(config-if)#switchport access vlan 40 Switch(config-if)#mls qos trust cos Switch(config-if)#switchport voice vlan 150 Switch(config-if)#end
W tym przypadku utworzyliśmy dwa VLAN-y 40 (dla PC) i 150 (dla telefonu)
następnie przypisaliśmy do portu: fa0/18
VLAN dostępowy 40. Następną czynnością jest włączenie QoS, za pomocą
polecenia mls qos trust cos.
Ustawienia QoS nie są częścią kursu CCNA, więc można traktować te
polecenie jako czynność mechaniczną, którą należy wykonać, teraz można
przypisać drugi dodatkowy VLAN głosowy do tego samego portu.
switchport voice vlan 150
Polecenie podsumowujące VLAN-y znamy:
show vlan brief. Jednak polecenie
show vlan, posiada kilka innych
argumentów. Możemy podać id i następnie identyfikator lub
name i nazwę. Innym argumentem jest summary, które
wyświetla kilka statystyk na temat VLAN-ów.
S1# show vlan summary Number of existing VLANs : 7 Number of existing VTP VLANs : 7 Number of existing extended VLANS : 0
Wracają jeszcze do przedniego przykładu z VLAN-em głosowym. Chcąć zobaczyć czy nasze zmiany zostały zatwierdzone możemy podejrzeć switchport każdego interfejsu.
Switch# show interface fastEthernet0/18 switchport Name: Fa0/18 Switchport: Enabled Administrative Mode: static access Operational Mode: down Administrative Trunking Encapsulation: dot1q Operational Trunking Encapsulation: native Negotiation of Trunking: Off Access Mode VLAN: 40 (office) Trunking Native Mode VLAN: 1 (default) Voice VLAN: 150 Administrative private-vlan host-association: none ...
Konfiguracja sieci VLAN, może być monotonnym zajęciem. A przy takich czynnościach łatwiej o pomyłkę. Musimy więc dowiedzieć się jak wyjść na prostą, gdy coś źle skonfigujemy. Częstym błędem jest przypisanie portu nie do tego VLAN-u. Zatem aby zmienić przynależność portu do sieci VLAN należy wydać polecenie:
Switch(config)#int fa0/18
Switch(config-if)#no switchport access vlan
Switch(config-if)#end
Switch#
%SYS-5-CONFIG_I: Configured from console by console
Switch#sh vl br
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Fa0/1, Fa0/2, Fa0/3, Fa0/4
Fa0/5, Fa0/6, Fa0/7, Fa0/8
Fa0/9, Fa0/10, Fa0/11, Fa0/12
Fa0/13, Fa0/14, Fa0/15, Fa0/16
Fa0/17, Fa0/18, Fa0/19, Fa0/20
Fa0/21, Fa0/22, Fa0/23, Fa0/24
Gig0/1, Gig0/2
40 office active
150 VOICE active Fa0/18
1002 fddi-default active
1003 token-ring-default active
1004 fddinet-default active
1005 trnet-default active
Po wydaniu polecenia,
no switchport access vlan, port
Fa0/18 wrócił do VLAN-u domyślnego, natomiast VLAN 40 jest pusty.
Nie ma przypisanego żadnego portu.
Inną czynnością może byc usunięcie VLAN-u. Jednak tutaj musimy pamiętać o kilku rzeczach. Na początku trzeba sprawdzić jakie porty są przypisane do usuwanego VLAN-u. Następnie te porty należy przepisać do innego VLAN-u i na koncu dopieru usunąć VLAN. Jeśli nie wykonamy tych czynności, porty osierocone przez usunięcie VLAN-u nie będą mogły komunikować się z innymi portami.
Switch#sh vl br
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Fa0/10, Fa0/11, Fa0/12, Fa0/13
Fa0/14, Fa0/15, Fa0/16, Fa0/17
Fa0/18, Fa0/19, Fa0/20, Fa0/21
Fa0/22, Fa0/23, Fa0/24, Gig0/1
Gig0/2
20 student active Fa0/1, Fa0/2, Fa0/3, Fa0/4
Fa0/5, Fa0/6, Fa0/7, Fa0/8
Fa0/9
40 office active
150 VOICE active Fa0/18
1002 fddi-default active
1003 token-ring-default active
1004 fddinet-default active
1005 trnet-default active
Switch#conf term
Enter configuration commands, one per line. End with CNTL/Z.
Switch(config)#int range fa0/1-9
Switch(config-if-range)#switchport access vlan 40
Switch(config-if-range)#end
Switch#
%SYS-5-CONFIG_I: Configured from console by console
Switch#sh vl br
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Fa0/10, Fa0/11, Fa0/12, Fa0/13
Fa0/14, Fa0/15, Fa0/16, Fa0/17
Fa0/18, Fa0/19, Fa0/20, Fa0/21
Fa0/22, Fa0/23, Fa0/24, Gig0/1
Gig0/2
20 student active
40 office active Fa0/1, Fa0/2, Fa0/3, Fa0/4
Fa0/5, Fa0/6, Fa0/7, Fa0/8
Fa0/9
150 VOICE active Fa0/18
1002 fddi-default active
1003 token-ring-default active
1004 fddinet-default active
1005 trnet-default active
Switch#conf term
Enter configuration commands, one per line. End with CNTL/Z.
Switch(config)#no vlan 20
Switch(config)#end
Switch#
%SYS-5-CONFIG_I: Configured from console by console
Switch#sh vl br
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Fa0/10, Fa0/11, Fa0/12, Fa0/13
Fa0/14, Fa0/15, Fa0/16, Fa0/17
Fa0/18, Fa0/19, Fa0/20, Fa0/21
Fa0/22, Fa0/23, Fa0/24, Gig0/1
Gig0/2
40 office active Fa0/1, Fa0/2, Fa0/3, Fa0/4
Fa0/5, Fa0/6, Fa0/7, Fa0/8
Fa0/9
150 VOICE active Fa0/18
1002 fddi-default active
1003 token-ring-default active
1004 fddinet-default active
1005 trnet-default active
Do usunięcia VLAN-u 20 użyłem polecenia
no vlan 20. Wcześniej jednak
przypisałem na porty tego VLAN-u do innej sieci VLAN.
Ćwiczenie praktyczne - Packet Tracer
Konfiguracja sieci VLAN - scenariusz Konfiguracja sieci VLAN - zadanie
2.3.4. Połączenia trunk
Sieci VLAN oparte o jeden przełącznik trochę mijają się z celem, ale jeśli założymy tych przełączników jest kilka, a użytkownicy różnych sieci VLAN znajdują się w róznych miejscach budynku. To wówczas aby zachodziła między użytkownikami komunikacja, potrzebujemy łączy magistralnych - trunk-ów. Porty magistralne konfigurujemy podobnie do portów dostępowych. W trybie konfiguracji globalnej wydajemy następującą serię poleceń:
Switch(config)#int gig0/1 Switch(config-if)#switchport mode trunk Switch(config-if)#switchport trunk native vlan 1 Switch(config-if)#switchport trunk allowed vlan 1,40,150 Switch(config-if)#end Switch#
Po podłaczeniu łączy trunk, będziemy mogli wydać polecenie
show interface trunk, które pokaże
nam informacje na temat skonfigurowanych w naszym urządzeniu portów
magistralnych.
Switch#sh int tr Port Mode Encapsulation Status Native vlan Gig0/1 on 802.1q trunking 1 Port Vlans allowed on trunk Gig0/1 1,40,150 Port Vlans allowed and active in management domain Gig0/1 1,40,150 Port Vlans in spanning tree forwarding state and not pruned Gig0/1 1,40,150
Jeśli natomiast nasze połącznie trunk nie jest póki co
zestawione, możemy wydać polecenie:
show interface gig0/1 switchport. To
polecenie również zwróci informacje na temat ustawień portu magistrali.
Switch#sh int gig0/1 switchport Name: Gig0/1 Switchport: Enabled Administrative Mode: trunk Operational Mode: trunk Administrative Trunking Encapsulation: dot1q Operational Trunking Encapsulation: dot1q Negotiation of Trunking: On Access Mode VLAN: 1 (default) Trunking Native Mode VLAN: 1 (default) Voice VLAN: none Administrative private-vlan host-association: none Administrative private-vlan mapping: none Administrative private-vlan trunk native VLAN: none Administrative private-vlan trunk encapsulation: dot1q Administrative private-vlan trunk normal VLANs: none Administrative private-vlan trunk private VLANs: none Operational private-vlan: none Trunking VLANs Enabled: 1,40,150 Pruning VLANs Enabled: 2-1001
Jeśli zajdzie taka potrzeba, to możemy wyczyścić ustawienia natywnego VLAN-u oraz sieci VLAN dopuszczonych do ruchu przez ten trunk. Aby to zrobić wydajemy poniższe polecenia:
Switch#conf term Enter configuration commands, one per line. End with CNTL/Z. Switch(config)#int gig0/1 Switch(config-if)#no switchport trunk native vlan Switch(config-if)#no switchport trunk allowed vlan Switch(config-if)#end
Zadanie praktyczne - Packet Tracer
Konfiguracja połączeń trunk - scenariusz
Konfiguracja połączeń trunk - zadanie
Laboratorium
Konfiguracja sieci VLAN i łączy trunk
2.3.5. Protokół DTP
Protokół DTP jest własnościowym protokołem Cisco, pozwalającym negocjować między sąsiednimi przełącznikami łącza magistralne (trunk-i). Jest on domyślnie włączony w przełącznikach Catalyst z serii 2960 i 3650, zarządza on negocjacją łączy trunk o ile port na urządzeniu obok jest skonfigurowany w trybie trunk i wspiera DTP.
Jeśli do portu trunk podłączamy urządzenie, które nie wspiera DTP, lepiej jest tę funkcję wyłaczyć. Niektóre urządzenia mogą źle przekazywać ramki DTP. Inną dość istotną kwestią jest bezpieczeństwo. Otóż istnieje oprogramowanie, które pozwoli aby zamienić zwykły port Ethernet komputera w port przełącznika ustawiony w tryb trunk. Wówczas może dojść do wynegocjowania łącza magistralnego między tymi urządzeniami, jeśli tak się stanie, to sieci VLAN przestają mieć sens. Ponieważ tak ustawiony komputer może połączyć się z dowolnym komputerem w dowolnym VLAN-ie.
Dlatego zazwyczaj w sieciach produkcyjnych, ten protokół w ogóle nie działa. Łącza trunk ustawiane są ręcznie. Wyłączenia protokołu DTP dokonany w trybie konfiguracji interfejsu wydając następujące polecenia:
Switch(config)#int gig0/1 Switch(config-if)#switchport mode trunk Switch(config-if)#switchport nonegotiate
Jeśli z jakiś powodów (choćby laboratoryjnych) chcielibyśmy wrócić do
protokołu DTP. To możemym włączyć go ponownie za pomocą poniższych
poleceń. Jednak najlepiej pozostawić porty magistralne w trybie
trunk.
Switch(config-if)#no switchport nonegotiate Switch(config-if)#switchport mode dynamic auto
Na switchport-ach przełącznika, możemy ustawić kilka trybów, negocjacji. Te tryby oddziaływują na siebie, w zależności jaki tryb jest ustawiony z jednej czy z drugiej strony, wówczas możemy przewidzieć jak może wyglądać komunikacja między urządzeniami na tych portach.
- access - Ustawia interfejs w stały tryb dostępu i negocjuje przełączenie łącza w tryb nie będący trunk-iem. Interfejs nie będzie trunkiem, bez znaczenia czy interfejs obok jest nim czy nie.
- dynamic auto - Umożliwia konwersję interfejsu w trunk. Interfejs będzie trunk-iem jeśli sąsiedni port jest w trybie trunk lub desirable (pożadany trunk). Ten tryb jest domyślny dla wszystkich interfejsów Ethernet-owych.
- dynamic desirable - Interfejs będzie próbować przekonwertować się w trunk. Przełączy się w tryb magistrali jeśli sąsiedni port jest trnuk-iem, lub jest trybie auto lub desirable.
- trunk - Ustawia interfejs w stały tryb trunk i negocjuje przełącznie sąsiedniego portu w tryb trunk. Interfejs ten będzie trunk-iem nawet jeśli drugi interfejs nim nie jest.
Ustawienie opcji interfejsu nonegotiate, spowoduje że do dyspozycji będzie mieć tylko 2 tryby - access oraz trunk.
W zależności od ustawienia portów, można uzyskać następujące rezulaty podczas negocjacji.
| Dynamic Auto | Dynamic Desirable | Trunk | Access | |
|---|---|---|---|---|
| Dynamic Auto | Access | Trunk | Trunk | Access |
| Dynamic Desirable | Trunk | Trunk | Trunk | Access |
| Trunk | Trunk | Trunk | Trunk | Ograniczona komunikacja |
| Access | Access | Access | Ograniczona komunikacja |
Access |
W celu sprawdzenia stanu protokołu DTP, na naszych urządzeniach możemy... No własnie w materiałach od Cisco podane jest polecenie show dtp interface fa0/1. Przy czym na Packet Tracerze - na którym przypomnę zdajemy egzaminy modułowe oraz główny CCNA. To polecenie nie występuje. Mimo posiadania najnowszej wersji 8.2.2 oraz Cisco IOS w wersji 15.0(2)SE4 - to polecenie nie występuje. Więc albo osoba przygotowująca materiały korzystała z nowszego firmware-u albo to polecenie jest stare i już go nie ma. Nie mniej jednak, dobra robota Cisco - kolejny babol w materiałach, które mają przygotować do egzaminu. Koniec rantu.
Zadanie praktyczne - Pakiet Tracer
Konfiguracja DTP - scenariusz
Konfiguracja DTP - zadanie
Podsumowanie
W tym rozdziale dowiedzieliśmy się czym są VLAN-y oraz jak podzielić dużą domenę rozgłoszeniową na mniejsze sieci wirtualne. Skonfigurowaliśmy łącza magistralne, aby hosty tych samych sieci VLAN, podłączonych do różnych przełączników mogły się ze sobą bez przeszkód komunikować. Na koniec dowiedzielismy się czym jest protokół DTP i jak funkcjonuje on w obecnych czasach.
Zadanie praktyczne - Packet Tracer
Wdrożenie sieci VLAN i łączy trunk
Wdrożenie sieci VLAN i łączy trunk
2.4. Routing między VLAN-ami
Po skonfigurowaniu sieci VLAN, może okazać się, że pomiędzy niektorymi sieciami powinna zachodzić komunikacja lub być może stworzyliśmy osobny VLAN dla serwerów i niezbędne jest aby dopuścić ruch do konkretnych serwerów.
VLAN-y zawsze są odrębnymi sieciami IP, więc do umożliwienia komunikacji między nimi, potrzebny będzie router lub przełącznik warstwy 3. Mamy trzy możliwości zapewnienia routingu między VLAN-ami.
- Tradycyjny routing pomiędzy sieciami VLAN - rozwiązanie bardzo słabo skalowalne. Wymaga, aby router posiadał dla każdego VLAN-u osobny fizyczny interfejs. Jeśli ktoś ma małą ilość sieci VLAN to może zastosować takie rozwiązanie.
- Router na patyku - rozwiązanie wystarczające dla małych i średnich sieci. Polega na połączeniu routera do przełącznika za pomocą łącza magistralnego.
- Routing między sieciami VLAN z wykorzystaniem przełącznika L3 - rozwiązanie stosowane w dużych sieciach. Polega na konfigurowaniu SVI dla każdego z VLAN-ów.
2.4.1. Router na patyku
Jak już wcześniej zostało wspomniane ta metoda opera się na pojedynczym łączu trunk między przełącznikiem a routerem. Nie jest to jednak wszystko. Ze względu na to, że wykorzystujemu jeden interfejs routera, musimy w jakiś sposób go podzielić, aby móc przypisać do niego wiele adresów IP. Takim rozwiązaniem są podinterfejsy. Kolejną czynnością do wykonania jest wskazanie jakie ramki ten podinterfejs będzie on otrzymywać.
Poniżej znajduje się konfiguracja routera, które skonfigurowałem, zgodnie z tą metodą:
Router#conf t Enter configuration commands, one per line. End with CNTL/Z. Router(config)#int gig0/0.30 Router(config-subif)#encapsulation dot1Q 30 Router(config-subif)#ip add 192.168.30.1 255.255.255.0 Router(config-subif)#description VLAN30 Router(config-subif)#exit Router(config)#int gig0/0.40 Router(config-subif)#encapsulation dot1Q 40 Router(config-subif)#ip add 192.168.40.1 255.255.255.0 Router(config-subif)#description VLAN40 Router(config-subif)#exit Router(config)#int gig0/0.99 Router(config-subif)#encapsulation dot1Q 99 Router(config-subif)#ip add 192.168.99.1 255.255.255.0 Router(config-subif)#description VLAN99 Router(config-subif)#exit Router(config)#int gig0/0 Router(config-if)#description Trunk-Switch0 Router(config-if)#no shut
Chcąc skonfigurować na interfejsie, podinterfejs należy dodac numer
podinterfejsu po oznaczeniu interfejsu oddzielając go kropką
(int gig0/0.30). Po wejsciu do
konfiguracji podinterfejsu, ustawiamy format ramek dodając przy tym
identyfikator VLAN-u, ktory ma trafić do tego interfejsu.
(encapsulation dot1Q 30). Na podstawie
tej informacji router, jeśli nadejdzie ramka z takim oznaczniem
to obsłuży ją ten podinterfejs. Poźniej podajemy adres IP oraz
maskę i możemy dodatkowo opisać te podinterfejsy. Dość istotna jest
ostatnia czynność. Dla całego interfejsu
(gig0/0) nie ustawiamy adresu
ip tylko go podnosimy. Możemym dodać opis. Oczywiście należy
pamiętać o skonfigurowaniu portu trunk podłączonego do routera
na przełączniku.
Testy ping między ewentualnym komputerami podłaczonymi do portów należących do tych sieci VLAN, powinny zakończyć się powodzeniem. Natomiast w celach weryfikacyjnych możemy wydać takie polecenia jak:
Router#show ip route
...
Gateway of last resort is not set
192.168.30.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.30.0/24 is directly connected, GigabitEthernet0/0.30
L 192.168.30.1/32 is directly connected, GigabitEthernet0/0.30
192.168.40.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.40.0/24 is directly connected, GigabitEthernet0/0.40
L 192.168.40.1/32 is directly connected, GigabitEthernet0/0.40
192.168.99.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.99.0/24 is directly connected, GigabitEthernet0/0.99
L 192.168.99.1/32 is directly connected, GigabitEthernet0/0.99
Router#show ip interface brief | include up
GigabitEthernet0/0 unassigned YES unset up up
GigabitEthernet0/0.30 192.168.30.1 YES manual up up
GigabitEthernet0/0.40 192.168.40.1 YES manual up up
GigabitEthernet0/0.99 192.168.99.1 YES manual up up
Router# show interfaces gig0/0.30 (dla pozostałych .40, .99)
GigabitEthernet0/0.30 is up, line protocol is up (connected)
Hardware is PQUICC_FEC, address is 0009.7c9a.ce01 (bia 0009.7c9a.ce01)
Internet address is 192.168.30.1/24
MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation 802.1Q Virtual LAN, Vlan ID 30
ARP type: ARPA, ARP Timeout 04:00:00,
Last clearing of "show interface" counters never
Switch0#show interface trunk
Port Mode Encapsulation Status Native vlan
Gig0/1 on 802.1q trunking 1
Gig0/2 on 802.1q trunking 1
Port Vlans allowed on trunk
Gig0/1 30,40,99,150
Gig0/2 30,40,99,150
Port Vlans allowed and active in management domain
Gig0/1 30,40,99,150
Gig0/2 30,40,99,150
Port Vlans in spanning tree forwarding state and not pruned
Gig0/1 30,40,99,150
Gig0/2 30,40,99,150
Zadanie praktyczne - Packet Tracer
Router na patyku - scenariusz
Router na patyku - zadanie
Laboratorium
2.4.3. Metoda z przełącznikiem 3 warstwy
Przełączniki L3 zapewniają znacznie szybszy i bardziej skalowalny routing dla sieci VLAN niż router na patyku. Przełaczniki te mogą routować z jednej sieci do drugiej za pomocą interfejsów SVI. Tego typu urządzania zapewniają mozliwość konwersji portu w routed port. Taki port zachowuje się tak jak port routera. Metoda uzycia przełącznika L3, polega skonfigurowaniu dla każdego z VLAN-ów osobnego SVI.
MLS0(config)#vlan 10 MLS0(config-vlan)#name Facility MLS0(config-vlan)#vlan 20 MLS0(config-vlan)#name Student MLS0(config-vlan)#exit MLS0(config)#int fa0/1 MLS0(config-if)#switchport mode access MLS0(config-if)#switchport access vlan 10 MLS0(config-if)#int fa0/2 MLS0(config-if)#switchport mode access MLS0(config-if)#switchport access vlan 20 MLS0(config-if)#exit MLS0(config)#int vlan 10 MLS0(config-if)#ip address 192.168.10.1 255.255.255.0 MLS0(config-if)#no shut MLS0(config-if)#int vlan 20 MLS0(config-if)#ip address 192.168.20.1 255.255.255.0 MLS0(config-if)#no shut MLS0(config-if)#exit MLS0(config)#ip routing MLS0(config)#end
Jeśli chodzi o omówienie konfiguracji, to dokonaliśmy tego za pomocą
poleceń, które znamy z poprzedniego rozdziału oraz poprzedniego modułu.
Ważne aby wydać polecenie ip routing,
po całej konfiguracji, aby włączyc routing IP. Bez tego polecenia
przełącznik L3, jest zwykłym przełącznikiem L2. Użycie tego polecenia
lub konwersja portu na routed port powoduje właczenie
dodatkowych funkcji, które wśród fizycnych urządzeń mogą być
ograniczane licencyjnie. Mamy bowiem doczynienia z dwiema wersjami
IOS dla switch-y L3: ipbase oraz ipservices.
Weryfikacji możemy dokonać ping-ując hosta z jednego VLAN-u do drugiego.
Zadanie praktyczne - Packet Tracer
Konfiguracja przełącznia w warstwie 3 i routingu między sieciami VLAN - scenariusz Konfiguracja przełącznia w warstwie 3 i routingu między sieciami VLAN - zadanie
2.4.4. Rozwiązywanie problemów z routingiem między sieciami VLAN
Istnieje kilka możliwych problemów związanych z routingiem między sieciami VLAN. Poniżej znajduje lista, w której możemym znaleźć kilka typowych błędów i sposobów na ich rozwiązania i sposoby na upewnienie się, że to naprawdę jest to.
| Rodzaj problemu | Jak naprawić | Jak zweryfikować |
|---|---|---|
| Brakujące sieci VLAN |
|
show vlan [brief]show interfaces switchportping
|
| Problemy dotyczące portów trunk |
|
show interfaces trunkshow running-config
|
| Problemy dotyczące portów dostępowych |
|
show interface switchportshow running-config interfaceipconfig
|
| Problemy związane z konfiguracją routera |
|
show ip interface briefshow interfaces
|
Zadanie praktyczne - Packet Tracer
Rozwiązywanie problemów z routingiem między sieciami VLAN - scenariusz
Rozwiązywanie problemów z routingiem między sieciami VLAN - zadanie
Laboratorium
Rozwiązywanie problemów z routingiem między sieciami VLAN
Podsumowanie
W tym rozdziale poruszylismy kwestie związane z routingiem między sieciami VLAN. Poznaliśmy metody pozwalające na połącznie ze sobą sieci VLAN. Każdą z metod poznalismy od strony zarówno teoretycznej jak i praktycznej.
2.5. Koncepcje STP
Protokół STP, Spanning Tree Protocol jest nie tyle co protokołem sieciowym, co pewnego rodzaju standardem zapewniającym możliwość istnienia łączy nadmiarowych w sieciach przełączanych - opartych na przełącznikach, bez powstawania pętli.
2.5.1. Nadmiarowość w siech przełączanych
Weźmy pod uwagę taką topologię fizyczną, w której mamy trzy przełączniki i każdy przełącznik jest połączony z każdym, do przełączników podłączonych jest kilka komputerów. Cała topologia, znajduje się w jednej domenie rozgłoszeniowej. Jak będzie wyglądać transmisja danych w takiej sieci? Otóż załóżmy, że jeden komputer chce wysłać wiadomość do komputera podłączonego do innego przełącznika. Na początku musi poznać jego adres fizyczny, więc wysyła zapytanie ARP. Zapytania ARP są transmisją broadcast - adresowaną do każdego hosta w sieci. Takie zapytanie na początku osiągnie przełącznik brzegowy pytającego. Następnie ten przełącznika roześle pakiet na wszystkie swoje porty. Zapytanie trafia do pozostałych przełączników, a te nie wiele myśląc - ze względu, że to broadcast, przekażą je dalej na wszystkie swoje porty, poza tym, z którego dane zostały odebrane. Warto pamiętać, że te przełącznik są połączone każdy z każdym. Spowoduje to aktualizację tablicy MAC, tj. według tego przełącznika komputer wysłający pakiet ARP, jest teraz wpięty w porty, w który fizycznie jest wpięty jeden z przełączników. Ten stan utrzyma się do momentu, aż nie przyjdzie to samo zapytanie ARP z drugiego przełącznika, wówczas dojdzie do kolejnej aktualizacji tablicy CAM, no i oczywiście przełączniki dalej przesyłają ten sam pakiet powielając go przy tym. Tak skonfigurowana sieć będzie działać kilka, kilkadziesiąt sekund. Po tym czasie, prawidłowa komunikacja zaniknie. Pozostanie tylko w kółko przesyłanie i powielanie tej samej wiadomości oraz rosnące zużycie zasobów sprzętych przełączników - znaczne zużycie procesora - większy pobór prądu oraz więcej wydzielanego przez urządzenia ciepła.
W wyżej opisanym przypadku mieliśmy doczynienia ze zjawiskiem pętli oraz w jej następstwie z burzą broadcastową. Pętla jest zjawiskiem w którym dochodzi do nienadzrowanego połączenia nadmiarowego w sieciach przełączanych - najprościej rzecz ujmując jeśli z jednego przełącznika przeciągneliśmy dwa kable - jeden na zapas - i podłączymy oba naraz, a przełącznik jest prymitywną wersją przełącznika sieci Ethernet i nie potrafi takiego połączenia nadzorować.
Ramki Ethernetowe nie posiadają mechanizmów kontroli przepływu. Jak w przypadku pakietów IP są pola TTL lub Hop Limit - dzięki czemu mogą one krążyć w nieskończoność. Tego typu problem wykryto już prawie 40 lat temu, mimo że wówczas sieci przełączne kulały, nie było przełączników a raczej mosty. W 1985 powstała pierwsza implementacja algorytmu drzewa rozpiętego, dając tym samym możliwości dla protokołu STP
Zadaie praktyczne - Packet Tracer
Badanie zapobierania pętlom w STP - scenariusz
Badanie zapobiegania pętlom w STP - zadanie
2.5.2. Protokół STP
Protokół STP jest sposobem na zarządzanie łączami nadmiarowymi w taki sposób, aby były one fizycznie obecne i gotowe do pracy, ale nie powodowały przykrych skutków swojej obecności w sieciach przełączanych. Protokół ten oparty jest algorytm STA (Spanning Tree Algorithm), na którym oprzemy omawianie tego mechanizmu. Algorytm ten składa się tak naprawdę z czterech kroków:
- Wybór mostu głównego - ustalenie punktu odnieśnia, według którego będą prowadzone obliczenia określające główne oraz alternatywne kanały komunikacji.
- Określenie ścieżek alternatywnych - obliczenie (określenie) łączy głównych oraz alternatywnych. Łącza alternatywne są blokowane dla głównej komunikacji sieciowej, jednak są wstanie odbierać komunikaty protokołu STP, aby wiedzieć kiedy zarządzające nimi urządzenia mają je przygotować do pracy.
- Topologia wolna od pętli - normalny stan sieci, pozwalający na komunikowanie się hostów ze sobą. Mimo tego komunikaty protokołu STP są dalej transmitowane.
- Ponowne obliczenia ścieżek - ten krok wykonywany jest w przypadku awarii jedej z głównych ścieżek podczas 3-go kroku, wówczas wymagane jest ponowne przeliczenie kanałów komunikacji.
Na przełącznikach Cisco protokół STP jest domyślnie włączony.
2.5.3. Działanie STP
Wyjaśnienie działania STP, opiera się na omówieniu dwóch pierwszych kroków alogorytmu. Pierwszy jest czynnością, wprost wykonywaną przez algorytm, ale krok drugi można podzielić na trzy mniejsze czynności:
- Wybór portów głównych
- Wybór portów desygnowanych
- Wybór portów alternatywnych (zablokowanych)
Przełączniki podczas działania STP, przesłają informacje na temat protokołu w jednostkach BPDU - Bridge Protocol Data Units. Komunikaty te zawierają ważną informację jaką jest BID - Bridge IDentifier - identyfikator mostu. Algorytm STA jest dość starym mechnizmem, w czasach jego opracowywania nie było czegoś takiego jak przełącznik - wówczas używało się mostów. Na identyfikator mostu składa się:
- Priorytet - może być definiowany przez administratora. Domyślnie w urządzeniach Cisco wynosi on 32768. Zakres wartości priorytetu wynosi 0 - 61440.
- Rozszerzony identyfikator systemu - to pole zawiera identyfikator sieci VLAN.
- Adres MAC - adres MAC przełącznika.
Wartość BID, często pełni rolę decyzyjną w protokole STP. Na początku porównywana (między przełącznikami) jest suma priorytetu oraz rozszerzonego identyfikatora. Jeśli one są takie same - np. w przełącznikach Cisco pracujących w VLAN-ie 1 - to w takiej sytuacji porównywane są adresy MAC. Najniższa wartość szesnastkowa adresu MAC wygrywa.
Pierwsza czynność algorytmu czyli wybór mostu głównego opiera się właśnie na BID. Na początku pod uwagę brana jest wyżej opisana suma, którą potocznie nazywa się priorytetem. Jeśli wynik nie będzie roztrzygający, wówczas zostanie użyty adres MAC. Tak wybrany przełącznik staję się punktem odniesienia do dalszych czynności algorytmu.
Następną czynnością jest wybór portu głównego - port ten jest wybierany na podstawie najniższego kosztu ścieżki do mostu głównego.
Koszt ścieżki obliczany jest na podstawie wszystkich łączy prowadzących do mostu głównego. Determinującym czynnikiem jest przepustowość takiego łącza. Domyślnie przyjmuje się, że łącza:
- 10Gb/s - koszt: 2,
- 1Gb/s - koszt: 4,
- 100Mb/s - koszt: 19,
- 10Mb/s - koszt: 100,
Te wartości pochodzą ze specyfikacji protokołu STP z 1998 (802.1D-1998), są one domyślne, a pomimo tego jest możliwość ich zmiany, aby lepiej zarządzać możliwymi ścieżkami.
Jeden z przełączników ma dwie ścieżki, jedna wpięta jest bezpośrednio do mostu głównego natomiast druga, przechodzi przez jeszcze jeden przełącznik. Przełączniki mają przepustowość łączy 100Mb/s. Zatem ta pierwsza ścieżka będzie mieć koszt równy 19, a ta druga 38. Zatem, który port będzie portem głównym? W przypadku sieci o różnych przepustowościach określenie portów głównych wydaje się proste, ale co jeśli mamy wszędzie taki sam koszt? Tutaj sprawa się komplikuje i mamy do wyboru trzy różne metody, któraś z nich na pewno wyznaczy port główny.
- Najniższy BID - w przypadku kiedy jeden z przełączników ma problem z jasnym określeniem portu głównego (na podstawie kosztów), wykorzystuje on BID z ramek BPDU i w momencie rostrzygnięcia, który BID jest najniższy, to port tego przełącznika staje się portem głównym. Natomiast ten drugi będzie portem alternatywnym (zablokowanym).
- Najniższy priorytet portu - wykorzystanie tej metody ma miejsce w momencie gdy łączymy ze sobą dwa przełączniki ścieżkami o tych samych kosztach. Wtenczas brany jest pod uwagę priorytet portu - domyślnie wynosi on 128. Jeśli z jakiegoś powodu ustawimy na jednym porcie niższy priorytet, to ten port będzie portem alternatywnym (zablokowanym), a ten drugi stanie się portem głównym.
- Najniższy identyfikator portu - ta metoda jest ostatecznością. W przypadku takiej samej sytuacji jak w przy najniższym priorytecie portu. W tym przypadku wszystkie porty mają priorytet równy 128. To o porcie głównym decyduje najniższy identyfikator portu. Jeśli podłączone są porty 1 i 2, to najniższym będzie 1 i to ten port będzie głównym, natomiast drugi zostanie zablokowany (port alternatywny).
Drugim krokiem określenia ścieżek alternatywnych protokołu jest STP, jest wybór portów desygnowanych. Jest określenie portu w segmencie (z dwóch przełączników), który ma wewnętrzną ścieżkę do mostu głównego. Innymi słowy ma najlepszą drogę do odbierania ruchu kierowanego do mostu głównego. Ja to wolę określać słowami, który ma najbliżej do mostu głównego. Port desygnowany to port do którego połączony jest port główny.
W przypadku mostu głównego, wszystkie jego podłączone porty są desygnowane. W końcu on ma najlepszą drogę do odbieranie ruchu do samego siebie. Podobnie jest z przełącznikami, do których podłączone są hosty porty brzegowe (port, do którego podłączono inne urządzenie niż przełącznik) są portami desygnowanymi.
Do roztrzygnięcia pozostaje segment, który nie ma portu głównego, co wtedy? W tym przypadku pojawia się czynnik, który nie raz rozstrzygał remisy w protokole STP, czyli BID. Przełącznik o najniższym BID ustawi swój port w tym segmencie jako port desygnowany.
Ostatnią czynnością wykonywaną na ostatnim porcie jest ustawienie go jako portu alternatywnego. Port ten jest blokowany dla normalnego ruchu sieciowego. Jest on w tym stanie odbierać jedynie ramki BPDU.
Zestawienie w pełni działającej topologii wolnej od pętli, a jednocześnie zapewniającej nadmiarowość nazywane jest konwergencją. Konwergencja STP jest dość ściśle określona w czasie. Oczywście, aby zapewnić jak najlepszą elastyczność możemy manipulować tymi wartościami czasowymi. Nie mniej jednak przyjmują one następujące wartości.
- Hello Timer - czas Hello to odstęp między kolejnym ramkami BPDU, domyślnie ten czas to 2 sekundy. Można to zmienić ustawiając czas od 1 do 10 sekund.
- Forward Delay Time - opóźnienie przekazywania, jest to czas, w którym port jest wstanie nasłuchiwania i uczenia się. Domyślną wartością jest 15 sekund. Można zmodyfikować ten czas przypisując wartości od 4 do 30 sekund.
- Max Age Time - maksymalny wiek to czas, w którym przełącznik czeka, zanim podejmie próbę zmiany topologii STP. Domyślnie są to 2 sekundy. Czas ten można zmienić ustawiając wartości od 1 do 10 sekund.
Działanie protokołu STP opiera się na wymianie między przełącznikami ramek BPDU. Jeśli port przechodził by odrazu ze stanu blokowania do stanu przekazywania, mogłoby brakować pewnych informacji a to może doprowadzić do pętli. Dlatego też STP wyróżnia pieć stanów, w których znajdują się porty.
- Blokowanie - Port nie przekazuje ramek Ethernet-owych, jedynie nasłuchuje ramek BPDU w celu określenia mostu głównego. Ramki BPDU zawierają informacje o rolach portów jakie biorą udział w obecnej topologii STP. Port, który przez Max Age nie odbierze żadnej ramki BPDU, automatycznie przechodzi w stan blokowania. Podczas blokowania portu, wpisy w tablicy MAC nie są aktualizowane.
- Nasłuchiwanie - Port z blokowania przechodzi w tryb nasłuchiwania, obiera ramki BPDU w celu określenia ścieżki do mostu głównego oraz wysyła własne ramki BPDU, aby poinformować o inne przełączniki o tym, że przygotowuje się do czynnego udziału w topologii. W tym trybie port dalej nie przekazauje ramek Ethernet oraz nie aktualizuje wpisów w tablicy MAC.
- Uczenie - Po stanie nasłuchiwania port, przechodzi w stan uczenia się. Odbiera i wysyła ramki BPDU i przygotowuje się do przekazywania ramek Ethernet i zaczyna wypełniać tablicę MAC, ale jeszcze nie przesyła ramek użytkowników.
- Przekazywanie - Normalny tryb pracy portu. Port odbiera i wysyła ramki BPDU, aktualizuje tablice MAC oraz przekazuje ramki użytkowników.
- Wyłączony - port wyłączony administracyjnie nie odbiera ani nie wysła żadnego ruchu, nawet ramek BPDU. Nie uczestniczy w procesie STP.
Istnieje odmiana protokołu STP, dedykowana dla VLAN-ów. Pozwala na ona na obliczenie topologii STP, dla każdej z wirtualnych sieci. Co daje nam wiele różnych mostów głównych i wiele różnych oznaczeń portów. Tego rodzaju algorytm nosi nazwę PVST - Per-Vlan Spanning Tree. O innych odmianach protokołu STP, będzie cały następny podrozdział.
2.5.3. Ewolucja STP
Algorytm STA, na którym oparty jest protokół STP, będzie mieć w przyszłym roku 40 lat. Omawiany przez nas, w tym rozdziale protokół został ratyfikowany 1998 roku, sądząc po jego oznaczeniu 802.1D-1998. Przez ten czas całe 26 lat, wiele rzeczy uległo zmienianie. Z pewnością wzrosły prędkości używane przez dzisiejsze sieci, ale również i wymagania co do ich konfiguracji. Rzadko kiedy można spotkać sieć bez segmentacji czy bez sieci VLAN, a w takich środowiskach raczej odnalazłby się oryginalny bohater tego tematu. Obecnie przełączniki Cisco z serii Catalyst wykorzystują jako protokoł STP, w wersji PVST+ - to czym ona jest dowiemy się tym pod rozdziale.
Z teoretycznego punktu widzenia odmiany protokoły STP, operają się na mieszaniu funkcji RSTP - Rapid STP lub PVST. O PVST wspominałem pod koniec poprzedniego podrozdziału. Natomiast RSTP jest klasyczną wersją STP z przyspieszoną konwergencją.
W przypadku RSTP stany portów zostały uproszczone. Stany STP takie jak: wyłączony, zablokowany, nasłuchiwanie, w przypadku RSTP mają jedno określenie stanu odrzucania. Podobnie jest w przypadku ról portów - port (w nomenklaturze STP) zablokowany/niedesygnowany, jest dla RSTP portem alternatywnym. RSTP również z pojęcia portu alternatywnego, wyciąga pojęcie portu zapasowego jest port, do którego podłączono nadmiarowo koncentrator. Port zapasowy występuje wyjątkowo rzadko.
Ewolucja protokół STP wyklarowała również kilka technologii takich PortFast, czy BPDU Guard. Funkcja PortFast stosowana jest wyłącznie na portach brzegowych, do których podłączane są hosty sieci, służy ona szybkiemu przełączeniu roli portu z zablokowanej na przekazywanie. Jest to podyktowane potrzebą przyspieszenia podniesienia portu do stanu użyteczności, tak aby hosty miały szanse skomunikować się z mechanizmami automatycznej konfiguracji hosta (DHCP).
Mechanizm BPDU Guard jest mechanizmem chroniącym porty brzegowe przed komunikatami protokołu STP - ramkami BPDU. Jeśli taka ramka pojawi się na porcie z włączoną funkcją PortFast, to wówczas port zostaje przełączony w stan errdisabled (wyłączony przez błąd) i administrator musi go podnieść ręcznie. Jest to jeden z mechnizmów ochronnych przed potencjalną pętlą. Działanie tego mechanizmu najczęsciej wywołuje podłączenie do portu brzegowego kolejnego przełącznika.
Pomimo, że STP jest powszechnie stosowane to w najbliższym czasie lub już zostało zastąpione przez protokołu routingu warstwy 3 - stosowanie przełączników warstwy 3. Oferują one lepszą wydajność i przewidywalność niż protokół STP.
Natomiast z samych odmian protokołu STP możemy wymieć:
- PVST+ - możliwe uruchomienie instancji STP dla każdego VLAN-u z osobna oraz funkcje dodatkowe jak PortFast i BPDU Guard (protokół własnościowy Cisco).
- 802.1D-2004 - aktualizacja oryginalnego standardu STP, dodając funkcje 802.1w
- RSTP - 802.1w, przyspieszenie konwergencji STP
- Rapid PVST+ - przyspieszona wersja PVST+ (protokoł własnościowy Cisco).
- MST - odmiana protokołu STP, pozwalająca łączyć ze sobą sieci VLAN, z wykorzystaniem tej samej logicznej bądź fizycznej topologii STP. Wykorzystano tutaj także przyspieszenie z wersji Rapid protokołu STP oraz funkcje dodatkowe (własnościowy protokół Cisco).
- MSTP - wolna odmiana MST firmy Cisco, zaprojektowana przez IEEE.
Podsumowanie
W tym rozdziale dowiedziliśmy się w jaki sposób zapewnić nadmiarowe łącza w sieci przełączanej bez ryzyka pętli a w konsekwencji burzy broadcastowej. Możemy tego dokonać za pomocą protokołu STP. Poznaliśmy sposób działania protokołu STP - jak wybiera on odpowiednie ścieżki i porty. Na koniec omówiliśmy odmiany protokołu, które są jego odpowiedzią na dynamicznie zmieniające się warunki sieciowe w obecnych czasach.
2.6. Technologia EtherChannel
Wróćmy na chwilę do topologii, znanej z rozdziału o STP. Mamy trzy przełączniki i łączym je każdy z każdym. Wprowadźmy zmiany do topologii dodając do każdego łącza, po jednym dodatkowym łączu zapasowym. Z uwagi na to, że STP jest domyślnie włączone, to z dostępnych 6 fizycznych łączy tylko 2 będą używane. Więc trochę szkoda naszych pieniędzy, które wydaliśmy na te dodatkowe łącza. Nie mniej jednak istnieje technologia, która pozwoli nam wykorzystać większość łączy, a po mimo tego, protokół STP dalej będzie działać przez co wykorzystanę będą dodatkowe 2 łącza, co daje już 66% wykorzystanej infrastruktury, a nie 33%. Technologią tego typu jest agregacja łączy, w przypadku firmy Cisco mówimy o technologii EtherChannel. Ta technologia to nie tylko lepsze wykorzystanie łączy nadmiarowych, ale także zwiększe ich przepustowości, przy czym tutaj należy pamiętać o tym, że ta wspólna przepustowość nigdy nie będzie równa sumie natywnych przepustowości łączy, wykorzystanych do agregacji. Ale będzie znajdować się gdzieś bliżej tej liczy niż w przypadku pojedynczego łącza.
2.6.1. Działanie EtherChannel
Technologia EtherChannel posiada wiele zalet, między innymi takie jak:
- Możliwość przeprowadzenia spójnej konfiguracji dla wszystkich portów zagregowanych w EtherChannel. Taką konfigurację przeprowadza się dla interfejsu agregującego (Port-Channel).
- Oparcie EtherChannel na portach przełącznika, niweluje zakup bardziej wydajnych urządzeń w celu zwiększenia przepustowości.
- EtherChannel równoważy obciążenia pomiędzy połączeniami tego samego kanału. W zależności od platfomy sprzetowej może wykorzystać do tego różne metody.
- Kanał EtherChannel jest jednym łączem logicznym i tak też traktuje je protokół STP. Dzięki czemu możemy wykorzystać więcej łączy.
- EtherChanel zapewnia nadmiarowość jest jedno logiczne połączenie, utrata jednego z fizycznych łączy nie powoduje zmian topologii.
Po za zaletami ta technologia ma też kilka ograniczeń:
- Rodzaje interfejsów nie mogą być mieszane. Porty FastEthernetowe i GigabitEthernet nie mogą być łączone w jeden EtherChannel.
- Każdy EtherChannel, może składać się z maksymalnie 8 portów dając przespustować kanału do 800Mb/s lub do 8Gb/s.
- Przełączniki serii Catalyst 2960 mogą mieć maksymalnie 6 kanałów.
- Konfiguracja portów grupy EtherChannel, musi się zgadzać na obu urządzeniach. Jeśli na jednym urządzeniu są to trunki to na drugim też muszą być w tej samej natywnej sieci VLAN.
- Konfigucja EtherChannel będzie mieć wpływ na porty fizyczne przypisane do kanałów.
EtherChannele mogą być tworzone na zasadzie auto-negocjacji - przy użyciu protokołów PAgP lub LACP. Jednak jest również możliwość skonfigurowania statycznego lub bezwarunkowego EtherChannel bez udziału wyżej wymienionych protokołów, nie mniej jednak omówimy je sobie.
Protokół PAgP jest zastrzeżonym protokołem firmy Cisco, pomaga w automatycznym tworzeniu połączeń EtherChannel. PAgP umożliwia tworzenie łącza EtherChannel poprzez wykrycie konfiguracji każdej ze stron i zapewnienie, że linki są kompatybilne w taki sposób, że EtherChannel może być włączony w razie potrzeby. Tryby dla PAgP są następujące:
- on - Tryb ten zmusza do uruchomienia EtherChannel bez protokołu PAgP. Interfejsy skonfigurowane w tym trybie nie wymieniają pakietów PAgP.
- desirable - Ten tryb protokołu umieszcza interfejs w stanie aktywnej negocjacji. Interfejs rozpoczyna negocjacje z innymi interfejsami po przez wysłanie pakietów PAgP.
- auto - Ten tryb umieszcza port w trybie pasywnej negocjacji. Interfejs odpowiada pakietom PAgP, ale nie inicjuje negocjacji.
Ustawienie tych stanów na poszczególnych portach decydują o tym czy
EtherChannel zostanie w ogóle zestawione. Domyślnie
EtherChannel nie jest zestawiane. Polecenia konfiguracji mogą
też zostać poprzedzone słowem no to
wówczas spowoduje wyłączenie EtherChannel.
Tryb on powoduje, że manualne umieszczenie interfejsu w kanale EtherChannel. Działa to tylko w tedy gdy druga strona jest również w trybie on. Tryb on w ogóle nie negocjuje więc jeśli druga strona jest w jednym z trybów protokołu PAgP, to kanał się nie utworzy.
Poniżej znajduje się tabela przedstawiająca tryby protokołu PAgP ustawione na portach dwóch przełączników oraz ich skuteczność w zestawianiu kanału EtherChannel.
| S1 | S2 | Ustanowienie kanału |
|---|---|---|
| On | On | Tak |
| On | Desirable/Auto | Nie |
| Desirable | Desirable | Tak |
| Desirable | Auto | Tak |
| Auto | Desirable | Tak |
| Auto | Auto | Nie |
Drugim protokołem w tym przypadku wolnym - opracowywanym przez IEEE (802.3ad) jest LACP. Jest on łudząco podobny do protokołu PAgP Różnice polegają na zestawianiu kanału (jednak, nie będziemy się tym tutaj zajmować), możliwość wykorzystania środowisk wielu producentów w tym i Cisco oraz w nazewnictwie trybu protokołu.
| S1 | S2 | Ustanowienie kanału |
|---|---|---|
| On | On | Tak |
| On | Active/Passive | Nie |
| Active | Active | Tak |
| Active | Passive | Tak |
| Passive | Active | Tak |
| Passive | Passive | Nie |
2.6.2. Konfiguracja EtherChannel
W poprzednim podrozdziale poznaliśmy teorie dotyczącą EtherChannel. Teraz czas nieco pobrudzić sobie łapki i spróbować skonfigrować kilka kanałów, a przy najmniej nauczyć się w jaki sposób można to zrobić.
Na początku musimy upewnić się, że nasze środowisko (przełączniki, porty przełącznika) spełniają odpowiednie wymagania.
- Obsługa EtherChannel - porty muszą wspierać technologię EtherChannel.
- Szybkość i dupleks - porty muszą być tej samej przepustowości oraz w tym samym trybie dupleksu.
- Zgodność VLAN - porty muszą być w tym samym VLAN-ie, lub skonfigurowane jako trunk.
- Zakres VLAN - Zakresy dozwolonych sieci VLAN na łączach trunk musi być taki sam dla wszystkich portów.
Metody konfiguracji EtherChannel wyglądają podobnie do siebie w zależności od protokołu jaki użyjemy. Różnice będą polegać na na określeniu trybu protokołu. Poniżej przykładowa konfiguracja kanału EtherChannel na jednej ze stron, dla protokołu LACP.
S3(config)#int range fa0/23-24 S3(config-if-range)#shutdown ... S3(config-if-range)#channel-group 1 mode active S3(config-if-range)# Creating a port-channel interface Port-channel 1 S3(config-if-range)#no shutdown
Ta konfiguracja jest bardzo podstawowa. Możemy ją rozszerzyć o np. nośność sieci VLAN, oczywiście pamiętając o wymaganiach.
Zadanie praktyczne - Packet Tracer
Konfiguracja EtherChannel - scenariusz
Konfiguracja EtherChannel - zadanie
Laboratorium
2.6.3. Rozwiązywanie problemów z EtherChannel
Wcześniej konfigurowaliśmy kanał EtherChannel i chcielibyśmy
się dowiedzieć czy on w ogóle działa. Aby wyświetlić informacje w
IOS na temat EtherChannel możemy posłóżyć się kilkoma
poleceniami, ale najbardziej przydatym z nich będzie
show etherchannel summary. Tak
się prezentuje wyjście tego polecenia.
S3>show etherchannel sum
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 2
Number of aggregators: 2
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) LACP Fa0/23(P) Fa0/24(P)
2 Po2(SU) LACP Fa0/21(P) Fa0/22(P)
Jak możemy zauważyć większość wyjścia tego polecenia to legenda, która
jest potrzebna do objaśnienia zwięzłej tabeli na dole. Mamy dwie
grupy, które są własnie tymi EtherChannel-ami. W drugiej
kolumnie pokazano Port-channel-e,
które są wirtualnymi interfejsami reprezentującymi kanał. Na ich
podstawie możemy skonfigurować nasze kanały jako trunki.
W nawiasach obok nazw tych interfejsów
(Po1), znajduje się stan kanału. W
przypadku stanu SU to jest to
EtherChannel warstwy drugiej w użyciu (jest operacyjny) -
zgodnie z legendą. W kolejnej kolumnie znajduje się protokół użyty do
agregacji oraz porty, które wchodzą w skład kanału ich rola w nim w
tym przypadku, pokazane na przykładnie porty, biorą aktywny udział
w kanale.
Innymi poleceniami wartymi uwagi podczas pracy z EtherChannel są:
show interfaces port-chanelshow etherchannel port-channelshow interfaces etherchannel
Oczywiście podczas konfiguracji czegokolwiek, mogą wystąpić różne problemy. Tak samo jest w przypadku EtherChannel. Poniżej znajduje się kilka powodów, które sprawiają że nasze kanały nie chcą za bardzo działać.
- Porty nie w tych samych sieciach VLAN lub nie są trunkami. Porty mające różne natywne sieci VLAN nie są w stanie utworzyć kanału.
- Skonfigurowano tryb trunk tylko na niektórych, portach kanału.
- Zakres sieci VLAN na wszystkich portach kanału nie jest taki sam.
- Pomieszano protokoły z jednej lub z drugie strony kanału.
Istnieje kilka taki stałych kroków, które mogą pomóc nam rozwiązać problemy związane z działaniem EtherChannel.
- Wyświetl informacje na temat EtherChannel
(
show etherchannel summary) - Zobacz konfigurację kanału portów
(
show run | begin interface port-channel) - Popraw błedy w konfiguracji. Tutaj się warto chwilę zatrzymać,
ponieważ EtherChannel - jej konfiguracja strasnie nie lubi
nadpisywania. Jeśli już musimy poprawić grupę (kanał) to
należy na początku usunąć go za pomocą polecenia:
no interface port-channel X, gdzieXjest numerem grupy. Członport-chanel Xmożna skrócić dopoX. Po usunięciu grupy można przystąpić do jej ponownej konfiguracji. - Zweryfikuj czy EtherChannel działa.
Zadanie praktyczne - Packet Tracer
Rozwiązywanie problemów z EtherChannel - scenariusz
Rozwiązywanie problemów z EtherChannel - zadanie
Podsumowanie
W tym rozdziale dowiedzieliśmy, jak w efektywny sposób wykorzystać dodatkowe łącza nadmiarowe stosując technologię agregacji - EtherChannel. Poznaliśmy sposób działania tej technlogii, metody konfiguracji w systemie IOS oraz rozwiązywanie związanych z nią problemów.
Zadanie praktyczne - Packet Tracer
Implementacja EtherChannel
Implementacja EtherChannel
2.7. DHCPv4
Komputery w sieci, tak jak my ludzie potrzebujemy adresów, żeby otrzymywać móc wysyłać i odbierać komunikaty. Komputerom w sieci możemy przypisać adresy ręcznie - co nazwane jest statyczną konfiguracją hosta, bądź też wykorzystać do tego odpowiednie oprogramowanie, które pozwoli na zautomatyzowanie procesu oraz na bezobsługowe zarządzanie nim. Jedyną czynnością będzie konfiguracja protokołu Dynamic Host Configuration Protocol. Za konfigurację hostów sieci odpowiada konkretny protokół, który dynamicznie przydziela (dzierżawi) adres IPv4 z puli dostępnych adresów, na określony czas lub do momentu kiedy host już go nie potrzebuje. Czas dzierżawy może być zdefiniowany przez administratora, najczęściej są to 24 godziny.
Serwer DHCP działa na zasadzie architektury klient-serwer. Serwerami DHCP, może być dedykowane oprogramowanie instalowane na dystrybucjach Linuksa oraz na systemach MS Windows. Urządzenia z systemem IOS takie jak routery, czy przełączniki warstwy 3 mogą również pełnić rolę serwera DHCP o czym się przekonamy w dalszej części tego materiału.
Komputer będąc skonfigurownym w ten sposób, aby otrzymywał adres autotomatycznie, komunikuje się z serwerem DHCP. Między hostami wymieniane są komunikaty protokóło, rezultatem czego jest wydzierżawienie adresu IP dla tego hosta. Jeśli czas dzierżawy dobiega końca, host komunikuje się z serwerem w celu odnowienia dzierżawy, jeśli klient nie skontaktuje się z serwerem w odpowiednim czas, dzieżawa wygasa, a adres trafia z powrotem do puli - zakresu adresów, przeznaczonych dla tej sieci - i może zostać wydzierżawiony innym hostom. Ten mechanizm pozwala na zwolnienie adresów, które hosty już nie potrzebują, bo są np. wyłączone.
Wymiana komunikatów protokołu DHCP w celu uzyskania dzierżawy wygląda w następujący sposób:
- Klient wysyła ramkę broadcast, zawierającą komunikat DHCPDISCOVER. Klient nie ma adresu IP stąd ten broadcast. Ten komunikat mówi, że dany host szuka serwera DHCP.
- Serwer odpowiada klientowi, za pomocą komunikatu DHCPOFFER, przedstawiając mu już konkretną ofertę adresu jaki dostanie.
- Klient potwierdza dzierżawę adresu za pomocą komunikatu DHCPREQUEST wysyłanego w ramce broadcast. Mimo, że host mógłby wysłać ten komunikat prosto do serwera, z którego otrzymał ofertę, to nie robi tego. Ponieważ w sieciach może istnieć więcej niż jeden serwer DHCP. Wysłanie DHCPREQUEST na broadcast, przekaże informacje innym serwerom DHCP, że host przyją ofertę innego serwera, więc tamte serwery mogą przywrócić proponowany adres z powrotem do puli.
- Serwer na koniec wysła potwierdzenie akceptacji w postaci komunikatu DHCPACK. Teoretycznie komunikacja z serwerem DHCP tutaj się kończy, ale klient wykonuje jescze jedną czynność.
Mianowicie wysyła pakiet ARP z zapytaniem o przydzielony mu właśnie adres. Może zdażyć się taka sytuacja, że mamy część komputerów skonfigurowanych ze statycznymi adresami, a część z dynamicznymi. A na serwerze DHCP nie dokonano odpowiednich wykluczeń z puli. Wówczas serwer DHCP, będzie przydzielać adresy, które już funkcjonują w sieci. Wtedy dochodzi do konfilktu adresów IP.
Odnowienie adresu IP, skraca powyższą procedurę do dwóch ostatnich komunikatów. Klient prosi o odnowienie adresu za pomocą komunikatu DHCPREQUEST, a natomiast serwer odpowiada za pomocą DHCPACK.
2.7.1. Konfiguracja serwera DHCPv4 na Cisco IOS
Poznaliśmy niezbędną teorie, to teraz możemy zmusić IOS, nie tylko na routerze, ale i na przełącznikach też - do pełnienia funkcji serwera DHCPv4.
Możemy tego dokonać za pomocą kilku kroków. Pierwszą czynnością będzie uwzględnienie ewentualnych urządzeń z ustawionymi statycznym adresami IP. Należy dokonać konkretnych wykluczeń, podając zakres adresów, które nie będą przydzielane. Mimo, że nie mamy jeszcze zdefiniowanej puli adresowej to już na samym początku konfiguracji możemy podać tego typu informacje.
Router(config)#ip dhcp excluded-address 192.168.10.1 192.168.10.10
Zakres adresów do wyłączenia przekazujemy podając pierwszy i ostatni
adres. Chcąc wyłączyć jeden pojedynczy adres, podajemy go zaraz
po słowie excluded-address.
Następnym krokiem jest zdefiniowanie puli. W definicji puli podajemy
dodatkowe adresy IP jakie host powinien mieć w swojej konfiguracji,
takie jak adres bramy czy adresy serwerów DNS. Tworzenie puli
rozpoczyna się od wydania poniższego polecenia.
Router(config)#ip dhcp pool LAN10
Po wydaniu tego polecenia zostaniemy przeniesieni do trybu konfiguracji puli. W tym trybie podajemy sieć na podstawie, której zostanie utworzona pula adresów.
Router(dhcp-config)#network 192.168.10.0 255.255.255.0
Następnie dodajemy adres bramy domyślnej oraz serwera DNS:
Router(dhcp-config)#default-router 192.168.10.1 Router(dhcp-config)#dns-servers 8.8.8.8
Po wykonaniu tych czynności, możemy opuścić konfigurację. Serwer DHCP został skonfigurowany i jest on operacyjny. Możemy to sprawdzić ustawiając jeden z interfejsów routera i podłączając do niego komputer.
C:\>ipconfig /all
FastEthernet0 Connection:(default port)
Connection-specific DNS Suffix..:
Physical Address................: 0002.1661.4A3D
Link-local IPv6 Address.........: FE80::202:16FF:FE61:4A3D
IPv6 Address....................: ::
IPv4 Address....................: 192.168.10.11
Subnet Mask.....................: 255.255.255.0
Default Gateway.................: ::
192.168.10.1
DHCP Servers....................: 192.168.10.1
DHCPv6 IAID.....................:
DHCPv6 Client DUID..............: 00-01-00-01-64-36-79-72-00-02-16-61-4A-3D
DNS Servers.....................: ::
8.8.8.8
Teraz kiedy nasz serwer DHCP został skonfigurowany i działa, to możemy poznać polecenia, które pozwalą nam sprawdzić informacje odnośnie działania DHCP w IOS.
show running-config | section dhcp- to polecenie filtruje wyświetlenie bierzącej konfiguracji po kątem występowania sekcjidhcp. Jeśli polecenie zawiera to słowo kluczowe i samo w sobie nie tworzy sekcji, to również zostanie uwzględnione przez ten filtr.Router#show running-config | section dhcp ip dhcp excluded-address 192.168.10.1 192.168.10.10 ip dhcp pool LAN10 network 192.168.10.0 255.255.255.0 default-router 192.168.10.1 dns-server 8.8.8.8
show ip dhcp binding- polecenie wyświetla listę dzierżaw serwera DHCP.
Router#show ip dhcp binding
IP address Client-ID/ Lease expiration Type
Hardware address
192.168.10.11 0002.1661.4A3D -- Automatic
show ip dhcp server statistics -
polecenie zwraca statystyki na temat serwera DHCP. Na Packet Tracerze
to polecenie jest niedostępne, przynajmniej w wersji 8.2.2.Konfiguracja serwera DHCP wydaje się prosta, w momecie gdy znajduje sie on w tej samej sieci lokalnej. A co jeśli będzie znajdować się w innej sieci? Broadcast ramek Ethernet nie może przecież być routowany. Tutaj wymyślono coś takiego jak adres pomocnika. Na interfejsie, który normalnie by oczekiwał na komunikaty DHCPDISCOVER, konfigurujemy adres serwera DHCP w innej sieci. Tworząc z tego interfejsu coś w rodzaju przekaźnika.
Router(config-if)#int gig0/0 Router(config-if)#ip helper-address 192.168.11.2 Router(config-if)#end
W tym przypadku serwer DHCP ma adres
192.168.11.2. Poza komunikatami DHCP
za pomocą tego mechanizmu mogą być przekazywane komunikaty usługi DNS
czy NTP, generalnie te usługi sieciowe, które wykorzystują UDP.
Zadanie praktyczne - Packet Tracer
Konfiguracja DHCPv4 - scenariusz
Konfiguracja DHCPv4 - zadanie
2.7.2. Konfiguracja klient DHCP w systemie Cisco IOS
Konfiguracja interfejsu urządzenia z systemem Cisco IOS jako klienta DHCP, jest banalnie prosta. Sprowadzania się ona do wydania dwóch/trzech poleceń. Już wcześniej konfigurowaliśmy statyczne adresy IP, np. na interfejsach VLAN 1 przełączników. To w tym przypadku sprawa ma się podobnie. Wystarczy, że zamiast wpisywania adresu IP oraz maski podamy jedno słowo - dhcp.
Switch(config)#int vlan 1 Switch(config-if)#ip address Switch(config-if)#ip address dhcp Switch(config-if)#no shutdown Switch#sh ip int br | section Vlan1 Vlan1 192.168.10.4 YES DHCP up up
Podsumowanie
W tym rozdziale zapoznaliśmy z działaniem protokołu automatycznej konfiguracji hosta w wersji 4 - DHCPv4. Dowiedzieliśmy się jak możemy wykorzystać system Cisco IOS w roli serwera DHCP, przekaźnika oraz na koniec klienta.
Zadanie praktyczne - Packet Tracer
Konfiguracja DHCPv4 - scenariusz
Konfiguracja DHCPv4 - zadanie
Laboratorium
2.8. SLAAC i DHCPv6
Podobnie do IPv4, mamy możliwość zarówno statycznej jak i dynamicznej konfiguracji interfejsów sieciowych dla IPv6. Przy czym, znając budowę adresów IPv6, nie wiadomo czy ktoś będzie chciał to robić ręcznie. A w przypadku konfiguracji dynamicznej mamy do wykorzystania trzy metody.
- Metoda autokonfiguracji - SLAAC
- Metoda bezstanowego serwera DHCP - Stateless DHCPv6
- Metoda stanowowego serwera DHCP - Stateful DHCPv6
Omówimy sobie pokolei te metody, a następnie zabierzemy się do konfigurowania każdej z nich w systemie Cisco IOS.
Za nim jednak do tego przjedziemy, krótkie przypomnienie o IPv6. Adres IPv6 ma długość 128 bitów, składa się z 8 hekstetów po 4 cyfyry heksadecymalne. Adresy IPv6 dzielą się na dwie grupy GUA (Global Unicast Address), rozpoczynające się od prefiksu: 2000::/3 oraz LLA (Local Link Address), rozpoczynające się od prefiksu fe80::/10. W przypadku IPv6 do określenia części sieciowej adresu IP wykorzystuje tzw. prefiks - zarezerwowana liczba bitów. W przypadku adresów unicast przeważnie adres dzieli się na pół - prefiks ma długość 64 bitów. Drugie pół adresu IPv6 określa już sam host generując wartości pseudolosowe (w przypadku systemów MS Windows) lub korzystając z algorytmu EUI-64. Ta część adresu nazwana jest identyfikatorem hosta Adresy GUA służą do komunikacji w Internecie, natomiast adresy LLA, ograniczają się do jednej domeny rozgłoszeniowej. Każdy komputer posiada dwa adresy przypisane do swojego interfejsu. Przez co każdy komputer może być w prosty sposób osiągalny z poziomu Internetu. Urządzenia mają również zapisane adresy typu multicast - ff02::1 - adres wszystkich hostów obsługujących IPv6 oraz ff02::2 - adres wszystkich routerów z routingiem IPv6. Te adresy bedą mieć znaczenie przy dynamicznej adresacji hostów. Dynamiczna adresacja hostów, będzie dotyczyć wyłącznie adresów GUA. Adresy LLA, są konfigurowane automatycznie na hostach.
2.8.1. SLAAC
Protokół IPv6, znacznie bardziej angażuje protokół ICMP w wersji 6 do pracy niż miało to miejsce w przypadku IPv4 i ICMPv4. Założenie IPv6 jak i metody konfiguracji SLAAC było takie, że gdzie w sieci musi być jakiś router, i jednym z jego zadań jest wysłanie co 200 sek komunikatu protokołu ICMPv6 zawierającego takie informacje jak:
- Flagi - zbiór bitów, mówiących hostowi w jaki sposób będzie konfigurować adres IPv6 w tej sieci.
- Prefiks - część sieciowa adresu IPv6.
- Długość prefiksu - długość częsci sieciowej adresu IPv6.
Komunikat ten nosi nazwę Router Advertisement, w skrócie RA. Host po podłączeniu do sieci może wysłać inny komunikat ICMPv6 - Router Solicitation - RS, który jest prośbą o wysłanie przez router komunikatu RA. Komunikaty RS jako adres docelowy wykorzystują adres multicast grupy routerów.
Flagi przekazywane w komunikacie RA, wskazują hostowi w jaki sposób będzie odbywać się konfiguracji interfejsu IPv6 w tej sieci. Możemy wyróżnić takie flagi jak:
- M (Managed) - oznacza ona, że konfiguracja IPv6 będzie odbyć się przy użyciu serwera DHCPv6 (W nomenklaturze CCNA, stanowego serwera DHCPv6).
- O (Other) - oznacza ona, że tylko dodatkowe informacje takie jak adresy serwerów DNS, będą dostarczane przez serwer DHCPv6. (W nomenklaturze CCNA, bezstanowy serwer DHCPv6)
- A (Autoconfiguration) - oznacza ona, że adres IPv6 będzie uzyskiwany metodą autokonfiguracji - SLAAC. (Dokument RFC 1970, mówi że ta flaga, znajduje się w sekcji opcji odpowiedzialnej za informacje na temat prefiksu, a nie w samym RA stricte.)
Zatem jeśli host otrzyma komunikat RA z ustawiowymi flagami M=0, O=0 oraz z flagą A=1, w prefix information - oznacza to, że adres musi on sobie ustawić sam. Dokonuje tego przy użyciu prefiksu i jego długości z komunikatu RA oraz przy użyciu samodzielnie wygenerowanego identyfikatora hosta. Czy użyje metod pseudolosowych czy algorytmu EUI-64, to już zależy od systemu operacyjnego. Przy czym tak wygenerowany należy adres, należy sprawdzić. Szanse są nikłe, ale ta czynność jest wykonywana, rozsyłane są między hostami komunikaty ICMPv6 NA (Neighbor Advertisement) oraz NS (Neighbor Solicitation) - co ma być odpowiednikiem protokołu ARP. Host wysła komunikat NS na swój wygenerowany adres i jeśli odpowiedź nie nadejdziej oznacza to, że adres jest operacyjny i może go użyć. W ten sposób działa mechanizm DAD (Duplicate Address Detection).
Ta metoda zapewnia podstawową konfigurację sieciową, pozwalająca na komunikację z hostem. Jednak jeśli był by to zwykły komputer klasy PC, z którego ma korzystać człowiek, to brakuje informacji takich jak adresy serwerów DNS, aby móc korzystać zasobów sieci firmy czy Internetu.
2.8.2. Metoda bezstanowego serwera DHCPv6
Metoda ta działa na zasadzie uzupełnienia konfiguracji interfesów sieciowych IPv6, wstępnie skonfigurowanych przez metodę SLAAC. Dlatego też możemy spotkać się określeniem SLAAC+DHCPv6. Działanie tej metody zakłada, że w sieci znajduje się serwer DHCPv6, mimo to host dalej będą korzystać informacji zawartych w RA, następnie po proszą serwer DHCPv6 o uzupełnienie informacji dodatkowych.
W przypadku metody bezstanowego serwera DHCPv6, host odbiera RA z ustawioną flagą M=0, O=1 i A=1. Ustawia on swoje podstawowe parametry sieciowe, na podstawie informacji zawartych komunikacie (poprzez użycie SLAAC) następnie host wysła DHCPv6 SOLICIT w celu odnalezienia serwera DHCP (coś w rodzaju, DHCPDISCOVER) w odpowiedzi otrzymuje DHCPv6 ADVERTISE, z informacją że jest serwer taki, a taki i obsługuje on protokoł DHCPv6. To wówczas host wysła komunikat DHCPv6 INFORMATION-REQUEST już na adres serwera uzyskany z poprzeniego pakietu. W odpowiedzi uzyska komunikat DHCPv6 REPLY o treści odpowiedniej dla DHCPv6 INFORMATION-REQUEST.
2.8.3. Metoda stanowego serwera DHCPv6
Mimo, że SLAAC+DHCPv6, rozwiązuje problemy z niepełną konfiguracją z komunikatów RA, wykorzystywanych przez SLAAC, to w sieciach firmowych chcielibyśmy mieć kontrolę, chociażby nad tym, kto się podłacza do naszej sieci. Dlatego też wprowadzono metodę: stanowego serwera DHCPv6, którego działanie jest podobne do serwera DHCPv4.
Host wysła komunikat RS, lub udaje mu się odebrać komunikat RA. W nim flagi są ustawione: M=1, O=0, A=0. Możemy się czasami spotkać z twierdzeniem, że flagi O, nie ma w ogóle, ale jest to raczej błąd. Tak ustawione flagi mówią hostowi, że ma korzystać z serwera DHCPv6. To host rozpoczyna wymianę pakietów, podobną do metody bezstanowowej, a różniącej się tym, że nie korzysta on z informacji zawartych w RA (wszystkich), tylko rozpoczyna poszukiwanie serwera DHCPv6. Główną różnicą między tymi metodami jest użycie komunikatu DHCPv6 REQUEST, zamiast INFORMATION-REQUEST. Inna również będzie treść wiadomości DHCPv6 REPLY.
Ważną informacją obejmującą wszystkie metody dynamicznej konfiguracji IPv6 jest to, że hosty będą korzystać z adresu link-local routera (adresu źródłowego komunikatu RA) jako bramy domyślnej. Nie będą korzystać z informacji przekazywanych nawet przez serwer DHCPv6.
2.8.4. Konfiguracja DHCPv6 na Cisco IOS
System operacyjny Cisco IOS, jest wstanie świadczyć usługę DHCP również dla IPv6. Przeprowadzimy następujące konfigurację:
- Bezstanowego DHCPv6
- Stanowego DHCPv6
- Klienta DHCPv6
- Agenta przekazywania
W przypadku bezstanowego serwera DHCP, na routerze w pierwszej kolejności włączamy routing IPv6. Zawsze jest on domyślnie wyłączony.
Srv-DHCPv6(config)#ipv6 unicast-routing
Następnie definiujemy nowa pulę adresów.
Srv-DHCPv6(config)#ipv6 dhcp pool IPV6-STATELESS
Konfigurujemy pule, dodając te opcje, które chcemy aby klienci naszej sieci otrzymywali z serwera DHCPv6.
Srv-DHCPv6(config-dhcpv6)#dns-server 2001:db8:acad:1::254 Srv-DHCPv6(config-dhcpv6)#domain-name example.com
Teraz musimy przypisać pulę do interfejsu, ale także zmodyfikować flagę w komunikatach RA. Dokonujemy tego za pomocą poniższych poleceń.
Srv-DHCPv6(config-if)#ipv6 nd other-config-flag Srv-DHCPv6(config-if)#ipv6 dhcp server IPV6-STATELESS
Pierwsze polecenie:
ipv6 nd other-config-flag ustawia
flagę O w komunikatach RA. Natomiast drugie polecenie:
ipv6 dhcp server IPV6-STATELESS
przypisuje pulę interfejsu. Teraz możemy skonfigurować klienckiego
PC-ta, aby pobrał konfigurację IPv6 z naszej infrastruktury.
Cisco Packet Tracer PC Command Line 1.0
C:\>ipconfig /all
FastEthernet0 Connection:(default port)
Connection-specific DNS Suffix..: example.com
Physical Address................: 0060.4784.E138
Link-local IPv6 Address.........: FE80::260:47FF:FE84:E138
IPv6 Address....................: 2001:DB8:ACAD:1:260:47FF:FE84:E138
IPv4 Address....................: 0.0.0.0
Subnet Mask.....................: 0.0.0.0
Default Gateway.................: FE80::1
0.0.0.0
DHCP Servers....................: 0.0.0.0
DHCPv6 IAID.....................: 1699464132
DHCPv6 Client DUID..............: 00-01-00-01-61-90-B4-E8-00-60-47-84-E1-38
DNS Servers.....................: 2001:DB8:ACAD:1::254
0.0.0.0
Konfiguracja PC-ta, jest banalna wystarczy kliknąć jedną opcje. A co w przypadku systemu Cisco IOS? Spróbujmy to zrobić, wykorzystując do tego drugi router. Po przejściu do konfiguracji globalnej, włączamy routing IPv6.
Cli-DHCPv6(config)#ipv6 unicast-routing
Następnie włączamy IPv6 na interfejsie sieciowym i ustawiamy aby pobrał on konfigurację z DHCP. Na koniec podnosimy interfejs.
Cli-DHCPv6(config)#ipv6 unicast-routing
Cli-DHCPv6(config)#int gig0/0/1
Cli-DHCPv6(config-if)#ipv6 enable
Cli-DHCPv6(config-if)#ipv6 address autoconfig
Cli-DHCPv6(config-if)#no shut
Cli-DHCPv6(config-if)#end
Cli-DHCPv6#sh ipv6 int br
GigabitEthernet0/0/0 [administratively down/down]
unassigned
GigabitEthernet0/0/1 [up/up]
FE80::201:64FF:FE98:9802
2001:DB8:ACAD:1:201:64FF:FE98:9802
GigabitEthernet0/0/2 [administratively down/down]
unassigned
Vlan1 [administratively down/down]
unassigned
Cli-DHCPv6#sh ipv6 dhcp interface
GigabitEthernet0/0/1 is in client mode
State is INFORMATION-REQUEST(0)
Rapid-Commit: disabled
Ostatnie dwa polecenia:
sh ipv6 int br
(show ipv6 interface brief) oraz
sh ipv6 dhcp interface mogą nam
posłużyć do sprawdzenia konfiguracji IPv6 interfejsów oraz konfiguracji
DHCPv6 interfejsu. W tym przypadku na podstawie wyjścia drugiego
polecenia, może stwiedzić, że działa on w trybie bezstanowego serwera
DHCPv6.
Kolejny rodzajem konfiguracji jaki możemym przeprowadzić jest stanowy serwer DHCPv6 oraz stanowy klient. Konfiguracja dla serwera wygląda w następujący sposób:
Srv2-DHCPv6(config)#ipv6 unicast-routing Srv2-DHCPv6(config)#ipv6 dhcp pool IPV6-STATEFUL Srv2-DHCPv6(config-dhcpv6)#address prefix 2001:db8:acad:1::/64 Srv2-DHCPv6(config-dhcpv6)#dns-server 2001:4860:4860::8888 Srv2-DHCPv6(config-dhcpv6)#domain-name example.com Srv2-DHCPv6(config-dhcpv6)#exit Srv2-DHCPv6(config)#int gig0/0/1 Srv2-DHCPv6(config-if)#ipv6 addr 2001:db8:acad:1::1/64 Srv2-DHCPv6(config-if)#ipv6 addr fe80::1 link-local Srv2-DHCPv6(config-if)#ipv6 nd managed-config-flag Srv2-DHCPv6(config-if)#ipv6 dhcp server IPV6-STATEFUL Srv2-DHCPv6(config-if)#no shutdown
Konfigurując IOS jako serwer stanowy DHCPv6, musimy w definicji puli wpisać prefiks naszej sieci. Następnie w konfiguracji interfejsu ustawiamy flagę M i przypisujemy odpowiednią do interfejsu pulę DHCPv6. Reszta konfiguracji pozostaje bez zmian.
W materiałach występuje jeszcze jedno polecenie:
ipv6 nd prefix default no-autoconfig
jednak może być ono niedostępne w wersjach oprogramowania IOS
dostarczanych wraz z Packet Tracer-em.
Natomiast konfiguracja stanowego klienta wygląda w opisany poniżej sposób.
Cli2-DHCPv6(config)#ipv6 unicast-routing
Cli2-DHCPv6(config)#int gig0/0/1
Cli2-DHCPv6(config-if)#ipv6 enable
Cli2-DHCPv6(config-if)#ipv6 address dhcp
Cli2-DHCPv6(config-if)#no shutdown
Cli2-DHCPv6#sh ipv6 int br
GigabitEthernet0/0/0 [administratively down/down]
unassigned
GigabitEthernet0/0/1 [up/up]
FE80::201:96FF:FEB3:8A02
2001:DB8:ACAD:1:D0CF:E066:3BF5:2825
GigabitEthernet0/0/2 [administratively down/down]
unassigned
Vlan1 [administratively down/down]
unassigned
Cli2-DHCPv6#sh ipv6 dhcp interface
GigabitEthernet0/0/1 is in client mode
State is OPEN
Renew will be sent in 0d0h
List of known servers:
Reachable via address: FE80::1
DUID: 0003000100062ACD7E01
Preference: 0
Configuration parameters:
IA PD: IA ID 226950255, T1 0, T2 0
Address: 2001:DB8:ACAD:1:D0CF:E066:3BF5:2825/64
preferred lifetime 86400, valid lifetime 172800
expires at September 7 2024 3:47:3 pm (172800 seconds)
DNS server: 2001:4860:4860::8888
Domain name: example.com
Information refresh time: 0
Prefix name:
Rapid-Commit: disabled
W taki sposób wygląda to od strony serwera:
Srv2-DHCPv6#show ipv6 dhcp interface
GigabitEthernet0/0/1 is in server mode
Using pool: IPV6-STATEFUL
Preference value: 0
Hint from client: ignored
Rapid-Commit: disabled
Srv2-DHCPv6#show ipv6 dhcp binding
Client: FE80::201:96FF:FEB3:8A02
DUID: 00030001000196B38A01
IA NA: IA ID 226950255, T1 0, T2 0
Address: 2001:DB8:ACAD:1:D0CF:E066:3BF5:2825
preferred lifetime 86400, valid lifetime 172800
expires at September 7 2024 3:50:18 pm (172800 seconds)
Srv2-DHCPv6#show ipv6 dhcp pool
DHCPv6 pool: IPV6-STATEFUL
Address allocation prefix: 2001:db8:acad:1::/64 valid 172800 preferred 86400 (2 in use, 0 conflicts)
DNS server: 2001:4860:4860::8888
Domain name: example.com
Active clients: 1
binding, przedstawia listę klientów
serwera DHCPv6. Natomiast pool,
pokazuje nam statystyki oraz opcje dodane do utworzynych na serwerze
pul adresowych.
Ostatnią konfiguracją będzie konfiguracja agenta przekazującego. Nie mniej jednak na Packet Tracerze, nie będziemy w stanie tego zrobić. Dlatego można potraktować to jako suchą wiedzę. Na interfejsie nasłuchującym w sieci, z którego normalnie powinniśmy otrzymać adres IP wpisujemy poniższe polecenie.
Rly-DHCPv6(config)#int gig0/1
Rly-DHCPv6(config-if)#ipv6 dhcp ?
client Act as an IPv6 DHCP client
server Act as an IPv6 DHCP server
Rly-DHCPv6(config-if)#ipv6 dhcp relay destination 2001:db8:acad:1::2 gig0/0
^
% Invalid input detected at '^' marker.
Rly-DHCPv6(config-if)#exit
W poleceniu relay destination
podajemy adres serwera. Dodatkowo, jeśli adresem serwera DHCP będzie
LLA, musimy podać wyjściowy interfejs taki jak na przykładzie
(gig0/0).
Laboratorium
Podsumowanie
W tym rozdziale dowiedzieliśmy się jak wyglądają metody dynamicznej adresacji hostów dla protokołu IPv6. Poznaliśmy w jaki sposób te metody działają oraz jakie komunikaty klient oraz serwer (w zależności od metody) ze sobą wymieniają aby finalnie skonfigurować adres IPv6 dla interfejsu. Na koniec poznaliśmy jakie w tym zakresie możliwości ma system Cisco IOS oraz jakim crapem są materiały, w których funkcjonuje jedno zagadnienie, a nie jest ono możliwe do zrealizowania w środowisku symulacyjnym jakim jest Packet Tracer. Nie prościej było to usunąć lub poprawić tego Packet Tracer-a. Czy to tak wiele dla tak dużej firmy?
2.9. Koncepcje FHRP
Po zakończeniu omawiania VLAN-ów, zaczeliśmy rozmiawiać o metodach pozwalających na istnienie łączy nadmiarowych bez ryzka powstawania pętli. Później stwierdziliśmy, że w przypadku kilku łączy nadmiarowych normalnie wykorzystywana jest tylko ich część, co nie za bardzo nam się niepodobało - chcielśmy wykorzystać je wszystkie lub przynajmniej większą część, zatem zaczeliśmy agregować te łącza. Mimo tak zbudowanej topologii, to gdzieś tam na jej górze znajduje się router brzegowy, który łączy naszą sieć z inną siecią, np. z Internetem. Zastanówmy się przez chwilę co w takiej topologii pozostaje słabym ogniwem? Takie rozwiązania, które nie mają zapewnionej nadmiarowości. W tym przypadku jest to nasz router, który umożliwia dostęp do zasobów zewnętrznych sieci.
Oczywiście możemy zapewnić dodatkowy router, podłączony do sieci usługodawcy, mnie mniej jednak, co w przypadku awarii podstawowego routera czy będziemy zmieniać na komputerach klientów adresy bramy lub wymuszać na nich ponowne skomunikowanie się z serwerem DHCP? Istnieją metody przełączania między routerami pozostające dla użytkowników końcowych niewidoczne. Tego rodzaju rozwiązania są zapewniane przez protokoły FHRP (First Hop Redundancy Protocol).
Działa to na na takiej zasadzie, że routery wymienią ze sobą komunikaty w zależności od rodzaju protokołu. FHRP to nazwa zbiorcza dla technologii, która zbiera pod sobą kilka różnych protokołów. Na podstawie wymienionych informacji między sobą decydują o tym, który z nich będzie urządzeniem przekazującym lub urządzeniem pasywnym, pozostającym w gotowości. Tutaj również dzieje się bardzo ciekawa rzecz, mianowicie: routery na swoich interfejsach nie mogą mieć więcej niż jeden adres. W przypadku skonfigurowania jednego z protokołów FHRP, interfejsy będą miały jeszcze jeden komplet z adresu MAC oraz IPv4 należące do wirtualnego routera i to ten adres IPv4 będą miały hosty zapisany jako adres bramy. Podczas pracy routery, przesyłają miedzy sobą komunikat, aby dać znać, że działają. Wysyłają go co określoną ilość czasu, jeśli przez jakiś określony czas router pasywny nie otrzyma tego pakietu, to uzna on, że obecne urządzenie aktywne uległo awarii i przejdzie w tryb aktywny. Do określenia ról routerów w tym protokole wykorzystuje się nazewnictwa - standby (w gotowości, pasywny) oraz active (aktywny, przekazujący). Natomiast między sobą routery wysyłają pakiety hello, służące do monitorowania stanu operacyjności.
Tak jak wspomniałem FHRP, to określenie zbiorcze technologii, które zbierają kilka protokołów pod sobą. Oto one:
- HSRP (Hot Standby Router Protocol) - Zastrzeżony przez Cisco protokół FHRP. Umożliwia on transparentny tryb failover dla urządzenia pierwszego skoku IPv4.
- HSRP IPv6 - HSRP dla IPv6
- VRRPv2 (Virtual Router Redundancy Protocol) - Otwarty protokół FHRP, działa na podobnej zasadzie do HSRP.
- VRRPv3 - Ulepszona wersja VRRPv2, poprawiono skalowalność.
- GLBP (Gateway Load Balancing Protocol) - Zastrzeżony przez Cisco protokół FHRP, zapewniający tą samą funkjonalność HSRP czy VRRP oraz rozszerzający ją o równoważenie obciążenia łączy.
- GLBP IPv6 - Wersja GLBP dla IPv6.
2.9.1 Protokół HSRP
Protokół HSRP jest zastrzeżoną przez Cisco implementacją transparentnego trybu failover zapewniający zawsze dostęp do routera dla hostów IPv4, po przez przełączanie się pomiedzy urządzeniem aktywnym, a standby-em. HSRP łączy routery w grupy i przełącza je w tych grupach, przyczym jeden router może należeć do wielu grup. Także nie ma tutaj obaw, podobnych do spanning tree, że nie wszystkie możliwości są w pełni wykorzystane.
W przypadku tego protokołu urządzenia dokonują elekcji na podstawie
priorytetu (w którym decyduje największa wartość -
120>100) lub jeśli priotety są takie same (domyślnie 100) to
decyduje najwyższy adres IP (.1.100>.1.1). Priorytet przyjmuje
wartość od 0 do 255, przyczym rolę routerów można wymusić
(polecenie standby preempt - użycie
tego polecenia ustawi go w roli aktywnego urządzenia).
W tym protokole
komunikaty hello przesyłane są co 3 sekundy, natomiast
standby czeka na nie przez 9 sekund, zanim rozpocznie
procedurę przełącznia. HSRP dokonuje przełączania na podstawie awarii
łącza lub na podstawie warunków, jednak one wykraczają poza ramy kursu
CCNA. HSRP wystawia wirtualny router (dodatkowy adres dla
interfejsu), który będzie bramą domyślną jednej z grup.
Podczas ustalania roli routera w HSRP interfejs (najczęściej bramy sieci LAN) będzie przechodzić przez następujące stany, za nim okaże się, że ma być przekazującym czy pasywnym w trybie stanby. Poniżej znajduje opis tych stanów oraz ich zachowanie względem komunikatów hello.
- Init - ten stan jest wprowadzany podczas zmiany konfiguracji lub podczas uruchamiania interfejsu.
- Learn - Router nie określił wirtualnego adresu IP, nie odebrał jeszcze komunikatów hello z aktywnego routera. W tym stanie router czeka na hello od aktywnego routera.
- Listen - Router zna wirtualny adres IP, ale nie jest jeszcze aktywnym ani pasywnym urządzeniem w grupie. Router nasłuchuje wiadomości hello od innych urządzeń w grupie.
- Speak - Router okresowo wysyła ramki hello, aktywnie bierze udział w elekcji urządzenia pasywnego/aktywnego.
- Standby - Router jest kandydatem, aby stać się urządzeniem aktywnym, okresowo wysyła komunikaty hello.
Ilości czasu między wysyłanymi wiadomościami hello oraz okres czasu oczekiwania na tego typu wiadomość można modyfikować. Jednak nie zaleca się ustawiania pierwszej wartości po niżej 2 sekund a drugiej poniżej 4. Spowoduje to znaczne zużycie zasobów urządzeń oraz nie potrzebne przełączanie się w przypadku drobnego, krótkotrwałego przeciążenia sieci.
2.9.3. Konfiguracja HSRP
Załóżmy że mamy taką topologię:
H-b -- S-2
| 192.168.1.0/24
|
R(d)-2 LAN2
--------------------
/ \ R-2 -N- R(d)-1: 172.16.0.0/16
N N R(d)-2 -N- R-3: 172.17.0.0/16
/ \
--------------------
R(d)-1 R-3 LAN1
\ /
\ /
S-1 192.168.20.0/24
/ \
/ \
H-a H-c
Legenda:
H - Host
S - Switch
R - Router
(d) - Serial DCE
-N- - Połączenie szeregowe
- - Połączenie Copper/Fiber
-[A-Za-z][0-9] - identyfikator urządzenia
Topologia przedstawia dwie sieci LAN połączone ze sobą łączami szeregowymi. Pierwsza sieć LAN, zawiera hosty: H-a, H-c, S-1, R-1 i R-3. Druga natomiast: H-b, S-2 i R-2. Host H-a w sieci LAN1 ma bramę ustawioną na adres interfejsu fa0/0 routera R-1, natomiast host H-c na adres interfejsu fa0/0 routera R-3, a host H-b na interfejs fa0/0 routera R-2. Między routerami skonfigurowano protokół routingu EIGRP, hosty mogą swobodnie komunikować się ze sobą.
Załóżmy, że dokonaliśmy odpowiednich pomiarów. Chcemy skonfigurować HSRP, aby ruch hosta H-c przechodził przez R-1, ale w przypadku jego awarii, został przełączony na R-3, natomiast ruch hosta H-a ma zostać wysłany przez R-3 i w przypadku awarii ma zostać przełączony na R-1. Aby to zrealizować potrzebne nam są dwie grupy HSRP. Konfigurację grup zaczynamy od ustalenia adresów IP dla wirtualnych routerów, następnie na routerze R-1 wydajemy poniższe polecenia.
R1(config)#int fa0/0 R1(config-if)#standby version 2 R1(config-if)#standby 1 ip 192.168.20.100 R1(config-if)#standby 1 priority 120 R1(config-if)#standby 1 preempt R1(config-if)#standby 2 ip 192.168.20.200 R1(config-if)#standby 2 priority 100
Po przejściu do interfejsu uruchamiamy nowszą wersję protokołu HSRP.
Następnie w trzecim poleceniu definujemy grupę 1 oraz adres IP dla
wirtualnego routera. W kolejnym poleceniach: ustawiamy wiekszy
priorytet niż domyślny (120) i
wywłaszczamy rolę active dla tego właśnie urządzenia w tej
grupie oczywiście. Ostatnie dwa polecenia służą definicji grupy drugiej
(wszystkie routery grupie powinny mieć te definicje) wraz z adresem
wirtualnego routera dla grupy drugiej. Na koniec podajemy priorytet
w sposób jawny, aby nie pozostawiać niczego domysłom. Na drugim
routerze w tej sieci, dokonujemy analogicznej konfiguracji ale dla
grupy drugiej jako natywna (R-3 będzie urządzeniem aktywnym w tej
grupie), natomiast grupe pierwszą wskazujemy jako definicję aby to
urządzenie również było jej członkiem.
R3(config)#int fa0/0 R3(config-if)#standby version 2 R3(config-if)#standby 2 ip 192.168.20.200 R3(config-if)#standby 2 priority 120 R3(config-if)#standby 2 preempt R3(config-if)#standby 1 ip 192.168.20.100 R3(config-if)#standby 1 priority 100
W ten sposób prezentują się informacje na temat użycia protokołów FHRP (HSRP) na routera Cisco:
R1#show standby brief
P indicates configured to preempt.
|
Interface Grp Pri P State Active Standby Virtual IP
Fa0/0 1 120 P Active local 192.168.20.3 192.168.20.100
Fa0/0 2 100 Standby 192.168.20.3 local 192.168.20.200
R3#show standby brief
P indicates configured to preempt.
|
Interface Grp Pri P State Active Standby Virtual IP
Fa0/0 2 120 P Active local 192.168.20.1 192.168.20.200
Fa0/0 1 100 Standby 192.168.20.1 local 192.168.20.100
Teraz po skonfigurowaniu HSRP, możemy ustawić hostom H-a oraz H-c odpowiednie adresy bramy domyślnej. Jeśli spróbujemy osiągnąć z H-c, host H-b to trasa będzie wyglądać następująco (interfejs fa0/0 R-1 ma adres IP: 192.168.20.1):
C:\>tracert 192.168.1.3 (host: H-b) Tracing route to 192.168.1.3 over a maximum of 30 hops: 1 0 ms 0 ms 0 ms 192.168.20.1 2 0 ms 1 ms 0 ms 172.16.0.2 3 0 ms 1 ms 1 ms 192.168.1.3 Trace complete.
Ale jeśli usunelibyśmy to połącznie między S-1 a R-1, to H-c nie miało by jak się skomunikować z R-1, na R-3 nie odebrało by wiadomości hello i przełączyłoby się w tryb aktywny. Wówczas ta sama trasa wyglądała by jak na poniższym przykładzie (interfejs fa0/0 R-3 ma adres: 192.168.20.3):
C:\>tracert 192.168.1.3 (host: H-b) Tracing route to 192.168.1.3 over a maximum of 30 hops: 1 1 ms 0 ms 0 ms 192.168.20.3 2 0 ms 15 ms 0 ms 172.17.0.2 3 10 ms 1 ms 0 ms 192.168.1.3 Trace complete.
Jeśli mielibyśmy w tej sieć mieć tylko jedną grupę HSRP, to wówczas ograniczylibyśmy się do dwóch poleceń na urządzeniu standby:
R3(config)#int fa0/0 R3(config-if)#standby version 2 R3(config-if)#standby 1 ip 192.168.20.100
Zadanie praktyczne - Packet Tracer
Przewodnik konfiguracji HSRP - scenariusz
Przewodnik konfiguracji HSRP - zadanie
Podsumowanie
W tym rozdziale zapoznaliśmy z technologią FHRP, poznaliśmy metody działania jej protokołów oraz ich rodzaje. Omówiliśmy sobie protokół Cisco HSRP oraz skonfigurowaliśmy przykładową sieć, aby przedstawić w jaki sposób można wykorzystać w pełni jej potencjał przy użyciu protokołów tego rodzaju.
2.10. Koncepcje bezpieczeństwa
Konfigurując sieć prędzej czy później będziemy musieli zająć tematem bezpieczeństwa. Obecnie najbardziej prawdopodobnymi ataki z jakimi będziemy musieli się zmierzyć będą to:
- Ataki odmowy usługi (DoS/DDoS) - w tym przypadku atakujący wykorzystuje serwer i działające na nim usługi. Przy użyciu ogromnej liczby żądań usługi przeciąża ją, wówczas dla osób, które faktycznie chcą z niej skorzystać, staje się ona niedostępna.
- Naruszenie danych - tutaj najczęściej padają ofiarą hosty użytkowników końcowych oraz serwery. Dane z tych komputerów mogą zostać skradzione.
- Malware - złośliwe opgrogramowanie dokonujące lub pozwalające na inne rodzaje ataków.
Ataki najczęsciej, choć nie jest to reguła, będą pochodzić z zewnątrz. Dlatego też musimy wykorzystać dobrej jakości rozwiązania, takie jak:
- Router z VPN - implementacja tuneli VPN w sieciach pozwalających na zdalny dostęp do zasobów to podstawa bezpieczenej transmisji danych między firmą a pracownikami zdalnymi. Taki router przeważnie znajduje się na brzegu sieci.
- NGFW - zapora sieciowa nowej generacji. Tak jak tradycyjne urządzenia filtrują ruch na podstawie informacji warstwy 3 oraz 4. W przypadku urządzeń nowej generacji filtrowanie nieporządanych wiadomości, może odbywać się na poziomie komunikatów warstwy aplikacji.
- NAC - urządzenia opowiadające za uwierzytelnianie, autoryzacje oraz ewidencjonowanie.
Na ataki najczęciej podatne są punkty końcowe. Są one zazwyczaj chronione prze AMP - zaawansowaną ochronę antywirusową. Są to programy spełniające rolę platformy bezpieczeństwa zawierającą pakiet programu antywirusowego, zaporę sieciową zapobieganie włamaniom i wiele innych. Projektując system bezpieczeństwa sieci, musimy wdrożyć takie rozwiązania, które spowodują, że to wyżej wymionione oprogramowanie będzie miało jak najmniej do pracy. W sieci możemy wdrożyć takie rozwiązania jak ESA - system bezpieczeństwa poczty (filtr spamu, skaner załączników) lub/i WSA - system bezpieczeństwa sieci Web (filtr treści).
2.10.1. Kontrola dostępu
W przypadku urządzeń koncowych, kontrolę dostępu zapewniają nam hasła. Podobnie może być w przypadku sieci. Wymagane jest wówczas wdrożenie mechanizmów AAA (w nomenklaturze Cisco). Ten skrót sprowadza się do trzech czynności: autentykacji, autoryzacji oraz ewidencjonowania. Autentykacja jest sposobem pozwalającym na stwierdzenie czy jesteśmy tymi, za których się podajemy. Autoryzacja, natomiast określa nam co możemy zrobić w systemie - określa ona nasze uprawnienia. Ostatnim czynnikiem jest zapewnienie ewidencjonowania tj. zbierania oraz raportowania tego co użytkownik robi w sieci czy na urządzeniu. Rozwiązania tego typu mogą dostarczyć informacji potrzebnych do audytu, czy pomóc przy rozliczeniu. Wprowadzenie tego typu zabezpieczeń spowoduje, że podczas podłączania do sieci wymagane będzie podanie loginu hasła.
Innym rodzajem kontroli dostępu do sieci może być standard IEEE 802.1X, jest to oparty na portach protokół, który pozwala na uwierzytelnianie oraz autoryzacje użytkownika w sieci. Decydując się na tego typu rozwiązanie do dyspozycji będziemy mieć dwie implementacje, takie jak otwarty RADIUS oraz zastrzeżony przez Cisco TACACS+. W przypadku 802.1X każdy komputer ma swoją rolę:
- Klient (suplikant) - są to urządzenia z zainstalowanym oprogramowaniem klienckim zgodnym z 802.1X. Oprogramowanie tego typu może być stosowane zarówno dla hostów przewodowych jak i bezprzewodowych.
- Przełącznik (wystawca uwierzytelnienia) - jest swojego rodzaju pośrednik, żądający od klienta danych uwierzytelniających i weryfikujący je z serwerem uwierzytelnienia. Po weryfikacji wysyła on odpowiedź do klienta. Innym urządzeniem, które może działać jako wystawca uwierzytelnienia jest punkt dostępowy.
- Serwer uwierzytelniania - oprogramownie sprawdzające tożsamość klienta, powiadamia ono przełącznik lub punkt dostępowy czy klient może uzyskać dostęp do sieci.
2.10.3. Zagrożenia warstwy 2
Warstwa druga jest poziomem gdzie sygnały elektryczne zaczynają spotykać się z jakąś logiką. Na tym poziomie możemy już określać pewne obawy co do bezpieczeństwa transmisji jak i samego połączenia. Istnieje kilka ataków, które mogą zaistnieć w naszej sieci. Działania te głównie skupiają się wokół przełącznika, a urządzenia Cisco posiadają odpowiednie środki zapobiegawcze mogące spowodować, że będą one niewrażliwego na te zagrożenia.
- Ataki na tablice MAC - Obejmują ataki polegające na zalewaniu adresami MAC. Środek zapobiegawczy: zabezpieczenia portu.
- Ataki na sieci VLAN - Obejmują ataki z przeskokiem i podwójnym znakowaniem VLAN. Obejmują one również ataki między urządzeniami we wspolnej sieci VLAN. Środek zapobiegawczy: wyłączenie protokołu DTP, zmiana natywnej sieci VLAN
- Ataki na DHCP - Obejmują ataki polegające na blokowaniu i fałszowaniu DHCP. Środek zapobiegawczy: DHCP Snooping.
- Ataki na ARP - Obejmują spoofing ARP oraz ataki zatucia ARP. Środek zapobiegawczy: dynamiczna inspekcja ARP (DAI).
- Ataki z podszywaniem się. - Obejmują ataki polegające na sfałszowaniu adresów MAC i IP. Środek zapobiegawczy: IP Source Guard (IPSG).
- Ataki na STP - Obejmują ataki manipulacji protokołem Spanning Tree. Środek zapobiegawczy: włączenie funkcji PortFast oraz BPDU Guard..
Oczywiście nasze starania mogą nie być wystarczające szczególnie wtedy gdy protokoły nie będą wystarczająco zabezpieczone. Zaleca się porzucenie protokołów nie posiadających żadnych sensownych zabezpieczeń, na rzecz bezpieczniejszych wersji, korzystających z warstwy TLS czy wykorzystanie protokołów pochodnych od SSH. Innym czynnikiem może być wydzielenie odrębnej sieci VLAN dla zarządzania urządzeniami.
2.10.4. Ataki na sieć LAN
Pierwszym bardzo prostym atakiem do przeprowadzenia jest atak na tablicę MAC przełącznika. Polega on na zalewaniu przełącznika ramkami ze źródłowym losowym adresem MAC, przez co tablica MAC będzie cały czas się wypełniać. W momencie jej przepełnienia przełącznik zaczyna się zachowywać jak koncentrator. Takie działanie pozwoli atakującemu przechwycić ruch sieciowy, który nie jest zaadresowany do niego.
Metodami zapobiegawczymi takiego działania jest skonfigurowanie zabezpieczeń portów (zajmiemy się tym w następnym rozdziale), pozwoli to ogranicznie nauki adresów na tych portach do podanej konkretnej wartości. Choćby jednego adresu.
Podatność na ataki względem VLAN-ów jest niedopatrzeniem z strony administratora. Pozostawienie włączonego protokołu DTP, może pozwolić intruzowi na wymuszenie pomiędzy jego urządzeniami, a przełącznikiem portu trunk. Jeśli administrator zapomiał o wyłączeniu DTP to na łączach magistralnych dopuszcza ruch za pewne dla całego zakresu sieci VLAN. Zatem nic nie stoi na przeszkodzie, aby atakujący mógł skomunikować z dowolnym hostem w sieci, mimo skonfigurowania sieci VLAN. Tego typu nazywany jest atak z przeskokiem VLAN.
Innym atakiem na sieci VLAN, jest atak podwójnego tagowania, atakujący znając identyfikator natywnego VLAN-u, może wysłać dane do dowolnym hostem w dowolnym VLAN-ie, powodując np. atak odmowy usługi. Jego zadaniem będzie przygotowanie ramki zawierającej pole 802.1Q z identyfikatorem natywnego VLAN-u, jak i drugie pole 802.1Q zawierające identyfikator docelowej sieci VLAN. Domyślnie natywną siecią VLAN, jest VLAN 1. Natomiast id konkretnej sieci VLAN, jest zapisany w adresie IP hosta. W momencie osiągniecia pierwszego przełącznika, pierwszy znacznik zostaje zdjęty (przez VLAN natywny, przysyłany jest ruch nietagowany), natomiast drugi przełącznik zauważy tag i przekaże te ramki do odpowiedniej sieci VLAN.
Ochrona przed tego typu czynnościami, wymaga od nas wykonania czynności, które wykonywaliśmy przy okazji konfiguracji łączy trunk oraz protokołu DTP. Należy ten protokoł bezwzględnie wyłączyć, na łączach magistralnych oraz zmienić natywny VLAN z 1 na jakiś inny losowy. Warto również na sztywno przypisać portom działanie w trybie dostępu.
Kolejne ataki, które są omawiane to ataki przeciwko DHCP. Pierwszym z nich jest atak zagłodzenia - swojego rodzaju atak typu DoS (pojedynczy atak DDoS), ponieważ uniemożliwia on prawowitym hostom uzyskanie adresu IP z serwera DHCP. Atakujący wyczerpuje całą pulę po przez wielkrotną komunikację z serwerem DHCP, przy użyciu komunikatów o losowych adresach źródłowych. Cała pula zostaje wyczerpana przez losowe adresy, które nawet nie wyślą jednej ramki.
Innym atakiem jest atak sfaszowanego DHCP. Intruz może na swoim komputerze uruchomić serwer DHCP i skonfigurować go taki sposób, aby nasz ruch był odpowiednio kierowany. Takiego rodzaju działanie ma za zadanie przechwycić nasz ruch. Atakujący może udostępnić nam, przez swój komputer połącznie z inną siecią, taką jak Internet, przez co może do woli przeglądać nasz nieszyfrowany ruch.
Metodą zapobiegawczą dla tego rodzaju zagrożenia, jest uruchomienie na portach mechnizmu DHCP Snooping, pozwala on na wybranie portu z którego mogą przychodzić odpowiedzi z serwera DHCP oraz nałożenie limitów na ilość zapytań - komunikatów DHCPDISCOVER. Ciekawym faktem jest to, że uruchomienie tej funkcjonalności pozwala nam zamienić przełącznik, działający w warstwie 2 w nieco bardziej inteligente urządzenie, które musi spojrzeć aż do pola danych w przesyłanych ramkach.
Ataki ARP takie jak zatrucie czy fałszowanie są do siebie bardzo zbliżone w metodach do ich przeprowadzania. Można by nawet rzec, że identyczne. Protokołu ARP używa się w celu uzyskania adresu MAC na podstawie adresu IP. Zadaniem atakującego jest wysyłanie fałszywych odpowiedzi na zapytanie ARP, przez co najczęściej host straci połączenie z innymi w sieci. Przy czym tutaj warto powiedzieć, że te wysyłanie odpowiedzi musi być ciągłe. Inaczej po zaprzestaniu wysyłania tych odpowiedzi, komunikacja po kilku minutach wróci do normy. Tego typu działanie jest właśnie, zatruciem ARP. Fałszowanie ma na celu najczęściej zmianę trasy ruchu sieciowego, więc tutaj używa się komunikatu gratisowego ARP, który jest częścią standardu ARP. Jego wykorzystanie różni się tym, że przy normalnej komunikacji host ofiary nie zapyta o adres jeśli ma go w swojej tablicy ARP, ale w przypadku pakietu gratisowego, host ofiary musi aktualizować wpis, którego on dotyczy.
Przed atakami na ARP, jest się ciężko obronić. Ponieważ te funkcję, które uważamy za słabe, są jego częścia. Nie mniej jednak Cisco posiada metodę zwaną DAI - Dynamiczną inspekcją ARP. DAI do swojego działania wymaga DHCP Snoopingu. Podobnie tak jak w przypadku DHCP wybieramy zaufany, który nie będzie sprawdzany. Następnie możemy ustawić inspekcję ARP dla konkretnego VLAN lub całego przełącznika, możemy wybrać dodatkowo sprawdzany kryterium czy sprawdzany ma być adres MAC źródłowy czy docelowy.
Atak fałszowania adresów, może pozwolić atakującemu na przejście przez zaporę sieciową. Atak ten polega na wygenrowaniu zarówno ramek i jak i pakietów IP ze sfałszowanymi adresami. Dodatkowo pamiętając jak działają przełączniki, to możebyć wielce prawdopodbne, otrzymamy odpowiedź na sfałszowany adres, gdyż przełącznik zapisze w tablicy MAC, że ten komputer jest podłączony do takiego portu.
Przed spoofingiem może ochronić nas mechanizm IPSG - IP Source Guard.
Ostatnim omawianym atakiem jest atak na STP. Intruz może chcieć manipulować protokołem w celu wymuszenia zmiany mostu głównego, aby moc przechwytywać ruch z sieci. Dokonuje on tego po przez wysłanie komunikatu BPDU, zawierającego BID o bardzo wysokim piorytecie. Wówczas trasy zostaną ponownie przeliczone, a atakujący uzyska dostęp do naszej transmisji.
Sposobem na zapobiegnięcie takiemu obiegowi sprawy, należy na na portach dostępowych uruchomić mechanizmy takie jak PortFast czy BPDU Guard. Reagują one na pojawieni się na porcie komunikatu BPDU. Najczęściej port jest blokowany w stan err-disabled, po tym jak kolwiek komunikacja zostanie zaprzestana z hostem podłączonym do niego.
Innym zagrozniem nie wyrządzającym szkody bezpośrednio hostom jest rozpoznanie CDP. CDP to własnościowy protokół Cisco wykorzystywany do konfiguracji urządzeń tego producenta. Urządzenia mają domyślnie włączony ten protokołu i wymieniają miedzy sobą informacje za jego pomocą. CDP jest pomocnym protokołem jednak przesyła zbyt wiele informacji w sposób niebezpieczny. Jedną z nich jest jest natywna sieć VLAN. Dlatego zaleca się wyłącznie jego oraz jego otwartego odpowiednika - LLDP (Link-Layer Discovery Protocol).
Podsumowanie
W tym rozdziale zapoznaliśmy się koncepcjami bezpieczeństwa warstwy drugiej. Dowiedzieliśmy się jak są rodzaje ataków i środki zaradcze. Na koniec szerzej omówiliśmy każdy z rodzajów ataków, aby mieć ich obraz podczas konfiguracji.
2.11. Konfiguracja zabezpieczeń przełącznika
W poprzednim rodziale omówiliśmy zagrożenia z jakimi możemy się spotkać w warstwie drugiej. W tym rodziale dowiemy się w jaki sposób skonfigurować system IOS na przełączniku, aby móc się przed nimi chronić.
2.11.1. Zabezpieczenia portów
Pierwszą i w prawdzie najważniejszą rzeczą są zabezpieczenia portów. Za pomocą tego mechanizmu możemy nakazać aby konkrety port mógł nauczyć się tylko jednego adresu MAC, który jeśi będziemy sobie tego życzyć będzie może trafić do konfiguracji. Zabezpieczenia portów są podstawą linią obrony przed atakami warstwy drugiej.
Omawianie zabezpieczeń portów, rozpoczniemy od najprostszej czynności
jaką możemy wykonać. Jeśli intruz będzie w zasiegu dostępnego gniazda
Ethernet, może sprawdzić czy jest ono aktywne. Jeśli tak, to
może
udać mu się uzyskać dostęp do sieci. Dlatego czasami najprostrze
rowiązania są najlepsze. Zatem może warto
wyłączyć nieużywane porty administracyjnie. Wydając
proste polecenie shutdown. Domyślnie
wszystkie porty przełącznika nie są wyłączone
administracyjnie.
S1(config)#do sh ip int br Interface IP-Address OK? Method Status Protocol Vlan1 unassigned YES unset administratively down down FastEthernet0/1 unassigned YES unset down down FastEthernet0/2 unassigned YES unset down down FastEthernet0/3 unassigned YES unset down down FastEthernet0/4 unassigned YES unset down down FastEthernet0/5 unassigned YES unset down down ...
Przejść do konfiguracji wiecej niż jednego portu możemy poprzez
użycie polecenia int range podając
zakres portów lub też ich listę jeśli porty są nie po kolei. Oczywiście
możemy mieszać ze sobą ten rodzaj parametrów.
S1(config)#int range fa0/1-24 S1(config-if-range)#shutdown S1(config-if-range)#do sh ip int br Interface IP-Address OK? Method Status Protocol Vlan1 unassigned YES unset administratively down down FastEthernet0/1 unassigned YES unset administratively down down FastEthernet0/2 unassigned YES unset administratively down down FastEthernet0/3 unassigned YES unset administratively down down FastEthernet0/4 unassigned YES unset administratively down down FastEthernet0/5 unassigned YES unset administratively down down FastEthernet0/6 unassigned YES unset administratively down down ...
Po wyłączeniu portów, nie ma możliwości aby ktoś bez naszej wiedzy mógł się podłączyć do sieci. Administracyjne wyłącznie portów fizycznie wyłącza zasilanie na portach przełącznika.
Poza dostępem do sieci, możemy również chcieć zabezpieczyć nasz przełącznik, aby nigdy nie udało się zrobić z koncentratora. Z poprzedniego rodziału wiemy jak tego dokonać. Zabezpieczenia portów obejmują możliwość wskazania ilość adresów MAC, których przełącznik może się nauczyć, w jaki sposób ma się ich uczyć, kiedy i jaki sposób adres w tablicy ulega przedawnieniu czy co zrobić w przypadku naruszenia zasad zabezpieczeń portów.
Samo włączenie zabezpieczeń portu spowoduje, że zostaną nałożone na niego pewne zasady. Za nim jednak przejdziemy do uruchomienia tej opcji to musimy sobie wyjaśnić pewną rzecz. Domyślnie włączony jest protokoł DTP, natomiast porty znajdują się w domyślnym stanie dynamic auto. Zabezpieczenia portu wymagają, aby port był portem dostępowym, więc przed uruchomienieniem zabezpieczeńm portów musimy przełączyć port w tryb dostępu:
#Domyślnie: S1(config)#do show int fa0/1 switchport Name: Fa0/1 Switchport: Enabled Administrative Mode: dynamic auto Operational Mode: down Administrative Trunking Encapsulation: dot1q Negotiation of Trunking: On Access Mode VLAN: 1 (default) Trunking Native Mode VLAN: 1 (default) Administrative Native VLAN tagging: enabled S1(config)#int fa0/1 S1(config-if)#switchport mode access S1(config-if)#do show interface fa0/1 switchport Name: Fa0/1 Switchport: Enabled Administrative Mode: static access Operational Mode: down Administrative Trunking Encapsulation: dot1q Negotiation of Trunking: Off Access Mode VLAN: 1 (default) Trunking Native Mode VLAN: 1 (default) Administrative Native VLAN tagging: enabled Voice VLAN: none
Teraz możemy włączyć zabezpieczenia portu.
S1(config-if)#switchport port-security
Reguły narzucone przez uruchomienie zabezpieczeń portu to, ustawienie trybu naruszenia na najbardziej restrykcyjny oraz ustawienie ilości adresów MAC do nauczenia się dla tego portu na 1.
S1#show port-security interface fa0/1 Port Security : Enabled Port Status : Secure-down Violation Mode : Shutdown Aging Time : 0 mins Aging Type : Absolute SecureStatic Address Aging : Disabled Maximum MAC Addresses : 1 Total MAC Addresses : 0 Configured MAC Addresses : 0 Sticky MAC Addresses : 0 Last Source Address:Vlan : 0000.0000.0000:0 Security Violation Count : 0
Tryb naruszenia Violation Mode,
został ustawiony na Shutdown, co
spowoduje, że jeśli ktoś inny podłączy się do tego portu, to zostanie
on ustawiony w tryb error disabled. Liczba możliwych adresów
do nauczenia (Maximum MAC Address)
wynosi 1.
Jeśli chcemy zdecydować o tym ilu adresów pownieni móc nauczyć się port wówczas wyskorzysujemy następujące polecenie:
Switch(config-if)# switchport port-security maximum <1-8129>
Po za podaniem ilości dozwolonych adresów MAC do zapamiętania, możemy manipulować samym jego procesem. Np. podać statyczny adres MAC lub przełącznik będzie się ich uczył dynamicznie. Co jest domyślną metodą przy włączeniu zabezpieczeń portów. Inna wariacją jest dynamiczne uczenie się z wykorzystaniem NVRAM do zapamiętania adresów MAC. Poniższe polecenia uruchamiają poniższe tryby:
- Przypisanie statyczne -
S1(config-if)#switchport port-security mac-address 00de.adbe.ef00 - Uczenie się dynamiczne -
S1(config-if)#switchport port-security - Uczenie się dynamiczne z wykorzystaniem NVRAM
S1(config-if)#switchport port-security mac-address sticky
W przypadku tych trybów to można je mieszać, ustawiając ilość adresów na 4 i podając np. 2 adresy statycznie a resztę pozostawić do nauki dynamicznej z wykorzystaniem NVRAM. W przpadku uczenia się adresów MAC, przydatne może być polecenie:
S1#show port-security address
Secure Mac Address Table
------------------------------------------------------------------------
Vlan Mac Address Type Ports Remaining Age
(mins)
---- ----------- ---- ----- -------------
1 001f.1618.0d37 SecureSticky Fa0/2 -
1 00de.adbe.ef00 SecureConfigured Fa0/2 -
------------------------------------------------------------------------
Total Addresses in System (excluding one mac per port) : 1
Max Addresses limit in System (excluding one mac per port) : 8192
Statystyki dla tego portu przezentują się następująco:
S1#sh port-sec int fa0/2 Port Security : Enabled Port Status : Secure-up Violation Mode : Shutdown Aging Time : 0 mins Aging Type : Absolute SecureStatic Address Aging : Disabled Maximum MAC Addresses : 2 Total MAC Addresses : 2 Configured MAC Addresses : 1 Sticky MAC Addresses : 1 Last Source Address:Vlan : 001f.1618.0d37:1 Security Violation Count : 0
Port jest podniesiony (Port Status: Secure-up)
i nie nastąpiło żadne naruszenie zasad
(Security Violation Count: 0).
Zabezpieczenia portów pozwalają na określenie okresu ważności dla bezpiecznych adresów (Przypisanych statycznie lub nauczonych w ramach dynamicznej nauki, zgodnie z określonym limitem). Mamy dwa rodzaje przedawnienia (okresu ważności):
- Absolute (ang. bezwględy) - adresy MAC są usuwane po upłynięciu podanego okresu czasu.
- Inactivity (ang. nieaktywność) - adresy MAC są usuwane po upłynięciu podanego okresu czasu nieaktywności.
Za ustawianie przedawnienia odpowiedzialne jest polecenie aging zabezpieczania portów. Może ono przyjąć następujące opcje:
- static - włącza okres przedawnienia dla statycznie przypisanych adresów MAC.
- time <czas> - Czas w minutach określający przedawnienie. Przyjmuje wartości od 0 do 1440. Przy czym ustawienie 0, wyłącza przedawnienie dla tego portu.
- type Absolute/Inactivity - określa rodzaj przedawnienia dla portu.
Dla przykładu ustawiłem na porcie 2 czas przedawnienia 10 minut nieaktywności interfejsu.
S1(config)#int fa0/2 S1(config-if)#switchport port-security aging time 10 S1(config-if)#switchport port-security aging type inactivity
W momencie gdy dojdzie do przekroczenia zasad skonfigurownych na porcie występuje naruszenie, może mieć one różne skutki. Od zaprzestania transmisji dla nieznanych adresów na czas potrzebny do usunięcia nadmiarowych adresów MAC do przestawienia portu w stan error-disabled. Istnieją trzy tryby:
- shutdown (domyślny) - Port przechodzi natychmiast do stanu error-disabled, wyłącza kontrolkę LED i wysła komunikat do Syslog. Licznik naruszeń jest zwiększany
- restrict - Ten tryb powoduje zaprzestanie transmisji dla nieznaych adresów do momentu usunięcia namiarowych pozycji. Porty nie są wyłączane. Licznik naruszeń jest zwiększany oraz wysłane są komunikaty syslog
- protect - działa na takiej samej zasadzie jak restrict, przyczym żadne logi nie są wysłane oraz nie jest zwiększany licznik naruszeń. Jest najmniej bezpieczny z trybów.
Do ustawienie trybu wybierany wykorzystywane jest polecenie violation, zabezpieczeń portów.
S1(config)#int fa0/2 S1(config-if)#switchport port-security violation restrict
Stan error-disabled - wyłączony przez błąd, może być spowodowany przez użytkownika, w momencie gdy naruszy on zasady zabezpieczeń portów. Transmisja przez taki port zostaje zatrzymana, wyłączona jest również kontrolka LED. Włączenie takowego portu wymaga działania administratora.
Do tej porty poznaliśmy polecenia, które pozwolą nam ustawienie zabezpieczeń portów oraz na wyświetlenie informacji o nich. Nie których. Bowiem istnieje jeszcze jedno polecenie, które pozwoli na wyświetlenie zabezpieczeń na wszystkich portach.
S1#show port-security
Secure Port MaxSecureAddr CurrentAddr SecurityViolation Security Action
(Count) (Count) (Count)
---------------------------------------------------------------------------
Fa0/1 1 0 0 Shutdown
Fa0/2 2 2 0 Restrict
---------------------------------------------------------------------------
Total Addresses in System (excluding one mac per port) : 1
Max Addresses limit in System (excluding one mac per port) : 8192
Zadanie praktyczne - Packet Tracer
Wdrożenie zabezpieczeń portów - scenariusz
Wdrożenie zabezpieczeń portów - zadanie
2.11.2. Ograniczanie ataków na sieci VLAN
Ataki na sieci VLAN omawiane były dwa: atak z przeskokiem, gdzie atakującemu udawało się wynegocjować łącze trunk i uzyskać dostęp do innych VLAN-ów, niż ten do którego należy jego gniazdo. Drugim atakiem był atak podwójnego znakowania, gdzie atakujący tworzył ramkę z podwójnym znacznikiem, pierwszy zawierał znacznik natywnej sieci VLAN, a drugi sieci docelowej.
Metodą zabezpieczenia się przed tego typu działaniami są kolejno:
- Wyłączenie negocjacji DTP na innych portach niż trunk,
przy użyciu polecenia
switchport mode access - Nie używane porty należy umieść w innym VLAN-ie niż domyślny.
- Na portach przeznaczonych jako trunk, tryb ten włączamy
jest ręcznie przy użyciu polecenia
switchport mode trunk. - Wyłączamy autonegocjacje DTP na portach trunk, za pomocą
polecenia:
switchport nonegotiate. - Zmieniamy natwyną sieć VLAN dla łączy trunk, przy użyciu
polecenia:
switchport trunk native vlan X, gdzieX, oznacza numer sieci VLAN.
S1(config)#vlan 1000 S1(config-vlan)#name UNUSED_PORTS S1(config-vlan)#vlan 999 S1(config-vlan)#name NATIVE S1(config-vlan)#exit S1(config)# S1(config)#int range fa0/3-12 S1(config-if-range)#switchport mode acces S1(config-if-range)#exit S1(config)#int range fa0/13-20 S1(config-if-range)#switchport mode access S1(config-if-range)#switchport access vlan 1000 S1(config-if-range)#shutdown S1(config-if-range)#exit S1(config)#int fa0/21-24 S1(config-if-range)#switchport mode trunk S1(config-if-range)#switchport nonegotiate S1(config-if-range)#switchport trunk native vlan 999 S1(config-if-range)#end
Na powyższym przykładzie skonfigurowano wyżej wymienione zabezpieczenia. Porty 3-12 są portami dostępowymi. Porty 13-20 nie są obecnie używane. Ostatnie 4 porty są łączami trunk.
2.11.3. Ograniczanie ataków na DHCP
Znamy dwa ataki wobec usługi DHCP, pierwsza z znich jest zagłodzenie - tj. wyczerpanie puli przez atakującego. Ochroną przed tego typu działaniem jest ustawienie limitu zapytań do DHCP na portach niezaufanych (innych niż te, z których będzie przychodzić odpowiedź od serwera). Drugim atakiem, jest fałszowanie - atakujący podstawia swój serwer DHCP. Metodą ochrony przed takim działaniem jest ustawienie portu zaufanego - z którego będą przychodzić komunikaty serwera DHCP. Reszta portów będzie domyślnie ustawiana jako niezaufane. Te metody oferuje mechanizm DHCP Snooping. Kroki jakie należy wykonać w celu skonfigurowania tej metody prezentują się następująco:
- Włączamy DHCP Snooping za pomocą polecenia
ip dhcp snoopingw konfiguracji globalnej - Porty z odpowiedzią DHCP uznajemy za zaufane za pomocą polecenia:
ip dhcp snooping trust. - Na portach niezaufanych ustawiamy limit zapytań do DHCP - liczbę
odebranych komunikatów DHCPDISCOVER na sekundę. Dokonujemy tego
za pomocą polecenia:
ip dhcp snooping limit rate X, gdzieXto liczba zapytań. - DHCP Snooping możemy również włączyć dla określonej sieci
VLAN lub dla wielu sieci, wydając w konfiguracji globalnej polecenie:
ip dhcp snooping Y, gdzieYto numer/numery sieci VLAN lub ich zakres.
S1#conf t S1(config)#ip dhcp snooping S1(config)#int g0/1 S1(config-if)#ip dhcp snooping trust S1(config-if)#exit S1(config)#int range fa0/1-24 S1(config-if-range)#ip dhcp snooping limit rate 6 S1(config-if-range)#exit S1(config)#ip dhcp snooping vlan 1000
Na powyższym przykładzie skonfigurowano opcje zabepieczeń przed atakami
na DHCP. W IOS mamy możliwość wyświetlenia informacji o konfiguracji
DHCP Snooping za pomocą polecenia:
show ip dhcp snooping.
S1#show ip dhcp snooping Switch DHCP snooping is enabled DHCP snooping is configured on following VLANs: 1000 DHCP snooping is operational on following VLANs: 1000 DHCP snooping is configured on the following L3 Interfaces: Insertion of option 82 is enabled circuit-id default format: vlan-mod-port remote-id: ecc8.8212.b200 (MAC) Option 82 on untrusted port is not allowed Verification of hwaddr field is enabled Verification of giaddr field is enabled DHCP snooping trust/rate is configured on the following Interfaces: Interface Trusted Allow option Rate limit (pps) ----------------------- ------- ------------ ---------------- FastEthernet0/1 no no 6 Custom circuit-ids: FastEthernet0/2 no no 6 Custom circuit-ids: FastEthernet0/3 no no 6 Custom circuit-ids: FastEthernet0/4 no no 6 Custom circuit-ids: FastEthernet0/5 no no 6 Custom circuit-ids: ... FastEthernet0/23 no no 6 Interface Trusted Allow option Rate limit (pps) ----------------------- ------- ------------ ---------------- Custom circuit-ids: FastEthernet0/24 no no 6 Custom circuit-ids: GigabitEthernet0/1 yes yes unlimited Custom circuit-ids:
2.11.4. Ograniczenie ataków na ARP.
Ataki ARP są do siebie bardzo podobne. Chodzi o manipulację tablicą ARP na komputerze ofiary. Pierwszym atakiem jest zatrucie, przez które ofiara całkowicie traci łączność, ponieważ atakujący odpowiada na jej żądania losowowymi adresami fizycznymi. Drugim atakiem jest fałszowanie ataków, przy użyciu pakietu gratisowego ARP. Użycie tego pakietu wymusza na ofierze, aktualizację wpisu w tablicy ARP, którego dotyczy ten pakiet. Chronić się przed działania tego typu możemy za pomocą mechanizmu Dynamic Arp Inspection - DAI.
Dynamiczna inspekcja ARP (DAI) wymaga działania mechanizmu DHCP Snooping, pomaga zapobiegać atakom poprzez:
- Nie przykazywanie nieprawidłowych lub gratisowych odpowiedzi ARP do innych portów w tej samej sieci VLAN.
- Przechwytywanie wszystkich żądań i odpowiedzi ARP na niezaufanych portach.
- Sprawdzenie każdego przechwyconego pakietu pod kątem prawidłowego powiązania IP do MAC.
- Odrzucanie i rejestrowanie odpowiedzi ARP, posiadające nieprawdziwe informacje, aby zapobiec zatruciu ARP.
- Przełączenie interfejsu w stan error-disabled, jeśli skonfigurowana w DAI liczba pakietów ARP zostanie przekroczona.
W celu wykorzystania mechnizmu DAI, musimy podąrząć zgodnie z poniższymi wskazówkami:
- Włączamy globalnie DHCP Snooping.
- Włączamy DHCP Snooping dla konkretnej sieci VLAN.
- Włączamy DAI dla wybranej sieci VLAN.
- Na koniec konfigurujemy zaufane interfejsy dla DHCP Snooping i DAI.
S1#conf t Enter configuration commands, one per line. End with CNTL/Z. S1(config)#ip dhcp snooping S1(config)#ip dhcp snooping vlan 1000 S1(config)#ip arp inspection vlan 1000 S1(config)#interface fa0/24 S1(config-if)#ip dhcp snooping trust S1(config-if)#ip arp inspection trust
Na powyższym urządzeniu włączyłem globalnie DHCP Snooping,
S1(config)#ip dhcp snooping następnie
skonfigurowałem DHCP Snooping oraz DAI dla VLAN-u 1000 -
S1(config)#ip dhcp snooping vlan 1000,
S1(config)#ip arp inspection vlan 1000.
Na koniec skonfigurowałem interfejs fa0/24
jako zaufany dla DHCP Snooping-u oraz inspekcji ARP.
Mechanizm DAI może zostać również skonfigurowany w taki sposób aby weryfikował adresy przekazywane we wiadomości ARP z adresami zawartymi w nagłówku ramki Ethernet. Do wyboru mamy takie warunki jak:
- Docelowy MAC - porównanie docelowego adresu MAC w nagłówku ramki z tym we wiadomości ARP.
- Źródłowy MAC - porównianie źródłowego adresu MAC w nagłówku ramki z tym we wiadomości ARP.
- Adres IP - sprawdza komunikat pod kątem nie prawidłowych i nieoczekiwanych adresów IP, takich jak: 0.0.0.0, 255.255.255.255 czy wszystkich adresów multicastowych.
Do ustawiania weryfikacji adresów w ARP służy polecenie:
ip arp inspection validate po czym
podajemy rodzaj sprawdzania adresów. Nic nie stoi na przeszkodzie, aby
ustawić je wszystkie.
S1#conf t Enter configuration commands, one per line. End with CNTL/Z. S1(config)#ip arp inspection validate src-mac dst-mac ip
Od teraz komunikaty ARP, bedą sprawdzane pod kątem poprawności adresów.
2.11.5. Ograniczanie ataków STP
W przypadku ataków STP, atakujący może podłączyć swoje urządzenie i wymusić zmianę topologii poprzez wysłanie BPDU z wysokim priorytetem w BID. Ochroną przed tego typu działaniami jest użycie technologii PortFast oraz BPDU Guard.
PortFast przyspiesza stan gotowości portu o przesyłania danych. Port przenoszony jest natychmiast ze stanu blokowania w stan przekazywania. PortFast jest przeznaczony dla użytkowników końcowych i tylko dla nich powinien być stosowany. BPDU Guard jest mechanizm zabezpieczającym przed pojawieniem się komunikatów BPDU na niepożądanych portach. Jeśli taki komunikat się pojawi przy skonfigurowanym BPDU Guard, taki port zostanie ustawiony w stan error-disabled..
Konfiguracji PortFast, możemy dokonać na dwa sposoby. Konfigurować po kolei każdy z portów tak jak przedstawiono to na poniższym przykładzie.
S1#conf t Enter configuration commands, one per line. End with CNTL/Z. S1(config)#int fa0/4 S1(config-if)#switchport mode access S1(config-if)#spanning-tree portfast %Warning: portfast should only be enabled on ports connected to a single host. Connecting hubs, concentrators, switches, bridges, etc... to this interface when portfast is enabled, can cause temporary bridging loops. Use with CAUTION %Portfast has been configured on FastEthernet0/4 but will only have effect when the interface is in a non-trunking mode.
Możemy również skonfigurować PortFast domyślnie dla całego przełącznika. Tak jak na przykładzie:
S1#conf t Enter configuration commands, one per line. End with CNTL/Z. S1(config)#spanning-tree portfast default %Warning: this command enables portfast by default on all interfaces. You should now disable portfast explicitly on switched ports leading to hubs, switches and bridges as they may create temporary bridging loops.
Aby sprawdzić konfigurację PortFast możemy użyć polecenia
show spanning-tree summary. Poniżej
znajduje się wynik jego działania:
S1#show spanning-tree summary Switch is in pvst mode Root bridge for: none Extended system ID is enabled Portfast Default is enabled PortFast BPDU Guard Default is disabled Portfast BPDU Filter Default is disabled Loopguard Default is disabled EtherChannel misconfig guard is enabled UplinkFast is disabled BackboneFast is disabled Configured Pathcost method used is short Name Blocking Listening Learning Forwarding STP Active ---------------------- -------- --------- -------- ---------- ---------- Total 0 0 0 0 0
Drugim mechanizm do skonfigurowania jest BPDU Guard. Metoda jest taka sama jak w przypadku PortFast, różnią się tylko polecenia.
S1#conf t Enter configuration commands, one per line. End with CNTL/Z. S1(config)#int fa0/4 S1(config-if)#spanning-tree bpduguard enable S1(config-if)#exit S1(config)#spanning-tree portfast bpduguard default
Teraz możemy wyświetlić sobie jeszcze raz podsumowanie konfiguracji STP.
S1#show spanning-tree summary Switch is in pvst mode Root bridge for: none Extended system ID is enabled Portfast Default is enabled PortFast BPDU Guard Default is enabled Portfast BPDU Filter Default is disabled Loopguard Default is disabled EtherChannel misconfig guard is enabled UplinkFast is disabled BackboneFast is disabled Configured Pathcost method used is short Name Blocking Listening Learning Forwarding STP Active ---------------------- -------- --------- -------- ---------- ---------- Total 0 0 0 0 0
Możemy skonfigurować przełącznik w taki sposób, aby automatycznie odblokowywał porty w stanie error-disabled. W przypadku naruszenia BPDU Guard, możemy uruchomić to poleceniem:
S1(config)#errdisable recovery cause psecure-violation
Domyślnym okresem karencji jest 300 sekund = 5 minut. Konfigurację
automatycznego podnoszenia portu ze stanu error-disabled
możemy sprawdzić (w tym i okres karencji) za pomocą polecenia
show errdisable recovery
S1#show errdisable recovery ErrDisable Reason Timer Status ----------------- -------------- arp-inspection Disabled bpduguard Disabled channel-misconfig Disabled dhcp-rate-limit Disabled dtp-flap Disabled gbic-invalid Disabled inline-power Disabled link-flap Disabled mac-limit Disabled loopback Disabled pagp-flap Disabled port-mode-failure Disabled psecure-violation Disabled security-violation Disabled sfp-config-mismatch Disabled small-frame Disabled storm-control Disabled udld Disabled vmps Disabled Timer interval: 300 seconds
2.11.6. Wyłączenie protokołu CDP
Jeśli chcielibyś uchronić nasze urządzenia przez pozyskiwaniem z nich danych, które można wykorzystać do ataków (przed rozpoznaniem). To dobrym pomysłem jest wyłącznie protokołu CDP oraz LLDP. Te protokoły możemy wyłączyć globalnie lub dla poszczególnych interfejsów.
- Wyłącznie globalne CDP i LLDP -
no cdp runino lldp run. - Wyłącznie na interfejsie -
no cdp enableino lldp transmit,no lldp receive.
Ponowne włączenie tych protokołów wymaga użycia tych samych poleceń,
ale bez słowa no na początku.
Podsumowanie
W tym rodziale dowiedzieliśmy się jak możemy skonfigurować Cisco IOS na przełącznikach, aby zapobiec atakom z poznanym w 10 rozdziale. Poznaliśmy zabezpieczenia portów oraz metody ochrony przez atakami na sieci VLAN, DHCP, ARP oraz STP.
Zadanie praktyczne - Packet Tracer
Konfiguracja zabezpieczeń przełącznika - scenariusz
Konfiguracja zabezpieczeń przełącznika - zadanie
Laboratorium
Konfiguracja zabezpieczeń przełącznika
2.12. Koncepcje WLAN
Sieci bezprzewodowe są wygodną alternatywą dla połączeń kablowych. Dzięki nim, możemy podłączyć wiele urządzeń bez prowadzenia kabli. Połączenia bezprzewodowe pozwalają nam na korzystanie z takich urządzeń jak tablety czy smartfony. Przy dobrze skonfigurowanej sieci bezprzewodowej, możemy swobodnie przemieszczać się po firmie bez utraty połączenia z siecią. Korzystając z wielu zalet łączności bezprzewodowej nie które firmy decydują się na użycie okablowania tam tylko gdzie jest ono niezbędne, natomiast hosty końcowe wykorzystują jedynie połączenia bezprzewodowe.
Sieci bezprzewodowe są oparte na standardach IEEE i można je ogólnie podzielić na cztery główne typy: WPAN, WLAN, WMAN, WWAN.
- Wireless Personal-Area Networks (WPAN) - Nadajniki w tej sieci korzystają z niskiej mocy. Zasieg zwykle osiąga od 6 do 9 metrów. Przykładami takich sieci może być technologia Bluetooth czy ZigBee (wykorzystywane głównie w IOT). Technologię wykorzystywaną do sieci WPAN opisują standardy 802.15. Sieci tego typu wykorzystują częstotliwości 2.4GHz.
- Wireless LAN (WLAN) - Sieć bezprzewodowa wykorzystywana do komunikacji przypominającej klasyczną sieć komputerową. Jej nadajnik zwykle obejmują średni obszar, do około 100m. Sieci tego rodzaj świetnie nadają się do wymiany informacji w średniej wielkości biurze lub domu. Nie kiedy pochodne komunikacji tego rodzaju wykorzystywane są do łączenia sieci między budynkami, czy nieco dłuższe odległości. Sieci WLAN opisują technologie 802.11 i korzystają one z ogólnodostępnych pasm 2.4 GHz oraz 5 GHz.
- Wireless MANs (WMAN) - Łączność bezprzewodowa rozciągająca się na obszarze jednego miasta lub określonej jego części. Wykorzystuję najczęściej licencjonowane częstotliwości.
- Wireless WANs (WWAN) - Wykorzystanie nadajników bezprzewodowych aby zapewnić zasięg na rozległym obszarze geograficznym. Wykorzystują do tego licencjonowane częstotliwości radiowe.
Wykorzystwane przez użytkowników technologie radiowe, wykorzystują nielicencjonowane aby móc zapewnić transmisję danych między użytkownikami. Każdy może z nich korzystać zaopatrując się chociażby w router bezprzewodowy klasy SOHO czy telefon komórkowy wykorzystujący technologię Bluetooth. Spośród takich technologii bezprzewodowych możemy wyróżnić:
- Bluetooth, technologia wykorzystująca częstoliwości nielicencjonowane do przesyłania plików z urządzenia na urządzenie czy strumieniowania dźwieku do jego odtwarzacza np. do słuchawek. Technologia ta wykorzystywana jest również przez systemy internetu rzeczy. Możemy wyodrębnić dwie technologie takie jak BLE (Bluetooth Low Energy), wykorzystywaną przez różnego rodzaju czujniki. Działa ona za zasadzie siatki, gdzie jedne z uczestników wymiany informacji w sieci tego rodzaju, przekazuje informacje dalej, aż do odbiorcy. Inną technologią jest BR/ERD (Bluetooth Basic Rate/ Enchanced Rate), wykorzystując topologę punkt-punkt, w celu np. strumieniowania muzyki. Bluetooth obejmuje standard 802.15 WPAN.
- WiMAX - Standard IEEE 802.16 WWAN, opracowany jako alternatywa dla szerokopasnowych łączy kablowych. Nie przyjął się jednak i szybko został zastąpiony przez sieci komórkowe.
- Szerokopasmowa sieć komórkowa - Sieci bezprzewodowe wykorzystywane głównie przez telefonię komórkową, ale mogą, działać za pomocą specjalnych modemów na innych urządzeniach takich jak tablety czy laptopy. Osiągają dobre przepustowości, a gęsta sieć komórek (obszarów działania stacji bazowej wraz z jej klientam (telefonami)) powoduje, że rzadko kiedy tracimy zasięg z taką siecią. Mogą spadać jej właściwości nośne, które mogą być uzależnione od wielu czynników, tak ich jak ilość klientów w danej komórce. Istnieją dwa rodzaje sieci komórkowej GSM - standard międzynarodowy oraz CDMA działający jedynie w Stanach Zjednoczonych. Obecna dominującą technologią w sieci komórkowej jest sieć 4 generacji, jednak już wiele urządzeń korzysta sieci 5 generacji, pozwalającej na 100 razy szybsze transfery oraz większą pojemność komórek.
- Szerokopasmowe łącza satelitarne - Tego rodzaju technologią jest wyborem ostatecznym. Działa tam gdzie inne technologie są niedostępne. Technologia ta korzysta z satelit krążących po orbice ziemi.
Na tym kursie, będziemy skupiać się na bezprzewodowych sieciach LAN. Sieci te pracują z częstoliwoscią 2.4 GHz lub 5 GHz. Wykorzystując przy tym odpowiednie standardy IEEE 802.11, takie jak:
- 802.11 - 2.4 GHz - Prędkość do 2 Mbps.
- 802.11a - 5 GHz - Prędkość do 54Mb/s, mniejszy zasięg, brak kompatybliność z poźniejszym standardami.
- 802.11b - 2.4 GHz - Prędokość do 11 Mb/s, większy zasięg, niż 802.11a, lepsza propagacja sygnału.
- 802.11g - 2.4 GHz - Prędkość do 54Mb/s, kompatybilny z 802.11b.
- 802.11n - 2.4 GHz/5 GHz - Wyższa prędkość transmisji od 150 do 600Mb/s przy dobrych warunkach środowiskowych (propagacji). Punkty dostępowe oraz klienci wymagają wielu anten oraz technologi MIMO, kompatybilny z 802.11a/b/g, z uwzględenieniem ograniczeń prędkości.
- 802.11ac - 5GHz - zapewnia szybkość transmisji od 450 do 1,3Gb/s wykorzystując MIMO. Obsługuje do ośmiu anten. Kompatybilny z urządzeniami 802.11a/n z uwzględnieniem ograniczeń prędkości.
- 802.11ax - 2.4GHz/5GHz - Najnowszy standard umożliwiający wyższe szybkości transmisji danych, wiekszą wydajność, obsługę wielu urządzeń oraz poprawioną wydajność energetyczną.
Na normalizację standardów bezprzewodowych, odpowiada trzy organizacje: ITU (regulacje częstotliwości radiowych i orbit satelitarnych), IEEE (modulacja sygnałów częstoliwości radiowej), oraz WiFi Alliance, które nie tyle zajmuje się normalizowaniem łączności bezprzewodowej co promowanie rozwoju technologii oraz wydawanie producentom odpowiednich certyfikatów za zgodność ze standardami.
2.12.1. Komponenty siec WLAN
Jako komponenty sieci bezprzewodowej możemy wymienić takie jak:
- Bezprzewodowe karty sieciowe - specjalnego rodzaju adapter wpinany w porty USB lub montowany w komputerze, aby móc wykorzystać częstotliwości radiowe jako medium transmisyjne.
- Bezprzewodowy router domowy - urządzenie sieciowe integrujące w sobie 3 rodzaje urządzeń: punkt dostepowy, przełącznik oraz router. Zapewnia użytkownikom domowym za pewnia zarówno przewodowy jak i bezprzewodowy dostęp do Internetu.
- Bezprzewodowe punkty dostępowe - punkt dostępowy łączy hosty bezprzewodowe z siecią kablową. Jego zadaniem jest właśnie pozwolić urządzeniom, które nie mogą fizycznie wpiąć kabla na dostęp do takich samych zasobów, jak hosty kablowe. Oczywiście w teorii.
Same punkty dostępowe dzielą się na dwie kategorie: autonomiczne punkty dostępowe oraz bezprzewodowe punkty dostępu oparte na kontrolerze. Autonomiczne punkty to zwykłe urządzenia, które podłączamy do prądu i do sieci następnie konfigurujemy, i to wszystko. W przypadku tej drugiej kategorii, punkty dostępowe można powiedzieć, że służą z nadajniki sygnału radiowego. O większości rzeczy decyduje kontroler, w którym to konfigurujemy całą infrastrukturę. W przypadku autonomicznych punktów, trzebą by te czynności powtórzyć, lub załadować konfigurację. W przypadku kontrolera robimy to raz. W tym również przypadku (kontrolera) konfiguracja może okazać nieco bardziej skonplikowana.
Ostatnim z komponentów są anteny, do wyboru mamy: dookólne - które propagują sygnał w kształcie kuli, kierunkowe - których propagacja jest bardziej skupiona w jednej wiązce sygnału (takie anteny trzeba ustawiać). Ostatnim rodzajem anten są to anteny MIMO - system wielu anten, który stostuje aby zwiększyć przepustowość, tego rodzaju rozwiazania wykorzystywane są w standardaach od 802.11n do ax. W MIMO można używać nawet do 8 anten.
2.11.2. Działanie sieci WLAN
Lokalne sieci bezprzewodowe, podobnie do sieci kablowych mają określone topologie, określane mianem trybu pracy, takimi jak:
- Tryb ad hoc - w tym trybie urządzenia łączą się ze sobą. Każdy z każdym, bez udziału punktu dostępowego lub routera bezprzewodowego. Tego typu siecią są, wszelkie połaczenia Bluetooth.
- Tryb infrastruktury - gdzie do połączenia wykorzystywany jest punkt dostępowy lub router bezprzewodowy. Te urządzenia łączą się do sieci przy użyciu systemu dystrybucyjnego jakim raczej będzie Ethernet.
- Tethering - w tym trybie pracy urządzenia łączą się z punktem centralnym, aby uzyskać dostęp do innej sieci bezprzewodowej, takiej jak sieć komórkowa. Ten tryb pracy jest odmianą trybu ad hoc.
Tryb infrastruktury dzieli się na dwa bloki konstrukcyjne. Podstawowy - BSS oraz rozszerzony - ESS. W przypadku BSS jeśli wyjdziemy poza obszar zasiegu naszej sieci bezprzewodowej, wówczas utracimy możliwość komunikacji z innymi jej hostami. Natomiast w przypadku ESS gdzie punkty dostępowe rozgłaszające BSS są połączone ze sobą za pomocą systemu dystrybucyjnego, nie stracimy łączności z hostami naszej macierzystej BSS, mimo opuszczenia obszaru jej działania.
Ramka 802.11 różni się w nagłówku od standardowej ramki Ethernet. Zawiera ona takie pola jak:
- Kontrola ramki - Identyfikuje rodzaj ramki bezprzewodowej i zawiera pola podrzędne, takie jak wersja protokołu, typ ramki, typ adresu, zarządzanie energią oraz ustawienia zabezpieczeń.
- Czas trwania - zazwyczaj używane do określenia czasu pozostałego do odbioru ramki.
- Adres 1 - Zazwyczaj zawiera adres MAC bezprzewodowego urządzenia odbierającego lub punktu dostępu.
- Adres 2 - Zazwyczaj zawiera adres MAC bezprzewodowego urządzenia wysyłającego lub punktu dostępu.
- Adres 3 - Czasami zawiera docelowy adres MAC, przykładowo adres interfejsu routera (bramy domyślnej), do którego połączony punkt dostępu.
- Sekwencja kontrolna - zawiera informacje do kontrolowania skwencjonowania i fragmentowania ramek.
- Adres4 - Przeważnie pozostaje pusty, ponieważ stosuje się go tylko w trybie ad hoc.
Poza nagłówkiem w ramce znajduje się jeszcze pole danych oraz pole sumy kontrolnej (FCS).
Sieci WLAN wykorzystują półdupleksowe medium w postaci kanału częstotliwości radiowej. Przez co nie możliwe jest jednoczene nadawanie i odbieranie danych. Dlatego też w bezprzewodowych sieciach LAN do kontroli dostępu do medium, wykorzystywany jest algorytm CSMA/CA, który jest wariacją algorytmu CSMA/CD, znanego z technologii Ethernet.
Połącznie bezprzewodowe klienta oraz punktu dostępu czy bezprzewodowego routera, nazywane jest skojarzeniem, jest to proces trój-etapowy, w którym to klient musi: wykryć punkt dostępu, uwierzytelnić się przed nim i przypisać (skojarzyć) się pod niego. Aby do tego doszło muszą zgadzać się takie czynniki jak: SSID (nazwa sieci), hasło (bez tego uwierzytelnianie nawet się nie uda), tryb sieci (standardy, chociaż większość standardów jest kompatybilna wstecz), tryb zabezpieczeń (zgodność między stronami z WEP, WPA, WPA2, WPA3), czy ustawienia kanału. Te parametry muszą być ustawione na obu stronach takie same, aby doszło do skojarzenia.
Samo wykrywanie sieci bezprzewodowych może odbywać w dwóch trybach. W trybie pasywnym punkt dostępu wysyła co jakiś czas ramki 802.11, zwane beacon-ami. Zawierają one, nazwe sieci, obsługiwane standardy oraz ustawienia zabezpieczeń. W przypadku drugiego trybu aktywnego, to klient wysyła próbki w przestrzeń w celu znalezienia punktu dostępu rozgłaszającego żądaną przez niego sieć. W takiej próbce wysyła nazwę sieci oraz obsługiwane standardy, wówczas punkt dostępu odpowiemu podobnym komunikatem uzupełnionym o ustawienia zabezpieczeń. Obecnie urządzenia klientów, działają zarówno w jednym jak i w drugim trybie. Wyświetlając dostępne sieci - poprzez tryb pasyny i próbując podłączyć się sieci, z którymi już wcześniej się łączyły - przez tryb aktywny. Tryb aktywnym możemy wymusić pod czas konfiguracji sieci bezprzewodowej, ukrywając jej nazwę.
12.3. Działanie CAPWAP
Do tej pory mówilśmy o autonomicznych punktach dostępowych. To teraz coś o punktach dostępowych zarządzanych przez kontroler.
CAPWAP jest protokołem pozwalającym na zarządzanie wieloma punktami dostepowymi jak i sieciami WLAN. Jest on również odpowiedzialny za enkapsulację i przezywanie ruch klienta między AP oraz WLC. Jest to protokołu otwarty, opracowany przez IEEE.
Ważnym elementem działania CAPWAP jest rodzielenie kontroli dostępu do medium między dwa komponenty: MAC AP oraz MAC WLC.
MAC AP odpowiada za beacon-y oraz odpowiedzi na próbkowanie, przetwarzenie pakietów i retransmisje, kolejkowanie ramek i priorytetyzacje oraz szyfrowanie i deszyfrowanie warstwy MAC.
Natomiast MAC WLC odpowiada za uwierzytelnienie, skojarzenia i ponowne kojarzenie klientów roamingowych, translacji ramek na inne protokoły oraz zakończenie ruchu 802.11 na interfejsie przewodowym.
Możliwe jest dodatkowe zabezpieczenie zarówno danych klientów jak i danych sterujących między WLC a AP, za pomocą protokołu DTLS. Domyślnie ten protokół, jest włączony dla ruchu sterującego, ale dla ruchu danych musi zostać włączony przez adminstratora. Dodatkowo DTLS, gdy ma szyfrować dane użytkowników wymaga licencji, w którą należy się zaopatrzyć przed uruchomieniem tego protokołu na AP. DTLS daje dodatkową warstwę ochrony, gdzie tak naprawdę jej nie ma. Metody zabezpieczeń sieci bezprzewodych tyczą się tylko i wyłącznie odcinka od klient do punktu dostępowego.
Oczywiście możliwe jest kontrolowanie przez WLC, punktów dostępowych w innych sieciach, także w oddziałach firmy przez Intenet. Niestety połączenia internetowe bywają zawodne na co firma Cisco swojego czasu wprowadziła takie rozwiązania jak FlexConnect AP, pozwalają one działanie w dwóch trybach w trybie Autonomicznym i WLC. W zależności od dostępności WLC przez CAPWAP. Jeśli nie będzie miał on połączenia z WLC to wówczas przejmie część obowiazków na siebie, np. przełącznie ruchu danych klienta czy wykonywanie uwierzytelniania.
2.12.4. Zarządzenia kanałem transmisji
Urządzenia korzystające ze sieci bezprzewodowych, są odbiornikami radiowymi dostrojonymi do określonej częstotliwości. Częstotliwości za przypisywane w zakresach, nazwanych kanałami. Gdy dany kanał jest zbyt intensywnie wykorzystywany wówczas staje się kanałem przesyconym, co pogarsza warunki transmisyjne. Przez lata opracowano kilka technik pozwalających zmniejszyć przesycenie kanałów w sieci bezprzewodowych wykorzystuje się trzy z nich: DSSS, FHSS (bluetooth) oraz OFDM, który jest wykorzystywane przez obecnie stosowane standardy sieci bezprzewodowych. Najnowszy standard wykorzystuję odmianę OFDM - OFDMA.
W wiekszości standandardów sieci WLAN wykorzystujących częstotliwość 2,4 GHz mają do dyspozycji 11 kanałów (dla Ameryki Północnej), 13 (dla Europy), oraz 14 (dla Japonii) w zależności od położenia geograficznego sieci. Było by wszystko w porządku gdyby nie fakt, że każdy kanał ma przydzielone pasmo 22 MHz i kanały odzielone są od siebie o 5 MHz. Co oznacza, że one nakładają się na siebie, w praktyce jeśli sieci, które punkty dostępowe rozgłaszają sieci z ustawionymi kanałami zbyt blisko siebie to mogą się one wzajemnie zakłócać. Dlatego też konfigurując ten parameter, warto wiedzieć o tym że tylko częstotliwość co cztery kanały, tj. 1, 6 i 11, nie będą się na siebie na kładać.
Nieco inaczej jest w przypadku częstotliwości 5 GHz. Tutaj są 24 kanały oddzielone od siebie o 20 MHz. Mimo, że występują drobe nałożenia, to kanały nie bedą się zakłócać. W przypadku tej częstotliwości kanały numerowane są od 36 co 4 do 64, następnie do 100 do 140, ostatnią grupą jest są kanały od 149 do 161 i co dwa kanały występuję kanał, którego częstotliwość nie będzie wchodzić w częstotliwość innego kanału.
Chcąc wdrożyć sieć WLAN, w firmie należy wziąć pod uwagę takie czynniki jak: dobre rozgłaszanie sygnału (najlepiej na środku biura), potencjalne źródła zakółceń czy umiejscowienie punktów dostępowych (powinny znajdować się tam gdzie zazywczaj będą klienci).
2.12.5. Zagrożenia w sieciach WLAN
Sieci bezprzewodowe niosą ze sobą oczywiście wiele zagrożeń. Pierwszą taką obawą jest fakt, że do takiej sieci może podłączyć się każdy, ponieważ nie możemy okiełznać fal radiowych - zamykając je w jednym pomieszczeniu (oczywiście tych, z których korzystamy na codzień). Mając odpowiedni sprzęt możemy próbować się podłączyć do sieci będącej dość głęboko w budynku. Te warunki fizyczne niosą ze sobą kilka zagrożeń takich jak:
- Przechwytywanie danych - informacje w sieci bezprzewodowej powinny być szyfrowane, aby zapobiec przechywceniu.
- Intruzi bezprzewodowi - techniki uwierzytelniania w sieciach bezprzewodowych szybko zniechęcają nieutoryzowanych użytkowników próbujących uzyskać dostęp do zasobów sieciowych.
- Ataki odmowy usługi (DoS) - czasami sieć bezprzewodowa może nie działać prawidło i może mieć to dwojaką przycznę, albo jest to przypadek, albo celowe złośliwe działanie.
- Obce punkty dostępu - atakujący mogą próbować się podszywać pod obecną infrastrukturę, w celu potencjalnego wyłudzenia danych.
Ataki DoS w sieciach WLAN mogą wynikiem: nierprawidłowej konfiguracji urządzeń - urządzenia mogły zostać źle skonfigurowane przypadkowo lub celowo przez intruza, przez co prawowici użytkownicy nie mogą korzystać z połączeń bezprzewodowych; Intruzi mogą celowo ingerować w komunikację poprzez zakłócenie, wyłączenie sieci lub podstawienie punktu dostępowego, które nie zapewni odpowiedniej komunikacji z innymi hostami czy zasobami sieci. Taki atak DoS, może też zostać wywołany przez nas samych prze nieuwagę, wystarczy gdzieś między hostem a punktem dostępowym ustawić źródło zakłóceń. W przypadku 5 GHz, to ta częstotliwość jest bardziej odporna na zakłócenia, ponieważ w naszym otoczenie nie znajduje się wiele urządzeń, które mogły by emitować tą częstotliwość.
Obce punkty dostępowe mogą być umieszczane na obszarze sieci z dwóch różnych pobudek. Pierwszą z nich jest przeprowadzenie ataku Man in the Middle, w celu przechwycenia informacji użytkowników sieci bezprzewodowych lub celu odłączenia go od zasobów sieci. Jedną z metod ochrony, jest skanowanie częstotliwości w celu w celu wykrycia takich podstawionych urządzeń. Inną metodą jest skonfigurowanie nie słabszego niż WPA2 AES (będzie o tym w następnym podrozdziale) trybu uwierzytelniania.
O ataku Man in the Middle wpominaliśmy podczas omawiania obecego punktu dostępu. Atak tego typu polega na ustawieniu się atakującego w roli pośrednika, w celu przechwycenia informacji wysyłanych i odbieranych przez innych użytkowników sieci. Czasami do przeprowadzenia takiego ataku wystarczy odpowiednie warunki sieciowe oraz odpowiednia antena, warunki sieciowe i oprogramowanie.
2.12.6. Zabezpieczanie sieci WLAN
Metod na zabezpieczenie sieci WLAN jest kilka. Możemy zaczać od tego, że wymusimy na klientach tryb aktywny, po przez ukrycie SSID oraz dodamy do odpowiedniej listy adresy MAC urządzeń, które faktycznie mają łączyć się z tą siecią. Jednak zabepieczenia tego typu to tylko protezy, jeśli nie mamy zaimplementowanych metod uwierzytelniania.
Metody uwierzytelniania możemy wydzielić dwie, pierwszą z nich jest uwierzytelnianie systemu otwartego, ta metoda to tak naprawdę jego brak. Klikamy nazwę sieci i jesteśmy podłączeni. Obecnie nawet publicznie dostępne sieci, rezygnują z tego rozwiązania na rzecz udostępionego publicznie klucza współdzielnego (tzw. hasła do WiFi). Drugą metodą powszechnie stosowaną jest użycie klucza współdzielonego, metoda ta wymaga znajomości tego klucza, przez klienta. Ta metoda poza uwierzytelnieniem zapewnia szyfrowanie transmisji danych między klientem a punktem dostepu.
Metoda uwierzytelniania z użyciem klucza posiada klika wykorzystywanych w sieciach technik, takich jak: WEP, WPA, WPA2, WPA3.
- Wired Equivalent Privacy (WEP) - słaby standard zabezpieczeń, łatwy do złamania. Nie powino się go sotosować.
- Wi-Fi Protected Access (WPA) - pierwszy ze standarów WPA, ten rodzaj korzysta z WEP, ale stosuje silniejsze szyfrowanie w postaci mechanizmu TKIP, który zmienia klucz dla każdego pakietu.
- WPA2 - standard bezpieczeństwa sieci bezprzewodowych. Wykorzystuje zawansowany i silny mechanizm szyfrowania Advanced Encryption Standard (AES). Uważany za najśliniejszy mechanizm szyfrowania, do tej pory.
- WPA3 - najnowszy standard uwierzytelniania w sieci bezprzewodowej, urządzenia z jego obsługą nie pozwalają na korzystanie z innych starszych rozwiązań, wymagają również stosowania mechanizmy Protect Management Frames (PMS).
Chcąc skonfigurować metodę uwierzytelnia na domowym routerze możemy spotkać się z różnymi technikami, takimi jakie wpisałem powyżej, natomiast w przypadku WPA oraz WPA2, będzie mieć do czynienia z:
- Personal - uwierzytelnienia z pomocą klucza współdzielonego, dobre do zastosowań domowych, gdzie możemy zaufać urządzeniom i użytkownikom.
- Enterprise - uwierzytelnienia za pomocą polecenia serwera uwierzytelniania znanego z protokołu 802.1X, takiego jak RADIUS, gdzie wówczas punkt dostępu jest wystawcą uwierzytelniania. Klient natomiast do połączania się do takiej sieci, będzie musiał podać swój indywidualny login oraz hasło ustalane przez administratora. Dodatkowo punkt dostępowy będzie musiał się uwierzytelnić sam przed serwerem RADIUS, aby móc uwierzytelniać pracowników, przy użyciu klucza zapisanego w konfiguracji.
Po wybraniu techniki uwierzytelniania, pozostanie nam wybór metody szyfrowania. Do wyboru będziemy mieć dwie opcje:
- Temporal Key Intergration Protocol (TKIP) - metoda używana przez WPA, zapewnia obsługę starszego sprzetu, wykorzystując do tego WEP, ale eliminującego jego pierwotne wady.
- Advanced Encryption Standard (AES)/CCMP - metoda wykorzystywana przez WPA2, jest preferowana, ze względu na znacznie silniejsze metody szyfrowania, wykorzystuje metodę CCMP, dlatego też czasem jest tak nazywany.
Konfiguracja technik uwierzytelniania w klasie Enterprise wymaga podania metody szyfrowania, adresu IP serwera RADIUS, portu serwera - zazwyczaj: UDP/1812, UDP/1645 oraz wspólnego klucza. Dzięki niemu punkt dostępowy uwierzytelni się na serwerze RADIUS.
WPA3 jest nowy standardem bezpieczeństwa w sieciach bezprzewodowych. Standard WPA2 nie może już zostać uznany za bezpieczny. Tryb personalnego WPA3 udaremnia ataki siłowe, dla trybu Enterprise eliminuje mieszanie protokołów bezpieczeństwa z poprzednich standardów 802.11. WPA3 pozwala na szyfrowane sieci otwartych, w których nie podaje się żadnych haseł, a przesłanie danych między klietem a AP nadal jest bezpieczne. WPA3 poprawia uwierzytelnianie wśród składników internetu rzeczy, eliminując potrzebę działania niebezpiecznego mechanizmu WPS.
Podsumowanie
W tym rozdziale zapoznaliśmy z działaniem sieci bezprzewodowych poznaliśmy ich rodzaje, które występują wokół nas, ich topologie, z których korzystamy na co dzień w domu, w szkole czy w pracy. Dowiedziliśmy się w jaki sposób sieci bezprzewodowe, wykorzystują przekazaną im częstotliwość radiową. Na koniec poznaliśmy zagrożenia na jakie możemy się natknąć podczas konfiguracji, administracji czy też korzystania z takich sieci, jednak dowiedziliśmy się jak można się przed nimi uchronić, jakie metody uwierzytelniania wybrać oraz jakie je skonfigurować.
2.13. Konfiguracja siec WLAN
Bezprzewodowe punkty mogą dzielić się na dwie kategorię. Pierwszą z nich są autonomiczne punkty dostepowe, które podłącza się do prądu, do sieci i konfiguruje. Jeśli ma być więcej niż jeden to trzeba te czynności wykonać, dla każdego urządzenia z osobna. Taka konfiguracja jest przewidziana średniej wielkości firmy. W przypadku domu lub małego biura raczej wystarczy router bezprzewodowy.
Ze względu, że zakres materiału obejmuje konfiguracje sieci bezprzewodowej, to skupimy się na podstawowej konfiguracji takiego urządzenia.
Na początek musimy zalogować na routerze do panelu pozwalającego na konfigurację. Większość urządzeń domowych pozwala na dostęp do panelu administracyjnego z poziomu przeglądarki internetowej. Dane dostępowe mogą znajdować, albo na spodzie urządzenia na naklejce lub w instrukcji do niego dołączonej.
Następną czynnością jest zmiana domyślnego hasła administratora
urządzenia. Tym przypadku klikamy zakładkę
Administration, następnie w sekcji
Router Access podajemy nowe hasło dwa
razy w celu potwierdzenia. Zapisujemy ustawienia przy użyciu
przycisku Save Settings. Urządzenie
wyloguje nas i poprosi o zalogowanie się nowym hasłem.
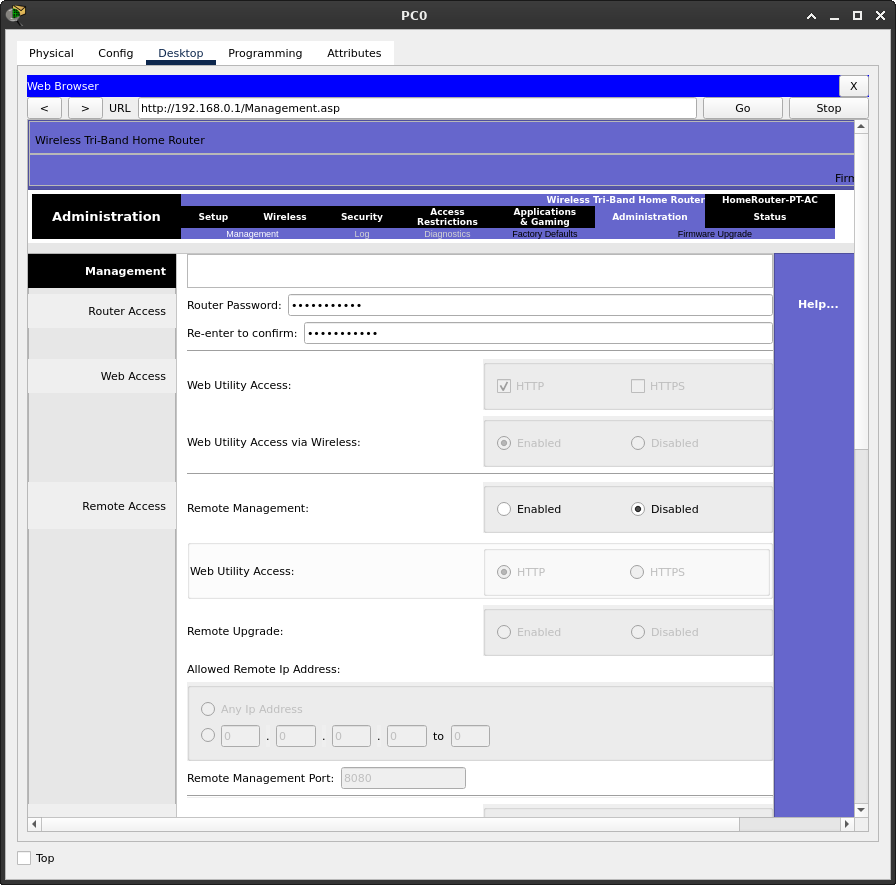
Po wykonaniu tej czynności, wypadało by ustawić jakiś adres IP dla
naszej sieci LAN. Przy czym tutaj należy pamiętać o tym, aby również
zaktualizować adresy IP w konfiguracji serwera DHCP. W zakładce
Setup, w sekcji
Router IP ustawiamy adres dla naszej
sieci oraz wybieramy maskę. W sekcji
DHCP Server Settings początęk puli
w opcji Start IP Address oraz jej
koniec Maximum number of Users.
Na końcu zapisujemy ustawienia. Router prawdopodobnie uruchomi się
ponownie, po chwili uzyskamy adres IP z nowej sieci i będziemy mogli
ponownie się na niego zalogować.
Po zmianie tych podstawowych ustawień możemy przjeść do konfiguracji
sieci bezprzewodowej. Ustawienia sieci bezprzewodowej znajdują się
zakładce Wireless. Na początku
w opcji Network Mode: możemy wybrać
tryb sieci. Jeśli taka sieć miała by obsługiwać stare urządzeń to
wypadałoby wybrać opcję Legacy, ale tryb mieszany
(Auto), jest również poprawnym ustawieniem.
Następną konfigurajcą jest zmiana SSID, na taki jaki odpowiada naszym
preferencjom, SSID powinień pozwolić nam rozpoznać sieć. SSID
konfigurujemy w opcji Network Name (SSID):
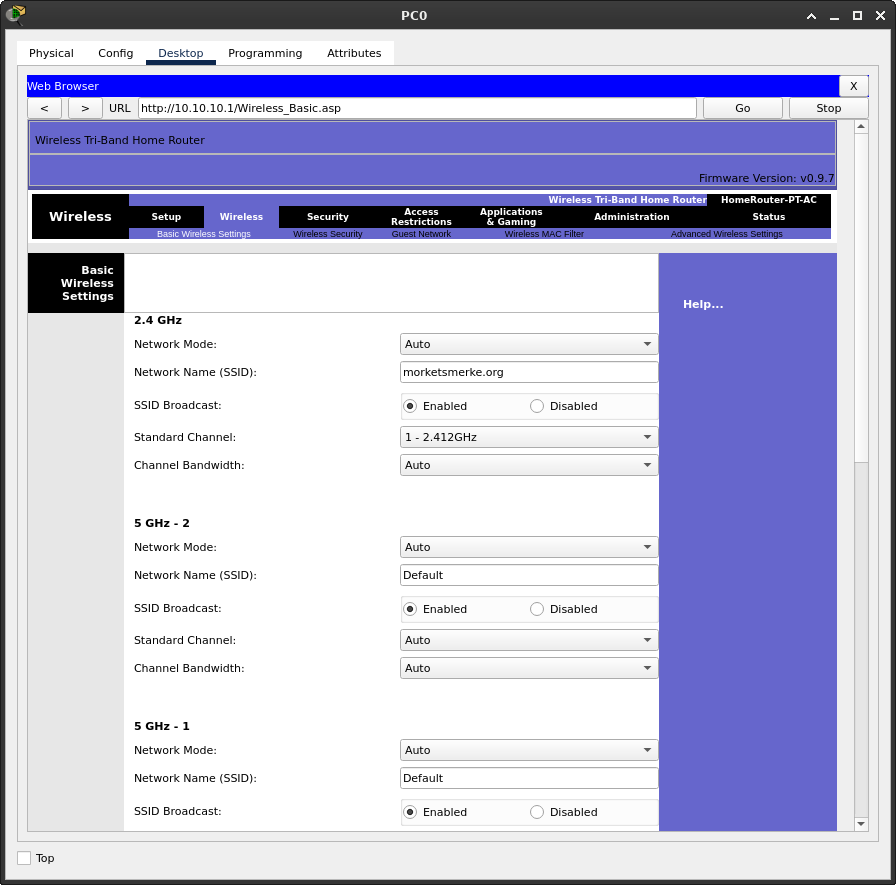
Następnie wybieramy dla naszej sieci kanał, warto wspomnieć, że w przypadku częstotliwości 2,4 GHz mamy do wyboru tylko 3 kanały. W celu sprawdzenia kanałów na których działają sieci w naszym otoczeniu, mozemy wykorzystać specjalne oprogramowanie na dystrybucje Linuksa, w tym Kali Linux lub na smartfon z systemem Android.
Kanał ustawiamy za pomocą opcji
Standard Channel.
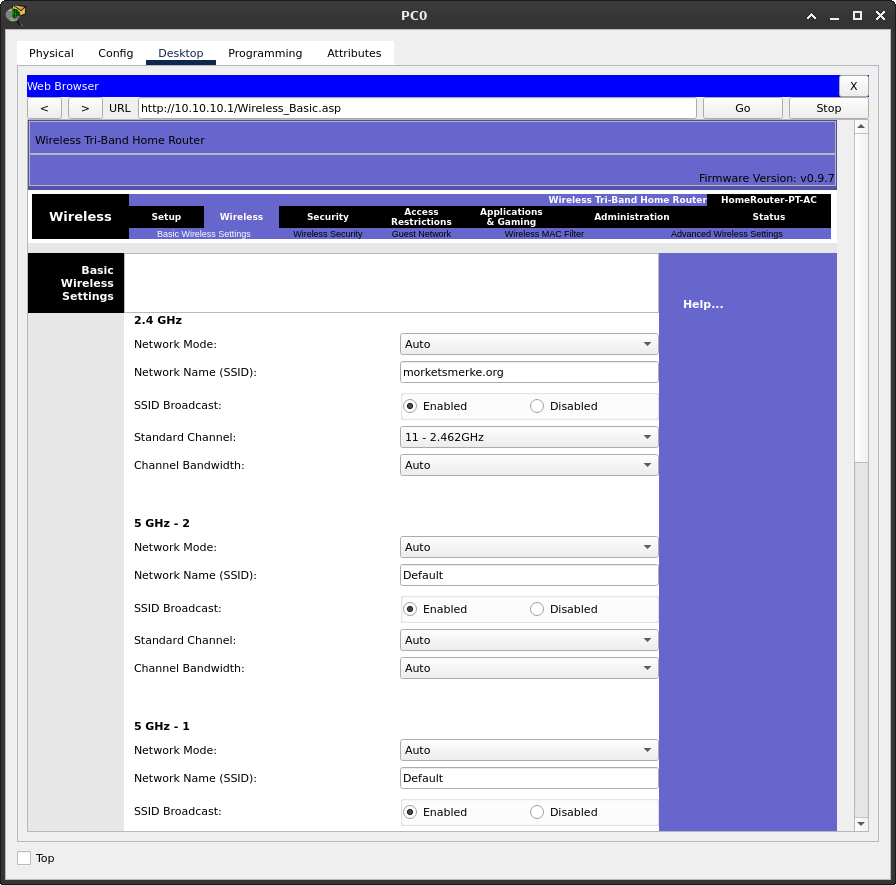
Pod zakładką Wireless znajdują się
podzakładki. Jedną z nich jest Wireless
Security, w niej będziemy ustawiać opcje bezpieczeństwa sieci
bezprzewodowej. Na początku musimy przestawić opcje
Security Mode z Disabled na
WPA2 Personal.
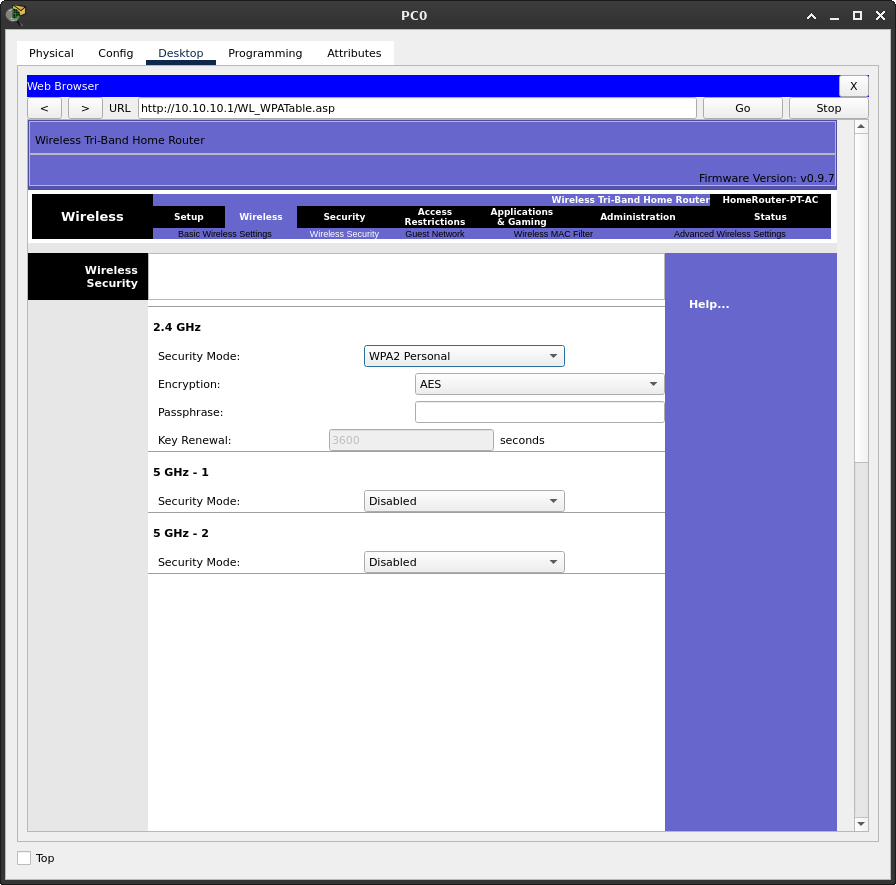
Po zmianie trybu, ukaże na się więcej opcji takich jak wybór metody
szyfrowania czy pole gdzie możemy zdefiniować hasło klucza
współdzielonego.
Metoda szyfrowania, jest akurat domyślnie ustawiona dobra, więc jej
zmieniać nie trzeba, ale hasło klucza należy ustawić. W polu
Passphrase:
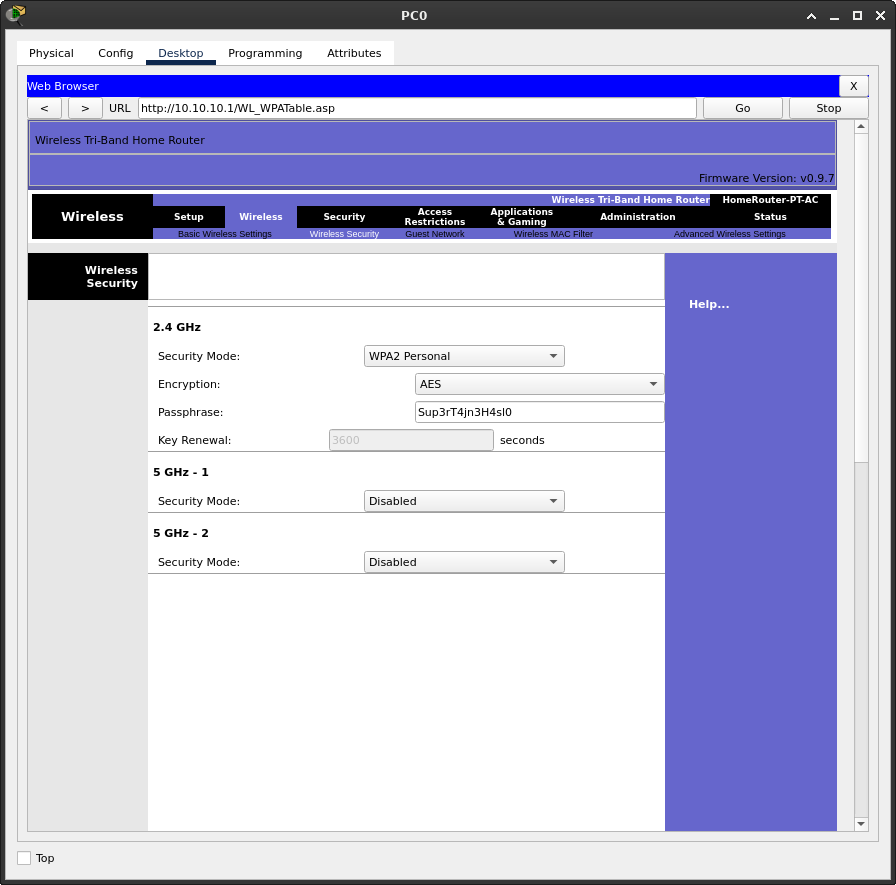
W ten sposób skonfigurowaliśmy router bezprzewodowy do działania na nie wielkim obszarze. No właśnie, zasięg takiego urządzenia może wachać się od 5 do 10 metrów w obszarze silnie zabudowanym. Dlatego też aby wzmocnić sygnał można zastosować punkty dostępowe, które bedą działać w trybie kratowym. Na podobnej zasadzie działają również wzmaczniacze sygnału.
Routery domowe aby zapenić dostęp do Internetu hostom sieci lokalnej, realizują funkcję NAT-u. Translację adresów źródłowych w pakietach wychodzących i adresów docelowych w pakietach przychodzących. Funkcja NAT-u realizowana jest przez firewall. Firewall jest też odpowiedzialny za inną funkcjonalność, taką jak jest przekierowanie portów. Ma ona na celu zapewnienie dostępu do hostów w sieci wewnętrzne (np. serwerów i ich usług) z zewnątrz. Do poprawnego działania taka funkcjonalość wymaga przydzielenia od usługodawcy stałego adresu IP, co może być dostępne wyłącznie dla klientów biznesowych. Ta funkcja działa na takiej zasadzie, że wewnętrzny port usługi wraz z IP hostującego komputera przypisuje się do zewnętrznego adresu IP do wybranego portu. Porty mogą być powiązane 1:1, tj. port wewnętrzny może mieć taką samą wartość jak port zewnętrzny.
Zadanie praktyczne - Packer Tracer
Konfiguracja sieci bezprzewodowej - scenariusz
Konfiguracja sieci bezprzewodowej - zadanie
Laboratorium
Konfiguracja sieci bezprzewodowej
2.13.1. Konfiguracja podstawowej sieci WLAN w sieci WLC
Po omówieniu autonomicznych punktów dostępowych przyszedł czas na WLC. Dostęp do kontrolera otrzymuje w takim sam sposób jak do routera bezprzewodowego. Przyczym kontrolery mogą mieć domyślnie ustawiony adres IP, a nawet skonfigurowany serwer DHCP. Dlatego też na początku warto podłączyć go do swojego komputera. Po wpisaniu adresu naszym oczom ukaże się taka o to strona. Na której musimy zdefiniować domyślnego użytkownika oraz nadać mu odpowiednie hasło. Hasło musi składać z min. 6 znaków, z jednej wielkiej litery i jednej cyfry.
Następnie urządzenie przeprowadzi nas przez wstępną konfigurację. W niej ustawimy nazwę systemową, kraj, datę i godzinę, strefę czasową, opcjonalnie serwer NTP. W drugiej części ustawimy konfigurację IP interfejsu zarządzania.
W drugiej części konfiguracji musimy zdefiniować chociaż jedną z sieci,
a więc podajemy Network Name (SSID),
wybieramy tryb uwierzytelniania (zostawiamy domyślnie, jest dobry),
następnie hasło. Ustawienie zaawansowane może zostawić domyślnie.
W następnym oknie zostanie nam wyświetlone podsumowanie konfiguracji i
musimy je potwierdzić za pomocą przycisku
Apply
Po zapisaniu ustawień urządzenie zostanie uruchomione ponownie. Po pewnym czasie może nic się nie dziać, należy wówczas zamknąc przeglądarkę i wpisać adres ponownie. Zapewne uzyskamy odpowiedź Server Reset Connection, wówczas trzeba zmienić w adres z http na https. Naszym oczom ukaże się taka o strona.
Klikamy zielony przycisk Login, pojawi
się okienko do logowania. Wpisujemy login oraz hasło, następnie klikamy
Login. Po zalogowaniu ukaże na się
taka o to strona.
Domyślną stroną startową jest podsumowanie, zawiera ona informacje zbiorcze na temat samego kontrolera, punktów dostępowych, klientów, wykrytych fałszywych elementów takich jak punkty dostępowe czy klienci. To podsumowanie zawiera również informacje o najczęściej wykorzystywanych sieciach WLAN oraz kilka dodatkowych informacji.
Chcąc skonfigurować sieć bezprzewodową należy kliknąć, zakładkę WLANs,
następnie, po prawej stronie znajduje się lista rozwijalna w niej
jeden element Create New, klikamy
przycisk Go.
Podajemy nazwę profilu oraz SSID i klikamy przycisk
Apply.
Po zatwierdzeniu zostanie przeniesieni w tryb edycji. W zakładce
General zaznaczamy w
Status,
Enabled.
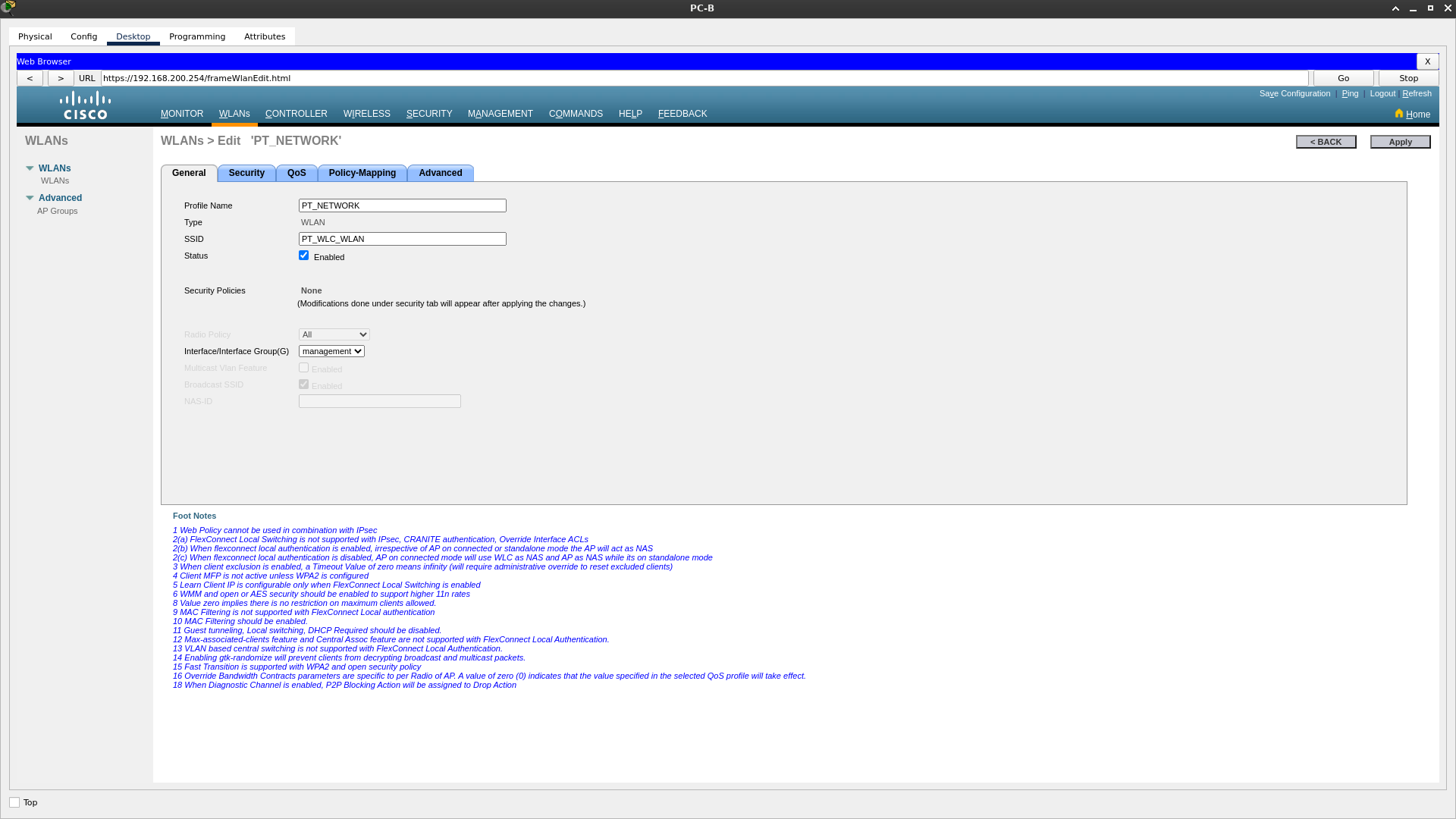
Następnie w zakładce Security, z listy
Layer 2 Security, wybieramy
WPA+WPA2, po wybraniu tego trybu
zostaną nam wyświetlone dodatkowe opcje. W sekcji
WPA+WPA2 Parameters, zaznaczamy
WPA2 Policy, automatycznie zostanie
wybrane WPA2 Encryption z domyślnie
zaznaczonym AES. W sekcji
Authentication Key Management
zaznaczamy PSK i w polu
PSK Format hasło klucza
współdzielonego, zapisujemy konfigurację wpisując przycisk
Apply
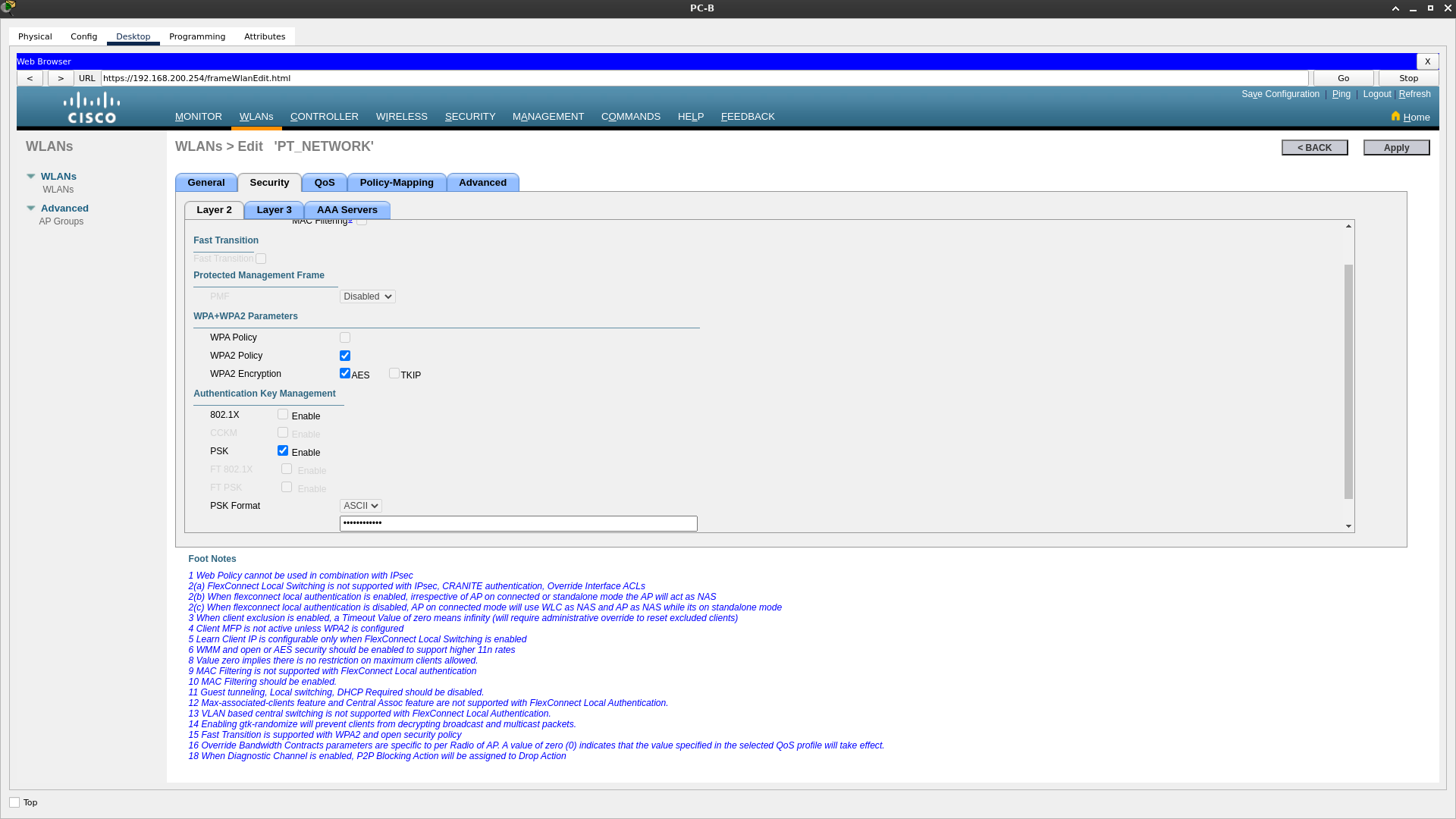
Jak możemy zobaczyć na zrzucie poniżej, punkt dostępu podłączony do przełącznika zaczyna rozsyłać tą sieć skonfigurowaną na kontrolerze.
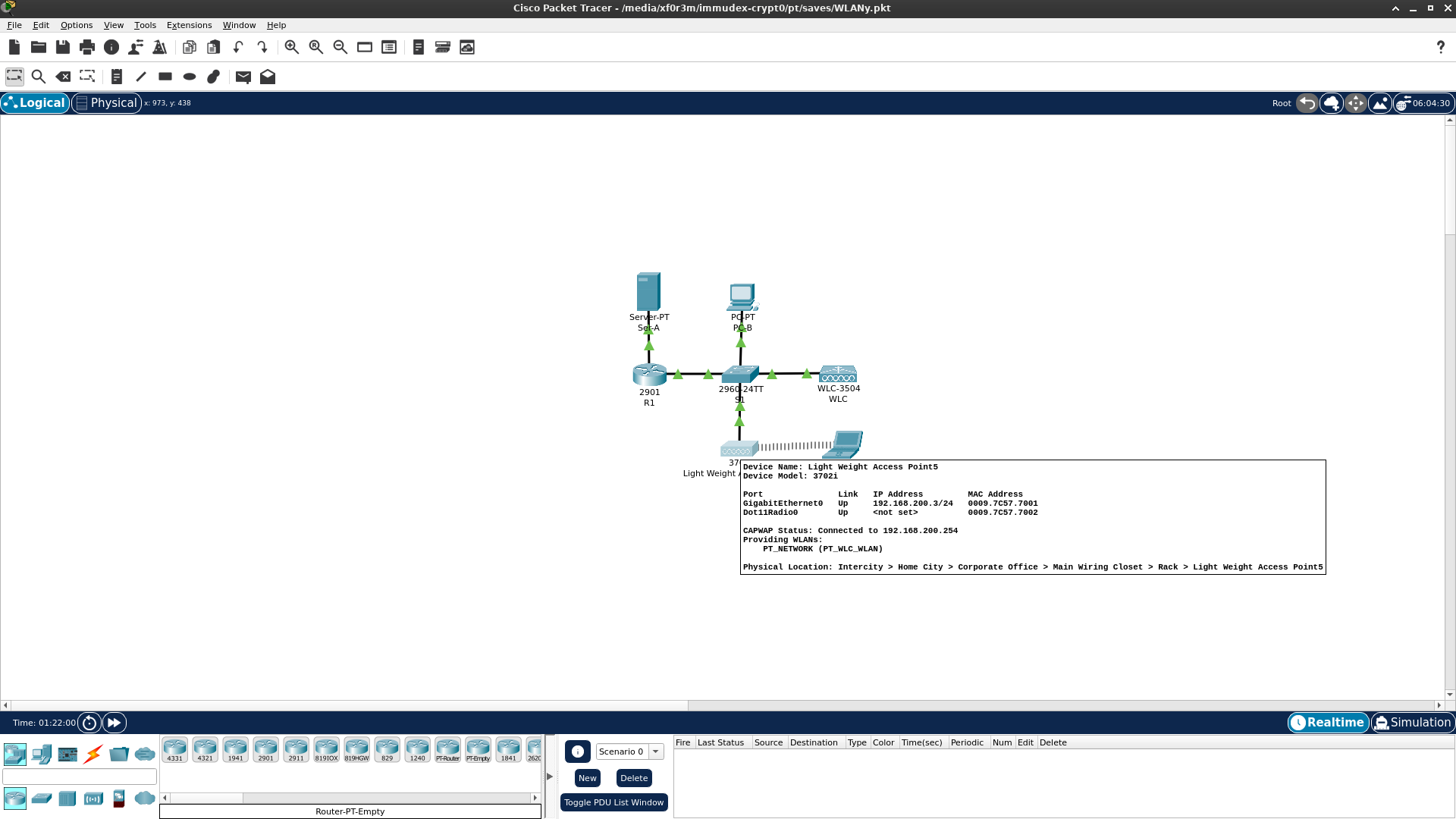
Niestety w przypadku PT, aplikacja PC Wireless działa tylko dla starszej karty. A laptop musi mieć kartę AC aby móc się z tą siecią połączyć.
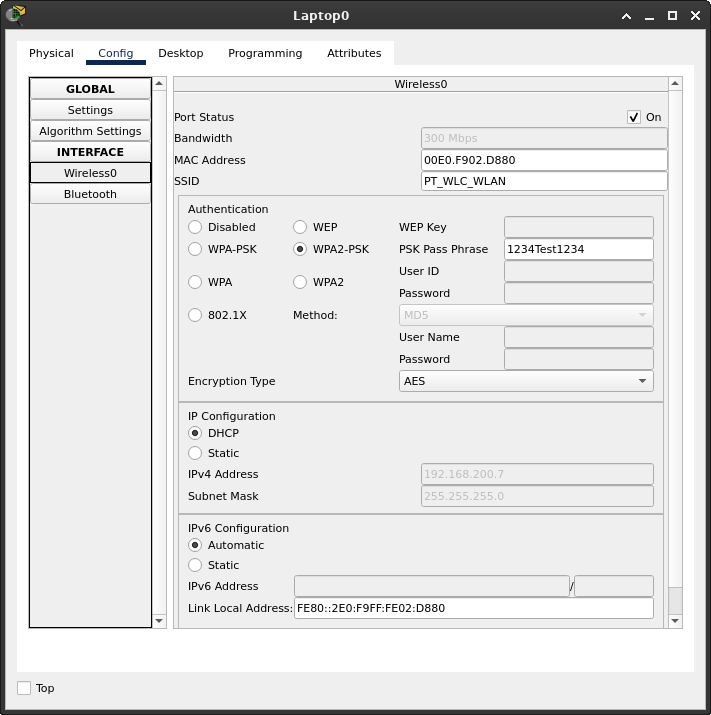
2.13.2. Konfiguracja sieci WLAN WPA2 Enterprise w sieci WLC
Chcąc stosować bezprzewodowe punkty dostępowe na firmie wypadało by rozszerzyć funkcjonalność takiej sieci o uwierzytelniania korporacyjne oparte na serwerze RADIUS oraz protokoł monitorowania sieci SNMP.
Konfiguracja SNMP na kontrolerze będzie przekazywać komunikaty
diagostyczne, zwane traps do serwera SNMP. Wskazanie
adresu serwera SNMP na WLC ma miejsce w zakładce
Management, następnie z menu po lewej
stronie rozwijamy SNMP i wybieramy
opcję Trap Receivers, następnie
klikamy przycisk New....
Dodając odbiornik komunikatów diagnostycznych (serwer SNMP), podajemy
jego nazwę (Community Name) oraz
adres IP. Zatwierdzamy zamiany,
przyciskiem Apply
Tak jak na poniższym zrzucie.
Konfigurację uwierzytelniania na bazie serwera RADIUS rozpoczynamy od
dodania serwera do konfiguracji WLC. W zakładce
Security, z menu po lewej stronie
wybieramy kolejno: AAA,
RADIUS oraz
Authentication. Nowy serwer dodajemy
poprzez kliknięcie przycisku New....
Chcąc dodać serwer RADIUS do konfiguracji WLC, podajemy adres IP serwera następnie klucz współdzielony, którym WLC będzie uwierzytelniać się wobec serwera RADIUS. Jeśli nasz serwer RADIUS działa na innym porcie, to go również należy ustawić.
Teraz pozostaje nam tylko utworzyć nową sieć WLAN, i zakładce
Security,
Layer 2, w sekcji
Authentication Key Management zamiast
PSK zaznaczamy
802.1X. Następnie w zakładce
AAA Servers, w sekcji
Radius Servers, w kolumnie
Authentication Servers, przy
Server 1 wybieramy zdefiniowany
wcześniej przez nas serwer RADIUS. Tak skonfigurowaną sieć możemy
włączyć i spróbować się z nią połączyć.
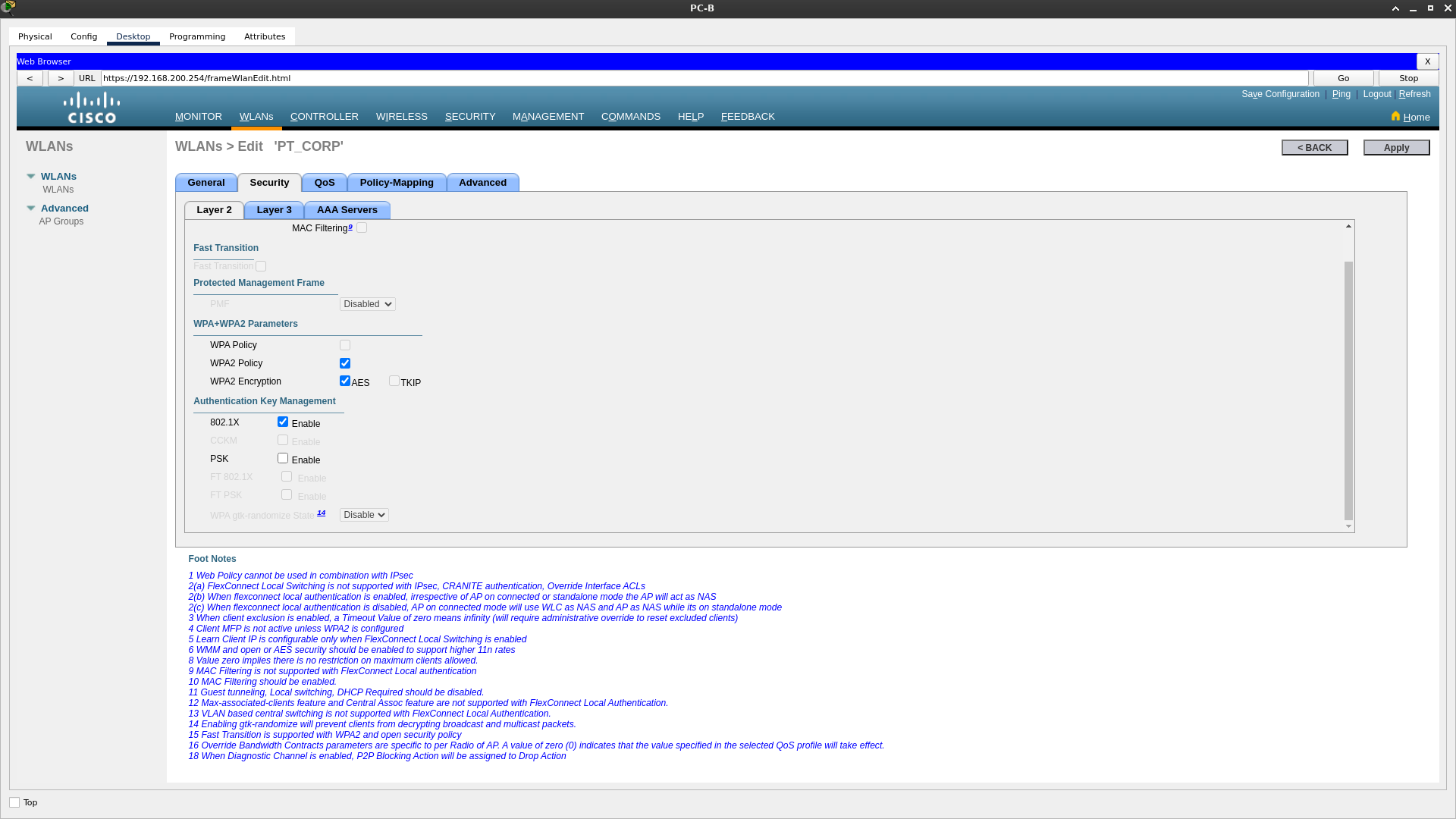
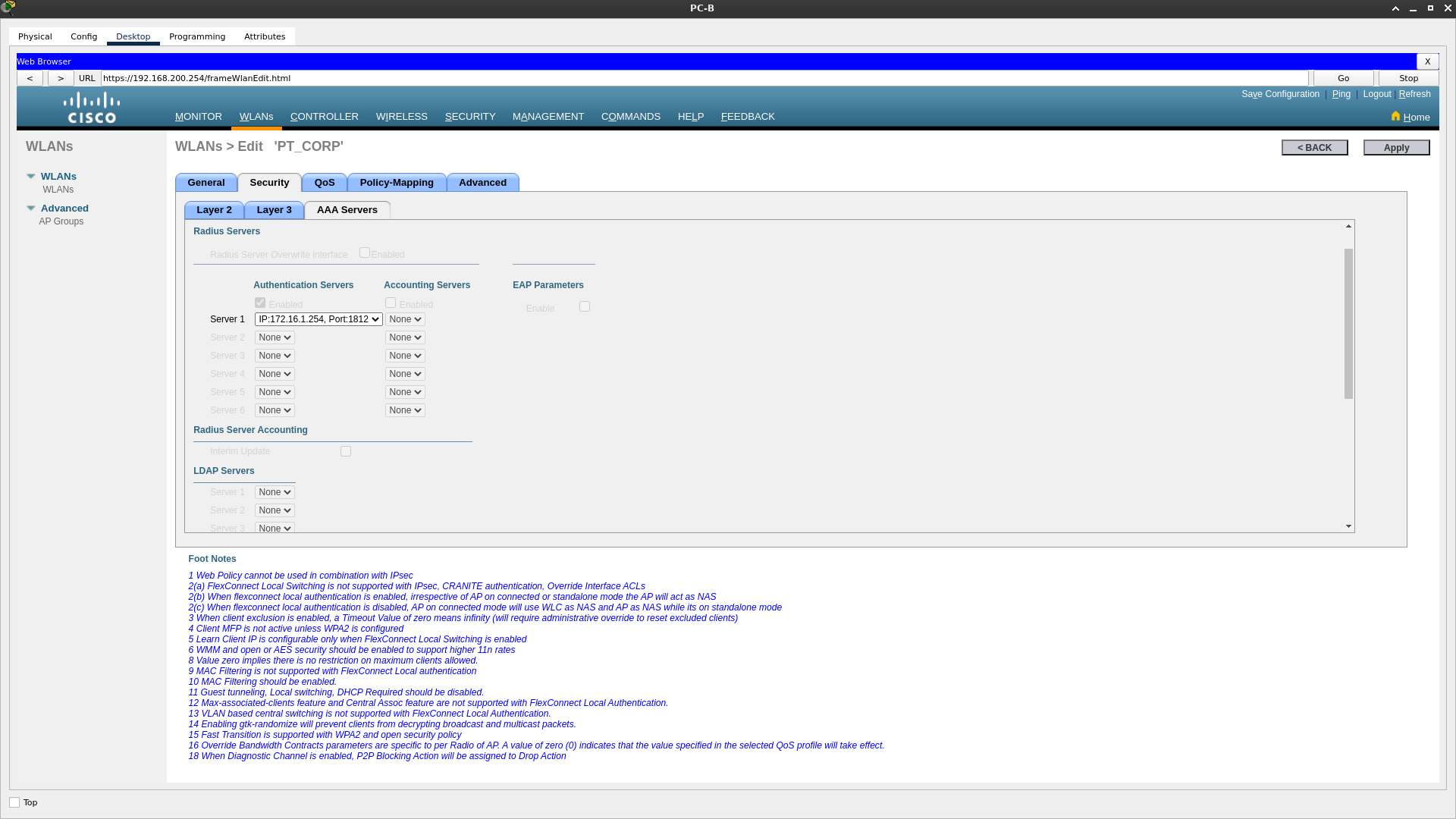
W taki sposób wygląda bowiem podłączenie do sieci WLAN z uwierzytelnianiem Enterprise.
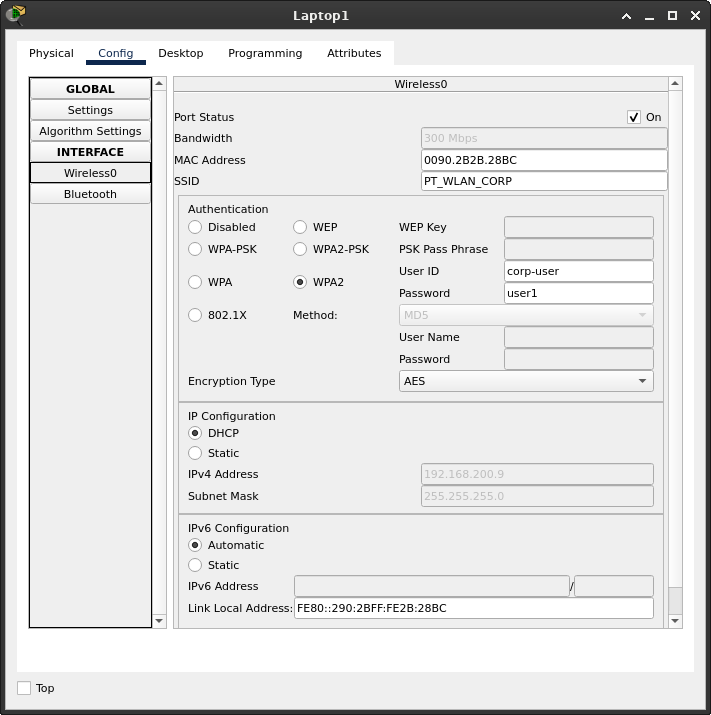
Zadanie praktyczne - Packet Tracer
Konfiguracja podstawowej sieci WLAN w WLC - scenariusz
Konfiguracja podstawowej sieci WLAN w WLC - zadanie
Konfiguracja sieci WLAN WPA2 Enterprise na WLC - scenariusz
Konfiguracja sieci WLAN WPA2 Enterprise na WLC - zadanie
2.13.3. Rozwiązaywanie problemów z siecią WLAN
Podczas administracji siecią WLAN, możemy spotkać się z problemem związanym ze skojarzeniem klienta z punktem dostępowym. Przyczyną takiego działania może być słaby zasięg, ale również ingerencja w ustawienia karty przez użytkownika. Warto również sprawdzić czy pomiędzy klientem a punktem nie ma żadnych źródeł zakłóceń. Często też przyczyną tego problemu jest źle wpisane hasło.
Jeśli nasza sieć ma słabą wydajność to wówczas można pomyśleć nad wymianą urządzęń sieciowych na wyższy standard oraz o podzieleniu i priorytetyzacji ruchu. Można wówczas wykorzystać sieci 5GHz do ruchu, który naprawdę wymaga przepustowości, taki jak streaming wideo. Resztę ruchu można pozostać na częstotliwości 2,4GHz.
Ważne są również aktualizacje oprogramowania układowego punktów dostępowych czy kontrolera. Mogą one rozszerzać funkcjonalność tych urządzeń ale wprowadzać poprawki zarówno dla wydajności jak i bezpieczeństwa samych urządzeń oraz transmisji między nimi a klientami.
Zadanie praktyczne - Packet Tracer
Rozwiązywanie problemów z siecią WLAN - scenariusz
Rozwiązywanie problemów z siecią WLAN - zadanie
Podsumowanie
W tym rodziałe dowiedzieliśmy się w jaki sposób skonfigurować sieci WLAN, oparte zarówno na autonomicznych punktach dostępowych jak tych opartych o kontroler WLC. Konfigurowaliśmy również sieci dla standard korporacyjny uwierzytelniania, na koniec poznaliśmy kilka metod rozwiązywania problemów związanych z siecia WLAN i połączeniem się z nimi.
2.14. Koncepcje routingu
Routery z założenia nie są wcale skomplikowanymi urządzeniami. Dla użytkowników małych firmy lub użytkowników domowych przygotowano specjalne urządzenia zwane routerem bezprzewodowym, który unifikuje w sobie kilka urządzeń sieciowych, takich jak: router, switch, firewall oraz punkt dostępowy. Jednak zastosowanie takich urządzeń jest mało skalowalne, dlatego też w przypadku zastosowań firmowych będziemy raczej spotykać się z osobnymi urządzeniami.
Routery mają dwa zadania:
- Określenie nalepszej scieżki do punktu docelowego dla pakietu
- Przekazanie pakietu w stronę celu
Routery przechowują informacje o tym gdzie wysłać pakiet aby trafił on do celu w tablicy routingu. Elementami, które zawierają wpisy są między innymi adres sieci docelowej, jej maska - zapisana w notacji CIDR lub przy użyciu wartości dziesiętnej adresu IP, oraz adres kolejnego skoku - interfejsu następnego routera na ścieżce prowadzącej do sieci docelowej. Router chcąc określić trasę dla pakietu, przypasowuje adres docelowy do informacji zapisanych we wpisach tabeli, dokonuje tego po przez porównanie binarnych reprezentacji adresów IP ropoczynając jest od lewej strony. Jako przykład weźmy adres 172.16.0.100, w tablicy występuje wpis 172.16.0.0/24 via 172.16.0.254, więc:
/24 = 255.255.255.0 172.16.0.100 255.255.255.0 172.16.0.0 10101100.00010000.00000000.01100100 11111111.11111111.11111111.00000000 10101100.00010000.00000000.00000000
Określenie najlepszej trasy jest jednocześnie najdłuższym dopasowaniem. Oznacza to, że router dokona wyboru trasy na podstawie długości maski sieci docelowej, więc jeśli będziemy mieć adres docelowy pasujący do wielu ścieżek, to ostatecznie zostanie wybrana ta o najdłuższej masce.
Adres docelowy = 172.16.0.100 Wpis1 = 172.16.0.0/12 Wpis2 = 172.16.0.0/16 Wpis3 = 172.16.0.0/24 Jako trasę docelową router wybierze Wpis3.
Podobnie jest w przypadku IPv6, tutaj również zostanie wybrana sieć z najdłuższym prefiksem.
2.14.1. Przekazywanie pakietów
Przekazywanie pakietów może odbyć się na trzy różne sposoby.
- Pierwszym z nich jest przekazanie pakietu do sieci bezpośrednio podłączonej do routera, jeśli trasa wskazuje na interfejs wyjściowy routera. Router musi uzyskać adres hosta docelowego, dokonuje tego za pomocą protokołu ARP lub komunikatu NS (Neighbor Solicitation) w przypadku protokołu IPv6.
- Drugim sposobem jest przekazanie pakietu do następnego skoku (pierwsze routera na trasie docelowej pakietu). Jeśli routery łączy ze sobą Ethernet, to ustalanie adresu warstwy drugiej wygląda identycznie jak w przypadku pierwszego sposobu.
- Ostatnim sposobem na przekazanie pakietu jest jego brak. Jeśli nie zostanie o dopasowany wpisów w tablicy routingu oraz w tablicy nie została zdefiniowana trasa domyśna (będzie o niej poźniej), to taki pakiet zostaje usunięty z pamięci routera.
- Przełączanie procesorowe - w tym przypadku każde nadejscie pakietu na intefejsie wejściowym jest przetwarzane przez procesor. Nie jest to wydajne rozwiązanie, ponieważ pakiety są przesyłane w postaci strumieni, w tym przypadku każdy pakiet musi zostać przez procesor przetworzony. Ten mechanizm jest nadal dostępny dla routerów Cisco.
- Szybkie przełączanie - ta metoda jest usprawnieniem przełączania procesorowego. Działa na takiej zasadzie, że pierwszy pakiet ze strumienia jest przetwarzany przez procesor, w celu znalezienia informacji o następnym skoku, jeśli nie zostanie znaleziony odpowiedni wpis w pamięci szybkiego przełączania. Pakiet zostaje skierowany do odpowiedniego interfejsu ustalonego przez procesor, następnie w pamięci szybkiego przełączania zostaje zapisana informacja o następnym skoku - jest ona stosowana dla pozostałych pakietów w strumieniu.
- Cisco Express Forwarding - najnowsza metoda stosowana domyślnie w routerach i przełącznikach wielowarstwowych firmy Cisco. Mechanizm CEF, tworzy tablicę routingu (FIB) oraz tablicę sąsiectwa. Wpisy z tej tablicy są wywoływane przez zmianę topologii, a nie w przypadku nadejscia pakietów. Po zakończeniu w sieci procesów konwergencji, pakiety są niemal natychmiast przesyłane z interfejsu wejściowego na wyjściowy.
- Skonfigurowania odpowiedniej nazwy hosta:
Router(config)#hostname R2 R2(config)#
- Ochrona trybu uprzywilejowanego EXEC przy użyciu hasła:
R2(config)#enable secret class
- Zabezpieczenie dostępu przez konsole:
R1(config)#line console 0 R1(config-line)#logging synchronous R1(config-line)#password cisco R1(config-line)#login R1(config-line)#exit
- Umożliwienie zdalnego dostępu przez konsole:
R1(config)#line vty 0 4 R1(config-line)#password cisco R1(config-line)#login R1(config-line)#transport input ssh R1(config-line)#exit
- Ustawienie szyfrowania haseł:
R1(config)#service password-encryption
- Ustawienie wiadomości powitalnej/ostrzeżenia:
R1(config)#banner motd # Enter TEXT message. End with the character '#'. WARNING: Unauthorized access is prohibited! #
- Włączenie routingu IPv6:
R1(config)#ipv6 unicast-routing
- Konfiguracja interfejsów:
R1(config)#int gig0/0 R1(config-if)#desc Link to S1 R1(config-if)#ip addr 192.168.0.1 255.255.255.0 R1(config-if)#ipv6 addr 2001:db8:acad:0::1/64 R1(config-if)#ipv6 addr fe80::0:1 link-local R1(config-if)#no shutdown
- Zapis konfiguracji bierzącej do konfiguracji startowej:
R1#copy running-config startup-config Destination filename [startup-config]? Building configuration... [OK]
show ip interface brief:R1#show ip int br Interface IP-Address OK? Method Status Protocol GigabitEthernet0/0 192.168.0.1 YES manual up down GigabitEthernet0/1 unassigned YES unset administratively down down Vlan1 unassigned YES unset administratively down down
show running-config:R1#sh running-config Building configuration... Current configuration : 887 bytes ! version 15.1 no service timestamps log datetime msec no service timestamps debug datetime msec service password-encryption ! hostname R1 ...
show interfaces:R1#sh interfaces GigabitEthernet0/0 is up, line protocol is down (disabled) Hardware is CN Gigabit Ethernet, address is 0001.9731.1701 (bia 0001.9731.1701) Description: Link to S1 Internet address is 192.168.0.1/24 MTU 1500 bytes, BW 1000000 Kbit, DLY 10 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, loopback not set Keepalive set (10 sec) Full-duplex, 100Mb/s, media type is RJ45 output flow-control is unsupported, input flow-control is unsupported ARP type: ARPA, ARP Timeout 04:00:00, Last input 00:00:08, output 00:00:05, output hang never Last clearing of "show interface" counters never Input queue: 0/75/0 (size/max/drops); Total output drops: 0 Queueing strategy: fifo Output queue :0/40 (size/max) 5 minute input rate 0 bits/sec, 0 packets/sec 5 minute output rate 0 bits/sec, 0 packets/sec 0 packets input, 0 bytes, 0 no buffer Received 0 broadcasts, 0 runts, 0 giants, 0 throttles 0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort 0 watchdog, 1017 multicast, 0 pause input ...show ip interface:R1#show ip interface GigabitEthernet0/0 is up, line protocol is down (disabled) Internet address is 192.168.0.1/24 Broadcast address is 255.255.255.255 Address determined by setup command MTU is 1500 bytes Helper address is not set Directed broadcast forwarding is disabled Outgoing access list is not set Inbound access list is not set Proxy ARP is enabled Security level is default Split horizon is enabled ICMP redirects are always sent ICMP unreachables are always sent ICMP mask replies are never sent IP fast switching is disabled IP fast switching on the same interface is disabled IP Flow switching is disabled IP Fast switching turbo vector IP multicast fast switching is disabled IP multicast distributed fast switching is disabled Router Discovery is disabled ...
show ip route:R1#show ip route Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area * - candidate default, U - per-user static route, o - ODR P - periodic downloaded static route Gateway of last resort is not set 192.168.0.0/24 is variably subnetted, 2 subnets, 2 masks C 192.168.0.0/24 is directly connected, GigabitEthernet0/0 L 192.168.0.1/32 is directly connected, GigabitEthernet0/0ping:R1#ping 192.168.0.100 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.0.100, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 0/8/43 ms
- Sieci bezpośrednio podłączone
- Trasy statyczne
- Protokoły routingu dynamicznego
- Każdy router podejmuje decyzje samodzielnie na podstawie swojej tablicy routingu.
- Informacje w tabeli routingu jednego routera niekoniecznie pasują do tabeli routingu innego routera.
- Informacje o routingu ścieżki nie zapewniają informacji o routingu zwrotnym.
Mamy również dostępne trzy różne mechanizmy na zrealizowanie powyższych celów:
2.14.2. Podstawowa konfiguracja routera
Aby móc definiować trasy na routerach, musimy na początku dokonać bezpieczenej i podstawowej konfiguracji. Zatem musimy wykonać takie czynności jak
W ten sposób wygląda najprostsza konfiguracja routera, jaką należało by przeprowadzić, oczywiście konfigurację interfejsów powtarzamy dla wszystkich uwzględnionych w topologii. Taką konfigurację możemy weryfikować przy pomocy poleceń show.
Wyjścia poleceń show running-config,
show interfaces czy
show ip interfaces można przepuścić
przez znak potoku (|) oraz polecenia filtrujące
(begin, section, include, exclude).
Zadanie praktyczne - Packet Tracer
Przegląd podstawowej konfiguracji routera - scenariusz
Przegląd podstawowej konfiguracji routera - zadanie
2.14.3. Tablica routingu
Tablica routingu jest tabelą w pamięci routera. Na podstawie wpisów w tej tabeli urządzenie dokonuje decyzji gdzie przesłać otrzymany pakiet. Źródłem tych wpisów mogą być:
Istnieją trzy zasady związane z tablicami routingu. Zasady te, a konkretniej problemy można rozwiązać poprzez stosowanie dynamicznych protokołów routingu, czy tras statycznych na wszystkich urządzeniach między nadawcą a odbiorcą:
Same wpisy w tablicy routingu mają określony format, składają się z około 7 pól, w przypadku IPv6 tych pól jest 6. Pole numer 3 zawiera dwa pola - dystans administracyjcny oraz metrykę.:
#IPv4: O 10.0.4.0/24 [110/50] via 10.0.3.2, 00:13:29, Serial0/1/1 #IPv6: O 2001:DB8:ACAD:4::/64 [110/50] via FE80::2:C, Serial0/1/1
- Źródło trasy - na podstawie tej kolumny możemy
określić skąd pochodzi dana trasa. Legenda opisująca poszczególne
skróty znajduje się na początku wyjścia polecenia
show ip route. Najczęściej zawiera ona informacje o tym czy jest trasa jest statyczna lub nauczona przy użyciu protokołu routingu. - Adres sieci docelowej - Identyfikuje sieć zdalną. Ten adres zawsze podawany jest wraz prefiksem (dla IPv4) lub długością prefiksu (dla IPv6).
- Odległość administracyjna - z góry narzucona wartość, możliwa do zmiany. Określa ona wiarygodność danej trasy. Im niższy dystans administracyjny tym trasa będzie bardziej preferowana przez urządzenia.
- Metryka - Indywidualna wartość określającą dostęp do sieci zdalnej oblicza przez algorytmy protokołów routingu dynamicznego. Im niższa wartość tym trasa bardziej preferowana przez router.
- Następny przeskok - Identyfikuje adres IP routera, do którego pakiet został by przesłany.
- Znacznik czasu - nie występuje w IPv6, określa ile czasu upłynęło od nauczenia się trasy.
- Interfejs wyjściowy - określa interfejs przez, który osiągalna jest sieć zdalna dla pakietów.
Tablica routingu typowego routera wypełnia się zazwyczaj na początku trasami bezpośrednio podłączonymi, ponieważ są one dodawane zaraz po podłączeniu drugiej strony medium o ile włączyliśmy dany interfejs. Trasy bezpośrednio podłączonę zawierają literkę C w pierwszej kolumnie. Tym trasom toważyszą dodatkowe wpisy w postaci tras lokalnych, trasa lokalna zawiera w adresie sieci, adres IP interfejsu routera podłączony do tej sieci bezpośredniej, takie trasy określa się literą L. Trasa tego typu ma za zadanie w lepszy sposób rozgraniczać ruch przeznaczony dla routera od tego, który ma zostać przezkazny dalej do sieci.
Następnie tablica może zostać wypełniona ręcznie przez administratora, trasami statycznymi, są to jawne ścieżki między dwoma urządzeniami. Takie trasy muszą być ręcznie zmieniane po każdej zmienie topologii. Zaletą stosowania tras statycznych jest zwiększone bezpieczeństwo - to administrator decyduje o tym gdzie zostanie skierowany pakiet - oraz zmniejszone zużycie zasobów, ze względu na brak zaangażowania urządzenia w wymiane informacji o trasach w protokołach dynamicznych. Do zastosowań tras statycznych możemy przypisać:
- Zapewnia łatwości obsługi tablic routingu w mniejszych sieciach w przypadku gdy nieoczekuje się nagłego wzrostu rozmiarów sieci.
- Używa pojedynczej trasy domyślnej do reprezentowania ścieżki do dowolnej sieci, która nie ma dopasowania z dokładniejszą trasą w tablicy routingu. Trasy domyślne są używane gdy router nie znajduje dla danej sieci docelowej pasującej pozycji w tabeli routingu.
- Kieruje z i do sieci pośredniczących. Sieć szczątkowa to sieć, do której można dotrzeć tylko jedną trasą.
Trasy statyczne są definiowane w IOS za pomocą polecenia:
ip route wydanego w trybie
konfiguracji globalnej. Dla tras IPv4, dla IPv6 polecenie
różni się tylko: ipv6 route
#IPv4: Router(config)#ip route 10.0.4.0 255.255.255.0 10.0.3.2 #IPv6: Router(config)# ipv6 route 2001:db8:acad:4::/64 fe80::2:c
Protokoły routingu dynamicznego są używane przez routery do automatycznego udostępania informacji na temat stanu oraz osiągalności zdalnych sieci. Protokoły routingu wykonują wiele zadań związanych z wykrywaniem sieci oraz utrzymywaniem tablic routingu. Ważnymi zaletami protokołów routingu dynamicznego jest możliwość wyboru najlepszej ścieżki oraz odkrycia nowej najlepszej ścieżki w momencie zmiany topologii. Te mechanizmy opierają się na tym, że routery same mogą rozgłaszać informacje o znanych sobie sieciach dla innych urządzeń wykorzystujących ten sam protokół.
W tablicy routingu trasę dynamiczną poznamy po tym, że jej źródłem będzie jeden z protokołów dynamicznych, dystans administracyjny będzie inny większy niż 1 oraz metryka większą niż 0. W przypadku IPv4, wświetlany będzie również dodatkowo znacznik czasu, który określe ile czasu upłyneło od nauczenia się trasy.
Ostatnim rodzajem trasy jest trasa domyślna, jest ona podobna do bramy. Określa ona adres routera następnego skoku dla pakietów, których adres docelowy nie może zostać przypasowany do żadnej trasy zapisanej w tablicy. Trasa do tej sieci może nieistnieć w tabeli. Trasy domyślne ma zapisany adres sieci docelowe w postaci: 0.0.0.0/0 - dla IPv4 oraz ::/0 - dla IPv6. Adres następnego skoku w przypadku trasy domyślnej najczęściej będzie wskazywać adres bramy naszego usługodawcy internetowego.
Jeśli przyjrzelibyśmy się tablicy routingu, która posiada jakieś zdefiniowane trasy zarówno bezpośrednio podłączone, statyczne jak i dynamiczne, to możemy zauważyć pewnego rodzaju wcięcia. Te wpisy z wcięciami oznaczają trasy podrzędne, a te bez żadnych odstępów trasy nadrzędne, wynika to podziału sieci na mniejsze framenty - na podsieci. Oczywiście jak pamiętamy router dokounuje najdłuższego dopasowania. Ten podział ma jedynie funkcję organizacyjną w tablicy routingu. W przypadku IPv6 ten podział w ogóle nie występuje, gdyż nie wystęują w adresacji tego typu klasy.
Trzecim polem wpisu w tablicy routingu jest dystans administracyjny. Jest to domyślnie przypisana wartość wiarygodności tras zapisywanych w tabeli routingu. Te wartości są zapisane w systemie operacyjnym routera. Użycie odległości administracyjne było podyktowane, tym że tablice routingu mogą być wypełniane na różny sposób przez różne protokoły - tak, możliwe jest uruchomienie kilku protokołów routingu dynamicznego jednocześnie na jednym urządzeniu, choć nie koniecznie jest dobre rozwiązanie. Zatem może spotkać się z takimi wartościami AD (Administrative Distance) dla poszególnych źródeł tras routingu.
- Bezpośrednio podłączona - 0.
- Trasa statyczna - 1.
- Sumaryczna trasa EIGRP - 5.
- Zewnętrzna trasa BGP - 20.
- Wewnętrzna trasa EIGRP - 90.
- OSPF - 110.
- IS-IS - 115.
- RIP - 120.
- Zewnętrzna trasa EIGRP - 170.
- Wewnętrzna trasa BGP - 200.
Te wartości mogą być przez nas zmieniane. Przy czym wartość AD 0 może mieć jedynie sieć bezpośrednio podłączona.
2.14.4. Statyczny czy dynamiczny?
Routing statyczny i dynamiczne protokoły routingu nie wykluczają siebie nawzajem. Najczęście spotykaną konfiguracją jest użycie jednego z protokółów routingu dynamicznego (OSPF lub EIGRP) oraz uzupełnienie tablicy o trasy statyczne. Trasy statyczne sprawdzą się takich przypadkach jak:
- Domyślna trasa przekazywania pakietów do usługodawcy.
- W przypadku tras poza domeną routingu i niewykonywanych przez protokoły dynamiczne.
- Gdy chcemy jawnie zdefiniować trasę do określonej sieci.
- Do routingu między sieciami szczątkowymi.
Natomiast protokoły dynamiczne sprawdzą się takich scenariuszach jak:
- W sieciach składających się z więcej niż kilku routerów.
- Gdy zmiana topologii wymaga od sieci automatycznego określania innej ścieżki.
- Dla skalowalności. Wraz z rozwojem sieci dynamiczny protokół routingu automatycznie uczy się o wszelkich nowych sieciach.
Obecne protokoły routingu dynamicznego, dostosowywały się do zmieniających się trendów oraz standardów sieciowych, jednak od dłuższego czasu na tym polu nie wiele się dzieje. Obecnie wykorzystujemy metody i technologie opracowane ponad 25 lat temu. Rowiązania te są na tyle dobre i upowszechnione, że nie wiadomo czy jeszcze coś się zmienii na tej płaszczyźnie.
Same protokoły dzielą się na dwie grupy IGP - bramy wewnętrznej, w której znajduję się większość protokołów oraz EGP - bramy zewnętrznej, w której znajduje się tylko protokół BGP.
Celem protokołów routingu dynamicznego jest dynamiczne określenie najlepszej trasy dla pakietów przy zmieniającej się topologii sieci. Głównymi składnikami takich protokołów jest struktura danych zawierająca informacje o sieciach, zestawy komunikatów protokołu, aby urządzenia mogły informować siebie na wzajem o podłączonych do nich sieciach oraz o zmieniającej się topologii sieci. Ostatnim składnikiem jest algorytm protokołu pozwalających na określenie najlepszej ścieżki.
Zanim ścieżka zostanie zapisana do tablicy routingu musi zostać ustalona poprzez algorytmy jakie stosują dynamiczne protokoły. Wynik działania tych algorytmów zapisywany jest w postaci metryki we wpisie w tabeli. Poniżej wymieniono ważniejsze protokoły IGP, oraz ich metody na określenie metryki.
- Protokół RIP (Routing Information Protocol) - Metryka to liczba przeskoków - kolejnych routerów na trasie. Maksymalnie może ich być 15.
- Protokół OSPF (Open Shortest Path First) - Metryką jest "koszt" skumulowanej przepustowści od źródła do celu. Szybszym łączom przypisuje się niższe koszta w porównaniu wolnieszymi (droższymi) łączami.
- EIGRP (Enchanced Interior Gateway Protocol) - Oblicza metrykę na podstawie najwolniejszej przepustowości oraz wartości opóźnienia, ale może również uwzględniać obiążenie i niezawodność.
Dużą zaletą protokołu EIGRP jest równoważenie obciążenia, jeśli trasy mają identyczną metrykę, to protokół może zdecydować aby część strumienia pakietów puscić jedną trasą, a część drugą. Do celu dotrą w tym samym czasie. Tak mówi o tym teoria.
Podsumowanie
W tym rozdziale zapoznaliśmy się sposobami trasowania pakietów z jednej sieci do drugiej. Poznaliśmy jakie funkcje ma router oraz na jakie podstawie dokonuje on wyboru trasy. Dowiedzieliśmy się w jaki sposób router przekazuje pakiety. Przypomnieliśmy sobie podstawową konfigurację routera. Zapoznaliśmy się z trasami statycznymi, trasą domyślną oraz dynamicznymi protokołami routingu. Na koniec dowiedzieliśmy się jak wygląda trasowanie w praktyce oraz krótko opisaliśmy sobie wewnętrzne protokoły routingu - w jaki sposób wybierają trasę.
2.15. Statyczny routing IP
W poprzednim rodziale poznaliśmy polecenie za pomocą, które możemy dodać trasy statyczne IP do tablicy routingu, ale to nie jest wszystko. Samych tras statyczny mogą być cztery rodzaje:
- Standardowa trasa statyczna
- Domyślna trasa statyczna
- Pływająca trasa statyczna
- Sumaryczna trasa statyczna
W trasach statycznych jednym z parametrów potrzebnych do jej utworzenia jest podanie następnego skoku i to w jaki sposób podamy ten parametr, a możemy na trzy sposoby definiujej kolejne typy tras statycznych.
- Trasa następnego przeskoku - określono tylko adres IP następnego skoku.
- Bezpośrednio podłączona trasa statyczna - określono tylko interfejs wyjściowy routera.
- W pełni określona trasa statyczna - podano adres IP następnego skoku oraz interfejs wyjściowy.
Polecenie ip route, odpowiedzialne za
dodawanie tras statycznych do tablicy routingu w raz argumentami
wygląda następująco:
Router(config)#ip route network-address subnet-mask { ip-address | exit-intf [ip-address] } [distance]
network-address- adres IP sieci docelowej.subnet-mask- maska podsieci sieci docelowej. Maskę można modyfikować aby podsumować grupę sieci i utworzyć sumaryczną tras statyczną.ip-address- adres IP następnego na trasie routera, następnego skoku. Pozwala utworzyć rekurencyjną trasę statyczną, w której router dokonuje jeszcze jednego wyszukiwania w celu znalezienia interfejsu wyjściowego.exit-intf- interfejs wyjściowy, tworzy bezpośrednio podłączoną trasę statyczną.exit-intf ip-address- interfejs wyściowy wraz z adresem kolejnego skoku. Użycie tych dwóch argumentów powoduje utworzenie w pełni określonej trasy statycznej.distance- Opcjonalny argument może przyjmować wartości od 1 do 255. Wykorzystywany przy pływających trasach statycznych do ustawienia odległości administracyjnej większej niż przy trasach dodanych przez protokoły dynamiczne.
Dla IPv6 wyżej wymienione polecenie wygląda następująco:
Router(config)#ipv6 route prefix/prefix-length { ipv6-address | exit-intf [ipv6-address] } [distance]
prefix- identyfikuje docelowy adres sieciowy IPv6.prefix-length- określa długość prefiksu sieci zdalnej.ip-address- adres IP następnego na trasie routera, następnego skoku. Pozwala utworzyć rekurencyjną trasę statyczną, w której router dokonuje jeszcze jednego wyszukiwania w celu znalezienia interfejsu wyjściowego.exit-intf- interfejs wyjściowy, tworzy bezpośrednio podłączoną trase statyczną.exit-intf ip-address- interfejs wyściowy wraz z adresem kolejnego skoku. Użycie tych dwóch argumentów powoduje utworzenie w pełni określonej trasy statycznej.distance- Opcjonalny argument może przyjmować wartości od 1 do 255. Wykorzystywany przy pływających trasach statycznych do ustawienia odległości administracyjnej większej niż przy trasach dodanych przez protokoły dynamiczne.
W celu dalszego omawiania konfiguracji sieci statycznych, stworzyłem w Packet Tracerze taką o to topologię.
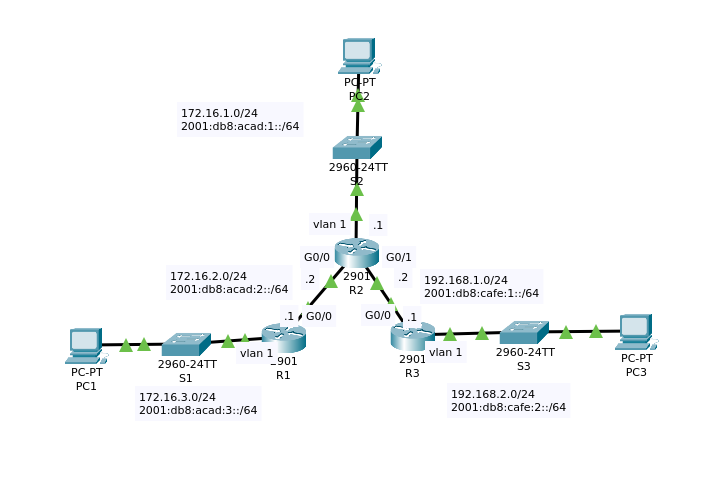
Po skonfigurowaniu adresów w tablicy routingu nie ma żadnych wpisów poza trasami bezpośrednio podłączonymi oraz lokalnymi. Poniżej znajduje się zrzut tablicy z routera R2.
R2#show ip route
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 4 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Vlan1
L 172.16.1.1/32 is directly connected, Vlan1
C 172.16.2.0/24 is directly connected, GigabitEthernet0/0
L 172.16.2.2/32 is directly connected, GigabitEthernet0/0
192.168.1.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.1.0/24 is directly connected, GigabitEthernet0/1
L 192.168.1.2/32 is directly connected, GigabitEthernet0/1
R2#show ipv6 route
IPv6 Routing Table - 7 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
C 2001:DB8:ACAD:1::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:1::1/128 [0/0]
via Vlan1, receive
C 2001:DB8:ACAD:2::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:2::2/128 [0/0]
via GigabitEthernet0/0, receive
C 2001:DB8:CAFE:1::/64 [0/0]
via GigabitEthernet0/1, directly connected
L 2001:DB8:CAFE:1::2/128 [0/0]
via GigabitEthernet0/1, receive
L FF00::/8 [0/0]
via Null0, receive
W celu powtórzenia poleceń z poprzedniego rozdziału możemy sobie sprawdzić zarówno tablice routingu poszczególnych routerów jak i spróbować spingować komputery między sobą. Pamiętajmy aby nadać adresy IP komputerom przed wydaniem polecenia ping.
2.15.1. Konfigurowanie tras statycznych IP
Jeśli wykonaliśmy sprawdzenie łączności między komputerami to wiemy się one niepowiodły, aby mógł zajść routing między tymi sieciami musimy w najgorszym przypadku skonfigurować trasy statyczne na każdym z routerów wskazując pokolei adresy następnego skoku przez, które osiągalne są następujące sieci. Tak wyglądają polecenia wpisane na poszczególnych routerach.
#R1: R1(config)#ip route 172.16.1.0 255.255.255.0 172.16.2.2 R1(config)#ip route 192.168.2.0 255.255.255.0 172.16.2.2 R1(config)#ipv6 route 2001:db8:acad:1::/64 2001:db8:acad:2::2 R1(config)#ipv6 route 2001:db8:cafe:2::/64 2001:db8:acad:2::2 #R2: R2(config)#ip route 172.16.3.0 255.255.255.0 172.16.2.1 R2(config)#ip route 192.168.2.0 255.255.255.0 192.168.1.1 R2(config)#ipv6 route 2001:db8:acad:3::/64 2001:db8:acad:2::1 R2(config)#ipv6 route 2001:db8:cafe:2::/64 2001:db8:cafe:1::1 #R3: R3(config)#ip route 172.16.1.0 255.255.255.0 192.168.1.2 R3(config)#ip route 172.16.3.0 255.255.255.0 192.168.1.2 R3(config)#ipv6 route 2001:db8:acad:1::/64 2001:db8:cafe:1::2 R3(config)#ipv6 route 2001:db8:acad:3::/64 2001:db8:cafe:1::2
Teraz polecenie ping pomiędzy wszystkimi komputerami powinno się udać. Warto zwrócić uwagę na to, że R1 nie musi mieć trasy do sieci między R2 a R3 i vice versa. R3 nie musi mieć trasy do sieci między R2 a R1, żeby komputery mogły się ze sobą komunikować. W ten sposób stworzyliśmy trasy następnego skoku. Tablice routingu routera R2 prezentują się w następujący sposób:
R2#show ip route | begin Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 5 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Vlan1
L 172.16.1.1/32 is directly connected, Vlan1
C 172.16.2.0/24 is directly connected, GigabitEthernet0/0
L 172.16.2.2/32 is directly connected, GigabitEthernet0/0
S 172.16.3.0/24 [1/0] via 172.16.2.1
192.168.1.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.1.0/24 is directly connected, GigabitEthernet0/1
L 192.168.1.2/32 is directly connected, GigabitEthernet0/1
S 192.168.2.0/24 [1/0] via 192.168.1.1
R2#show ipv6 route
IPv6 Routing Table - 9 entries
...
C 2001:DB8:ACAD:1::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:1::1/128 [0/0]
via Vlan1, receive
C 2001:DB8:ACAD:2::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:2::2/128 [0/0]
via GigabitEthernet0/0, receive
S 2001:DB8:ACAD:3::/64 [1/0]
via 2001:DB8:ACAD:2::1
C 2001:DB8:CAFE:1::/64 [0/0]
via GigabitEthernet0/1, directly connected
L 2001:DB8:CAFE:1::2/128 [0/0]
via GigabitEthernet0/1, receive
S 2001:DB8:CAFE:2::/64 [1/0]
via 2001:DB8:CAFE:1::1
L FF00::/8 [0/0]
via Null0, receive
Następnym rodzajem tras statycznych są trasy bezpośrednio podłączone. Konfigurując naszą topologię, zamiast adresu następnego skoku, podajemy interfejs wyjściowy, w moim przypadku będzie Gig0/0 oraz Gig0/1 (w przypadku R2).
#R1:
R1(config)#ip route 172.16.1.0 255.255.255.0 gig0/0
%Default route without gateway, if not a point-to-point interface, may impact performance
R1(config)#ip route 192.168.2.0 255.255.255.0 gig0/0
%Default route without gateway, if not a point-to-point interface, may impact performance
R1(config)#ipv6 route 2001:db8:acad:1::/64 gig0/0
R1(config)#ipv6 route 2001:db8:cafe:2::/64 gig0/0
#R2:
R2(config)#ip route 172.16.3.0 255.255.255.0 gig0/0
%Default route without gateway, if not a point-to-point interface, may impact performance
R2(config)#ip route 192.168.2.0 255.255.255.0 gig0/1
%Default route without gateway, if not a point-to-point interface, may impact performance
R2(config)#ipv6 route 2001:db8:acad:3::/64 gig0/0
R2(config)#ipv6 route 2001:db8:cafe:2::/64 gig0/1
#R3:
R3(config)#ip route 172.16.1.0 255.255.255.0 gig0/0
%Default route without gateway, if not a point-to-point interface, may impact performance
R3(config)#ip route 172.16.3.0 255.255.255.0 gig0/0
%Default route without gateway, if not a point-to-point interface, may impact performance
R3(config)#ipv6 route 2001:db8:acad:1::/64 gig0/0
R3(config)#ipv6 route 2001:db8:acad:3::/64 gig0/0
R2#show ip route | begin Gateway
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 5 subnets, 2 masks
C 172.16.1.0/24 is directly connected, Vlan1
L 172.16.1.1/32 is directly connected, Vlan1
C 172.16.2.0/24 is directly connected, GigabitEthernet0/0
L 172.16.2.2/32 is directly connected, GigabitEthernet0/0
S 172.16.3.0/24 is directly connected, GigabitEthernet0/0
192.168.1.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.1.0/24 is directly connected, GigabitEthernet0/1
L 192.168.1.2/32 is directly connected, GigabitEthernet0/1
S 192.168.2.0/24 is directly connected, GigabitEthernet0/1
R2#show ipv6 route
IPv6 Routing Table - 9 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
C 2001:DB8:ACAD:1::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:1::1/128 [0/0]
via Vlan1, receive
C 2001:DB8:ACAD:2::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:2::2/128 [0/0]
via GigabitEthernet0/0, receive
S 2001:DB8:ACAD:3::/64 [1/0]
via GigabitEthernet0/0, directly connected
C 2001:DB8:CAFE:1::/64 [0/0]
via GigabitEthernet0/1, directly connected
L 2001:DB8:CAFE:1::2/128 [0/0]
via GigabitEthernet0/1, receive
S 2001:DB8:CAFE:2::/64 [1/0]
via GigabitEthernet0/1, directly connected
L FF00::/8 [0/0]
via Null0, receive
Tego rodzaju trasy są przeznaczone dla połączeń szeregowych punkt-punkt
o czym informuje nas IOS podczas dodawania takiej trasy IPv4.
Trasy IPv4 działają, i komunikacja z dość widocznym opoźnieniem
dochodzi do skutku, natomiast w przypadku IPv6 próby pingowania się
komputerów nawzajem nie dochodzi do skutku. Teraz mimo że dwie trasy
zostały dodane statyczne, to wyświetlane jest tablicy
directly connected.
W pełni określona trasa statyczna wymaga podania zarówno interfejsu wyjściowego jak i adresu IP następnego skoku. Ta forma trasy statycznej jest stosowana w interfejsie wielodostępowym, takim jak np. Ethernet. W połączeniach punkt-punkt, na drugim końcu łącza może znajdować się tylko router, w przypadku łączy wielodostępowych między jednym a drugim routerem może znaleźć się wiele urządzeń. Interfejs następnego przeskoku musi być podłączony bezpośrednio do konkretnego.
W przypadku oprogramowania Packet Tracer nie jest możliwe
skonfigurowanie w pełni określonych tras statycznych dla IPv4, program
pozwala użyć w poleceniu ip route
albo nazwy interfejsu tworząc trasę bezpośrednio podłączoną, albo adres
IP następnego przeskoku. Jednak w przypadku IPv6 można już dodać
trasę w pełni określoną. Aby było to możliwe do zrealizowania
uzupełniłem konfigurację routerów o adresy IPv6 link-local.
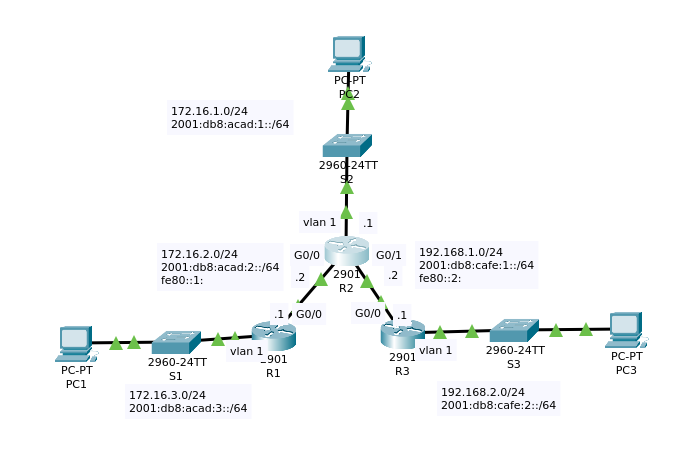
#R1:
R1(config)#ipv6 route 2001:db8:acad:1::/64 gig0/0 fe80::1:2
R1(config)#ipv6 route 2001:db8:cafe:2::/64 gig0/0 fe80::1:2
#R2:
R2(config)#ipv6 route 2001:db8:acad:3::/64 gig0/0 fe80::1:1
R2(config)#ipv6 route 2001:db8:cafe:2::/64 gig0/1 fe80::2:1
#R3:
R3(config)#ipv6 route 2001:db8:acad:1::/64 gig0/0 fe80::2:2
R3(config)#ipv6 route 2001:db8:acad:3::/64 gig0/0 fe80::2:2
R2#show ipv6 route
IPv6 Routing Table - 9 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
C 2001:DB8:ACAD:1::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:1::1/128 [0/0]
via Vlan1, receive
C 2001:DB8:ACAD:2::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:2::2/128 [0/0]
via GigabitEthernet0/0, receive
S 2001:DB8:ACAD:3::/64 [1/0]
via FE80::1:1, GigabitEthernet0/0
C 2001:DB8:CAFE:1::/64 [0/0]
via GigabitEthernet0/1, directly connected
L 2001:DB8:CAFE:1::2/128 [0/0]
via GigabitEthernet0/1, receive
S 2001:DB8:CAFE:2::/64 [1/0]
via FE80::2:1, GigabitEthernet0/1
L FF00::/8 [0/0]
via Null0, receive
Po dodaniu wszystkich tras, możliwa jest komunikacja między komputerami w różnych sieciach. Dodane trasy statyczne możemy weryfikować za pomocą poleceń:
show ip routeishow ipv6 route:R2#show ip route Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area * - candidate default, U - per-user static route, o - ODR P - periodic downloaded static route Gateway of last resort is not set 172.16.0.0/16 is variably subnetted, 4 subnets, 2 masks C 172.16.1.0/24 is directly connected, Vlan1 L 172.16.1.1/32 is directly connected, Vlan1 C 172.16.2.0/24 is directly connected, GigabitEthernet0/0 L 172.16.2.2/32 is directly connected, GigabitEthernet0/0 192.168.1.0/24 is variably subnetted, 2 subnets, 2 masks C 192.168.1.0/24 is directly connected, GigabitEthernet0/1 L 192.168.1.2/32 is directly connected, GigabitEthernet0/1 R2#show ipv6 route IPv6 Routing Table - 9 entries Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP U - Per-user Static route, M - MIPv6 I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2 ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2 D - EIGRP, EX - EIGRP external C 2001:DB8:ACAD:1::/64 [0/0] via Vlan1, directly connected L 2001:DB8:ACAD:1::1/128 [0/0] via Vlan1, receive C 2001:DB8:ACAD:2::/64 [0/0] via GigabitEthernet0/0, directly connected L 2001:DB8:ACAD:2::2/128 [0/0] via GigabitEthernet0/0, receive S 2001:DB8:ACAD:3::/64 [1/0] via FE80::1:1, GigabitEthernet0/0 C 2001:DB8:CAFE:1::/64 [0/0] via GigabitEthernet0/1, directly connected L 2001:DB8:CAFE:1::2/128 [0/0] via GigabitEthernet0/1, receive S 2001:DB8:CAFE:2::/64 [1/0] via FE80::2:1, GigabitEthernet0/1 L FF00::/8 [0/0] via Null0, receiveshow ip route static:R2#show ip route static 172.16.0.0/16 is variably subnetted, 5 subnets, 2 masks S 172.16.3.0/24 [1/0] via 172.16.2.1 S 192.168.2.0/24 [1/0] via 192.168.1.1show ip route siećishow ipv6 route sieć:R2#show ip route 192.168.2.0 Routing entry for 192.168.2.0/24 Known via "static", distance 1, metric 0 Routing Descriptor Blocks: * 192.168.1.1 Route metric is 0, traffic share count is 1 R2#show ipv6 route 2001:DB8:ACAD:3:: Routing entry for 2001:DB8:ACAD:3::/64 Known via "static", distance 1, metric 0 Route count is 1/1, share count 0 Routing paths: Routing paths:FE80::1:1 Last update FE80::1:1 on GigabitEthernet0/0, 00:00:00 agoshow running-config | section route:ip route 172.16.3.0 255.255.255.0 172.16.2.1 ip route 192.168.2.0 255.255.255.0 192.168.1.1 ipv6 route 2001:DB8:ACAD:3::/64 GigabitEthernet0/0 FE80::1:1 ipv6 route 2001:DB8:CAFE:2::/64 GigabitEthernet0/1 FE80::2:1
Kombinacje:show running-config | section ip route,show running-config | section ipv6 route,
2.15.2. Konfigurowanie trasy domyślnej
Trasa domyślna jest wybierana w momencie gdy dla przesyłanego pakietu nie można dopasować żadnego wpisu z tablicy. Oczywiście o ile taką trasę skonfigurowano. W codziennym zastosowaniu trasy domyślne stosowane są w routerach domowych w celu przekazywania pakietów do usługodawcy internetowego, zapewniając tym samym dostęp do Internetu. Trasa domyślna stosowana jest w sieciach szczątkowych, gdzie do routera takiej sieci podłączony jest tylko jeden router wysyłający.
W naszej topologii takimi sieciami są: 172.16.3.0/24 oraz 192.168.2.0/24, i tak też je skonfigurujemy przy czym R2 będzie posiadać trasy statyczne następnego przeskoku do jednej jak i drugiej sieci. Poniżej znajdują się polecenia konfigurujące trasę domyślną w sieciach szczątkowych, oraz konfigurujące routing routera R2. Wyświetlono również tablicę routingu, routera sieci szczątkowej 1.
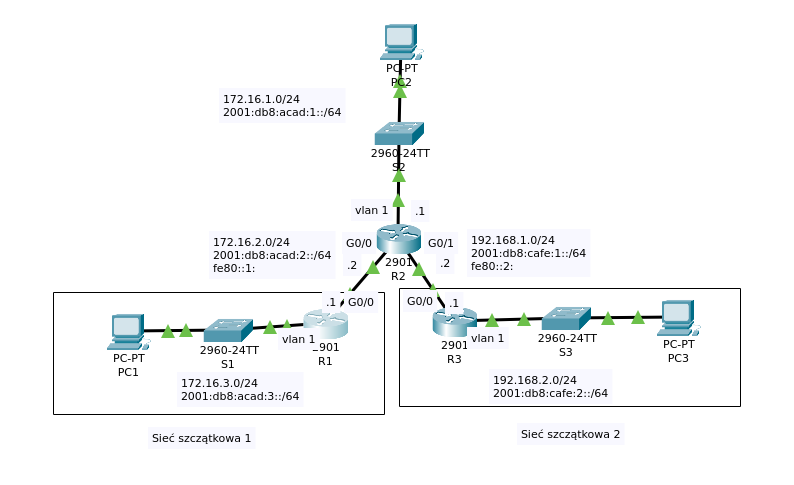
#R1:
R1(config)#ip route 0.0.0.0 0.0.0.0 172.16.2.2
R1(config)#ipv6 route ::/0 2001:db8:acad:2::2
#R3:
R3(config)#ip route 0.0.0.0 0.0.0.0 192.168.1.2
R3(config)#ipv6 route ::/0 2001:db8:cafe:1::2
#R2:
R2(config)#ip route 172.16.3.0 255.255.255.0 172.16.2.1
R2(config)#ip route 192.168.2.0 255.255.255.0 192.168.1.1
R2(config)#ipv6 route 2001:db8:acad:3::/64 2001:db8:acad:2::1
R2(config)#ipv6 route 2001:db8:cafe:2::/64 2001:db8:cafe:1::1
#R1:
R1#show ip route
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static route
Gateway of last resort is 172.16.2.2 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 4 subnets, 2 masks
C 172.16.2.0/24 is directly connected, GigabitEthernet0/0
L 172.16.2.1/32 is directly connected, GigabitEthernet0/0
C 172.16.3.0/24 is directly connected, Vlan1
L 172.16.3.1/32 is directly connected, Vlan1
S* 0.0.0.0/0 [1/0] via 172.16.2.2
IPv6 Routing Table - 6 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
S ::/0 [1/0]
via 2001:DB8:ACAD:2::2
C 2001:DB8:ACAD:2::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:2::1/128 [0/0]
via GigabitEthernet0/0, receive
C 2001:DB8:ACAD:3::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:3::1/128 [0/0]
via Vlan1, receive
L FF00::/8 [0/0]
via Null0, receive
Po skonfigurowaniu tras domyślnych jak i tras statyczny routera R2, PC1 może komunikować z PC2 i PC3 po IPv4 jak i IPv6, pamiętając przy tym, że router sieci szczątkowej 1, nie żadnych jawnie zapisanych tras. Posiada on trasę domyślną wskazującą na adres następnego skoku w tym przypadku interfejs routera R2, w sieci 172.16.2.0 (172.16.2.2).
2.15.3. Pływające trasy statyczne
Pływające trasy statyczne są to trasy statyczne używane do zapewnienia ścieżki rezerwowej dla głównej trasy lub trasy dynamicznej w przypadku awarii łącza. Pływająca trasa statyczna jest używana tylko wtedy gdy trasa główna jest niedostępna. Konfiguracja trasy pływającej polega na zmianie dystansu administracyjnego trasy zapasowej względem trasy głównej.
W tym celu w naszej topologii utworzymy kolejną sieć między interfejsami Gig0/1 R1 oraz R3. Interfejsy skonfigurujemy dla IPv4 jak i IPv6. Następnie dodam następujące trasy.
#R1:
R1(config)#ip route 0.0.0.0 0.0.0.0 172.16.2.2
R1(config)#ip route 0.0.0.0 0.0.0.0 10.10.10.2 5
R1(config)#ipv6 route ::/0 2001:db8:acad:2::2
R1(config)#ipv6 route ::/0 2001:db8:feed:10::2 5
#R3:
R3(config)#ip route 0.0.0.0 0.0.0.0 192.168.1.2
R3(config)#ip route 0.0.0.0 0.0.0.0 10.10.10.1 5
R3(config)#ipv6 route ::/0 2001:db8:cafe:1::2
R3(config)#ipv6 route ::/0 2001:db8:feed:10::1 5
#R2
R2(config)#ip route 172.16.3.0 255.255.255.0 172.16.2.1
R2(config)#ip route 192.168.2.0 255.255.255.0 192.168.1.1
R2(config)#ipv6 route 2001:db8:acad:3::/64 2001:db8:acad:2::1
R2(config)#ipv6 route 2001:db8:cafe:2::/64 2001:db8:cafe:1::1
R1#show ip route
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static route
Gateway of last resort is 172.16.2.2 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 10.10.10.0/24 is directly connected, GigabitEthernet0/1
L 10.10.10.1/32 is directly connected, GigabitEthernet0/1
172.16.0.0/16 is variably subnetted, 4 subnets, 2 masks
C 172.16.2.0/24 is directly connected, GigabitEthernet0/0
L 172.16.2.1/32 is directly connected, GigabitEthernet0/0
C 172.16.3.0/24 is directly connected, Vlan1
L 172.16.3.1/32 is directly connected, Vlan1
S* 0.0.0.0/0 [1/0] via 172.16.2.2
R1#show ip route static
S* 0.0.0.0/0 [1/0] via 172.16.2.2
R1#show ipv6 route
IPv6 Routing Table - 8 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
S ::/0 [1/0]
via 2001:DB8:ACAD:2::2
C 2001:DB8:ACAD:2::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:2::1/128 [0/0]
via GigabitEthernet0/0, receive
C 2001:DB8:ACAD:3::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:3::1/128 [0/0]
via Vlan1, receive
C 2001:DB8:FEED:10::/64 [0/0]
via GigabitEthernet0/1, directly connected
L 2001:DB8:FEED:10::1/128 [0/0]
via GigabitEthernet0/1, receive
L FF00::/8 [0/0]
via Null0, receive
W momencie kiedy usuniemy link między R1 i R2 trasa domyślna zostanie zmieniona na tę skonfigurowaną z większą wartością AD.
#R1:
R1#show ip route static
S* 0.0.0.0/0 [5/0] via 10.10.10.2
R1#show ipv6 route
IPv6 Routing Table - 6 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
S ::/0 [5/0]
via 2001:DB8:FEED:10::2
C 2001:DB8:ACAD:3::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:3::1/128 [0/0]
via Vlan1, receive
C 2001:DB8:FEED:10::/64 [0/0]
via GigabitEthernet0/1, directly connected
L 2001:DB8:FEED:10::1/128 [0/0]
via GigabitEthernet0/1, receive
L FF00::/8 [0/0]
via Null0, receive
Pomimmo ustawienia tras pływających, nie ma co liczyć na komunikację między komputerami. Routery w ich sieciach również muszą mieć statyczne wpisy związane możliwymi trasami zapasowymi. Takie trasy też możemy dodać zmieniając na końcu odległość administracyjną.
2.15.4. Trasy statyczne hosta
Statyczne trasy hosta różnią się od tych tras definiowanych wcześniej długością maski lub prefiksu. W poprzednich przykładach wskazywaliśmy w tabeli trasy do całej sieci. Ale ustawiając maskę na 32 bity dla IPv4 i długość prefiksu na /128 dla IPv6 możemy kierować ruch do konkretnych hostów.
W topologię skonfigurowałem w taki sam sposób jak w przypadku statycznych tras domyślnych. Następnie wymusiłem za pomocą statycznych tras hosta aby ruch z PC1 do PC3, przechodził przez te dodatkową sieć awaryjną, skonfigurowaną na potrzeby przedstawienia pływających tras statycznych.
#R1:
R1(config)#ip route 192.168.2.10 255.255.255.255 10.10.10.2
R1(config)#ipv6 route 2001:db8:cafe:2::a/128 2001:db8:feed:10::2
#R3:
R3(config)#ip route 172.16.3.10 255.255.255.255 10.10.10.1
R3(config)#ipv6 route 2001:db8:acad:3::a/128 2001:db8:feed:10::1
#Polecenie tracert wykonane z PC1 do PC3 przed zastosowanie powyższych tras:
C:\>tracert 192.168.2.10
Tracing route to 192.168.2.10 over a maximum of 30 hops:
1 0 ms 0 ms 0 ms 172.16.3.1
2 0 ms 0 ms 0 ms 172.16.2.2
3 0 ms 0 ms 0 ms 192.168.1.1
4 1 ms 10 ms 10 ms 192.168.2.10
Trace complete.
#Polecenie tracer wykonane z PC1 do PC3 po zastosowaniu powyższych tras:
C:\>tracert 192.168.2.10
Tracing route to 192.168.2.10 over a maximum of 30 hops:
1 0 ms 0 ms 0 ms 172.16.3.1
2 * 0 ms 0 ms 10.10.10.2
3 0 ms 0 ms 0 ms 192.168.2.10
Trace complete.
R1#show ip route static
192.168.2.0/32 is subnetted, 1 subnets
S 192.168.2.10 [1/0] via 10.10.10.2
S* 0.0.0.0/0 [1/0] via 172.16.2.2
R1#show ipv6 route
IPv6 Routing Table - 9 entries
...
S ::/0 [1/0]
via 2001:DB8:ACAD:2::2
C 2001:DB8:ACAD:2::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:2::1/128 [0/0]
via GigabitEthernet0/0, receive
C 2001:DB8:ACAD:3::/64 [0/0]
via Vlan1, directly connected
L 2001:DB8:ACAD:3::1/128 [0/0]
via Vlan1, receive
S 2001:DB8:CAFE:2::A/128 [1/0]
via 2001:DB8:FEED:10::2
C 2001:DB8:FEED:10::/64 [0/0]
via GigabitEthernet0/1, directly connected
L 2001:DB8:FEED:10::1/128 [0/0]
via GigabitEthernet0/1, receive
L FF00::/8 [0/0]
via Null0, receive
Po zastosowaniu trasy liczba przeskoków dla ruch z PC1 do PC3 spadła o jeden przeskok. Zwróćmy uwagę na to, że IOS przestawia trasę hosta jako trasę podrzędną dla trasy nadrzędnej z maską 32-bitową.
Zadanie praktyczne - Packet Tracer
Skonfiguruj statyczne i domyślne trasy IPv4 i IPv6 - scenariusz
Skonfiguruj statyczne i domyślne trasy IPv4 i IPv6 - zadanie
Laboratorium
Konfiguracja statycznych i domyślnych tras IPv4 i IPv6
Podsumowanie
W tym rodziale poznaliśmy rodzaje tras statycznych i przy użyciu topologii dual-stack nauczyliśmy się konfigurować poszczególne ich typy. Dowiedzieliśmy się również jakie możemy napotkać problemy związane z konfiguracją tras statycznych.
2.16. Rozwiązywanie problemów związanych z trasami statycznymi oraz z trasami domyślnymi.
Czasmi może zdarzyć się taka sytuacja, że pomimo skonfigurowania trasy statycznej, komunikacja między hostami nie dochodzi do skutku. W przypadku tras statycznych nie wiele jest możliwości, w których można namieszczać w konfiguracji aby komunikacja faktycznie nie zachodziła. Takie sytuacje najczęsciej wynikają z błedów popełnionych podczas dodawania takich tras do tablicy. Warto pamietać o tym, że w przypadku tras statycznych, musimy dodać trasy w obie strony. Poniżej znajduje się kilka zasad, jakie warto sobie przyswoić, aby mieć w głowie pewien schemat działania, który pozwoli rozwiązać problemy związane z trasami statycznymi.
- Sprawdź adresację interfejsów, biorących udział w trasowaniu.
- Sprawdź tablicę routingu, zarówno dla IPv4 jak i IPv6.
- Zapinguj wewnętrzny interfejs sieci LAN z routera.
- Sprawdź adresacje hostów oraz ich fizyczne możliwości połączenia się z siecią.
W realizacji tych zadań mogą pomóc nam poniższe polecenia:
show ip/ipv6 interface briefshow ip/ipv6 routeshow running | section routepingtracertipconfig /all | ip ashop cdp neighbors detail
Poza poleceniami ipconfig /all a
ip a,
ping,
tracert,
to w większości tyczą się systemu Cisco IOS. Polecenia ping
oraz tracert (traceroute), również są dostępne na
routerach. IOS często
pozwala na rozszerzenie składni, względem ich implementacji w innych
systemach. Dla przykładu polecenie ping pozwala na określenie
interfejsu wyjściowego, za pomocą opcji source.
Jeśli stwierdzimy że jedna z tras w tablicy jest niepoprawna i chcielibyśmy ją usunąć, to najlepszym rozwiązaniem jest znalezienie polecenia odpowiedzialnego za te trasę w konfiguracji bierzącej i poprzedzenie go przedrostkiem no.
Podsumowanie
W tym jakże krótkim rozdziale, zapoznaliśmy się z metodami oraz poleceniami pozwalającymi nam naprawę problemów związanych z trasami statycznymi i domyślnymi. Ten rodział jednocześnie kończy materiał przeznaczony dla drugiego modułu kursu CCNA. Poniżej znajdują się opisy egzaminów oraz zadań przygotowawczych do nich.
Zadanie praktycznie - Packet Tracer
Rozwiązywanie problemów z trasami statycznymi i domyślnymi - scenariusz
Rozwiązywanie problemów z trasami statycznymi i domyślnymi - zadanie
Laboratorium
Rozwiązywanie problemów ze statycznymi i domyślnymi routerami IPv4 i IPv6
2. Egzamin próbny - SRWE
W przypadku drugiego semestru, egzamin próbny nie zmienił się zmienił zmienił się jedynie zakres materiału. 55 pytań nie podlegających ocenie od tak, aby się przetestować przed finalem. Ukończenie tego egzaminu, ale nie koniecznie jego zdanie, jest wymagane do ukończenia modułu.
2. Przygotowanie do egzaminu praktycznego - SRWE
Podchodząc do tego egzaminu, załem sobie sprawę, że zostaliśmy nieco wprowadzeni w błąd przez prowadzącego 1 moduł. Otóż jako egzamin praktyczny otrzymaliśmy zadanie, które w netacad widnieje jako przygotowanie do egzaminu praktycznego. Prawdziwy Final practise dla ITN jest krótszy. Zawiera elementy z próbnego ale rzeczy do zrobienia jest mniej. Tutaj również wymagane jest faktycznych połaczeń między urządzeniami, np. konfigurując router musimy podłączyć się do niego kablem konsolowym, a nie wybrać zakładkę CLI. Tyle podobieństw względem modułu pierwszego. W module drugim próbny praktyczny podzielony jest na dwie części pierwsza część zawiera: podstawową konfigurację urządzeń, konfigurację VLAN i routingu między nimi w dwóch wariantach, wykorzystania z protokołu DTP, konfiguracji EtherChannel oraz ustawienia domyślnych bram na hostach. Zabrakło konfigurjacji FHRP. W drugiej części do zrobienia jest routing statyczny w tym trasy do hosta, trasy domyślne i pływające dla IPv4 i IPv6; konfiguracja DHCP, konfiguracja bezpieczeństwa portów oraz dodatkowych mechanizmów ochrony: DHCP snooping, DAI oraz zabezpieczenia STP (PortFast oraz BPDU guard), na koniec WLAN z uwierzytelnianiem klasy enterprise.
2. Egzamin końcowy - SRWE
Egzamin końcowy wygląda identycznie jak egzamin próbny, jednak w tym przypadku pytań jest o 5 więcej. Tutaj warto wpomnieć o tym, że pytania mogą się powtórzyć z próbnego czy cząstkowych, więc warto robić sobie zrzuty ekranów, tych egzaminów. Egzamin probny daje nam obraz tego czego możemy się spodziewać na finalu.
2. Egzamin praktyczy - SRWE
W przypadku egzaminu praktycznego możemy dowiedzieć się, jakie uprawnienia ma akademia względem kursu CCNA. Instruktor jest w stanie stowrzyć swój własny egzamin - zadanie praktyczne w Packet Tracerze. Samo zadanie nie jest nigdzie przesyłane. Prowadzący wpisuje tylko do netacad ilości procentowe uzyskane przez kursantów. W przypadku mojego egzaminu do zrobienia były: VLAN-y oraz EtherChannel z wykorzystaniem LACP, ustawienie priorytetów STP oraz konfigurcja IP przełącznika z bramą domyślną. Następnie należy skonfigurować statycznie wszystkie hosty, ustawić routing między vlan-ami z wykorzystaniem routera, ustawić trasy statyczne następnego skoku, aby uzyskać pełną osiągalność wszystkich podsieci. Następnie skonfigurować bezpieczne zdalne połączenie po SSH oraz ustawić hasło dla trybu uprzywilejowanego.
Koniec części 2
3. Moduł 3: Sieci korporacyjne, bezpieczeństwo i automatyzacja
Ostatni moduł kursu CCNA firmy Cisco. Obejmuje on takie tematy jak Jeden protokół routingu dynamicznego w podstawowym zakresie - jednoobszarowy OSPF, podstawowe omówienie zagrożeń bezpieczeństwa, listy dostępowe, funkcję NAT realizowaną przez urządzenia z systemem IOS, koncepcje sieci WAN, VPN, QoS, zarzadzanie siecią, w tym aktualizacje IOS na urządzeniach. Moduł kończą takie tematy jak zasady projektowania sieci, rozwiązywania problemów występujących z nimi, wirtualizacja w tym pojęcie SDN oraz automatyzacja.
3.1 Koncepcje jednoobszarowego OSPFv2
Drugi moduł kończył się wprowadzeniem do koncepcji routingu oraz routingiem statycznym. Wadą routingu statycznego był fakt, że musielśmy dodawać wszystkie trasy ręcznie do każdego z urządzeń oraz wymagane było utworzenie tras powrotnych. Oczywiście ma to swoje zalety i w małych sieciach nikt nie będzie uruchamiał dynamicznych protokołów dla kilku tras. Jednak sieci rosną, mogą urosnąć i wówczas wpisywanie tych tras na wielu routerach może stać się irytujące. Dlatego też warto zapoznać się prostym, a zarazem dobrym protokołem routingu dynamicznego. Takim jak OSPF w wersji 2.
OSPF jest protokołem stanu łącza (na podstawie jego możliwości, decyduje o trasie). Został obmyślony jako następca protokołu RIP, którego metoda wyboru najlepszej trasy nie skaluje się zbyt dobrze. Działanie RIP można przyrównać do działania systemu GPS, wybierającego najkrótszą trasę, bez znaczenia, że musimy przejechać przez kilka miejscowości, przez co podróż trochę nam zajmie. OSPF natomiast preferuje autostrady, gdzie dystans może być większy, ale zostanie on wyrównany na prędkości z jaką możemy się poruszać.
W tytule rozdziału zostało wspomniane o jednoobszarowym OSPFv2. OSPF wprowdza koncepcję obszaru - podziału domeny routingu - przez co możemy kontrolować aktualizację informacji na temat dostępnych tras. Oznacza to, że możemy skonfigurować protokół w ten sposób aby nie wszystkie sieci były ze sobą połączone.
Jak już wcześnie zostało wspomaniane OSPF wybiera trasę na podstawie możliwości łącza - to protokół stanu łącza. Informacje jakie routery w tym samy obszarze wymieniają na temat łączy są nazwane link-state i zawierają takie informacje jak: prefiks sieciowy (adres sieci), długość prefiksu (maskę podsieci) oraz koszt (obliczoną wartość, określającą przepustowość łącza).
Większość protokołów routingu składa się z tych samych elementów, takich jak:
- Komunikaty protokołu
- Struktury danych
- Algorytm
Komunikatami wymienianymi przez OSPF, są między innymi pakiety:
- Hello
- Opisu bazy danych (Database Description - DBD)
- Żądania stanu łącza (Link-State Request - LSR)
- Aktualizacji stanu łącza (Link-State Update - LSU)
- Potwierdzenia stanu łącza (Link-state acknowledgment - LSAck)
Informacje przesyłane przez pakiety wykorzystywane są do wykrywania sąsiedzkich urządzeń, utrzymwania informacji o obecnie wykorzystywanych trasach i jak ich aktualizacji.
OSPF wykorzystuje takie struktury danych jak:
- Baza przyległości (Adjacency database) - Tworzy tablice sąsiadów.
- Bazę stanu łącza (Link-state database - LSDB) - Tworzy tablicę topologii.
- Bazę przekazywania (Forwarding database) - Tworzy tablicę routingu.
Te tablice zawierają listę sąsiednich urządzeń w celu wymiany informacji o routingu. Są one przechowywane w pamięci RAM. Możemy do nich uzyskać dostęp poprzez odpowiednie polecenia IOS:
- Baza przyległości -
show ip ospf neighbor - Baza stanu łącza -
show ip ospf database - Baza przekazywania -
show ip route
OSPF buduje tablice topologii przy użyciu wyników obliczeń opartych na algorytmie Edsgera Dijkstry - pierwszej najkrótszej ściezki - SPF. Podstawą na której opiera się działanie algorytmu SPF, jest łączny koszt dotarcia do celu.
Proces wyboru najlepszej trasy składa się z 5 czynności:
- Ustawnowienie przyległości sąsiadów.
- Wymiana komunikatów o stanie łącza (LSA).
- Tworzenie bazy stanów łączy.
- Wykonanie algorymu SPF.
- Wybór najlepszej trasy.
Routery wykorzystujące OSPF muszą się rozpoznawać za nim, rozpoczną wymianę informacji o stanie łączy. W tym celu router wysyła pakiet Hello aby wykryć czy na tym łączu znajdują się inne routery z włączonym OSPF, jeśli tak to urządzenie spróbuje utworzyć relacje sąsiedztwa - określaną mianem przyległości.
Po ustanowieniu przygległości routery zaczynają wymieniać między sobą informacje na temat stanu bezpośrednio podłączonych łączy. Ten informacje wysłane są w dużych ilość - powodując zalanie sąsiada pakietami LSA. Każdy router po odebraniu takich informacji przekazuje do następnego sąsiada, do momentu aż każdy z routerów odbierze LSA od każdego z sąsiadów w obszarze.
Po odebraniu LSA, router tworzy bazę danych LSDB. Zawiera ona informacje o całej topologii.
Po zebraniu informacji w LSDB, routery uruchamiają algorytm SPF, wynikiem działania tej czynności jest drzewo SPF.
Na podstawie drzewa SPF, nalepsze ścieżki są proponowane do tablicy routingu urządzenia. Mogą one zostać w niej zapisane, chyba że do danej sieci istnieje trasa o niższej odległości administracyjnej, wówczas taka trasa dynamiczna nie zostanie zapisana w tablicy routera.
OSPF wprowadza strukturę hierarchiczną na podstawie obszarów. Obszar OSPF to grupa routerów wspódzieląca w bazie LSDB te same informacje na temat stanów łącz. W tym przypadku protokół OSPF możemy wykorzystać na na dwa sposóby:
- Jednoobszarowy OSPF - wszystkie routery znajdują się w jednej grupie. Zalecanym numerem obszaru jest 0.
- Wieloobszarowy OSPF - routery znajdują się w poszczególnych grupach, zawsze połączonych z obszarem 0 (obszar rdzenia). Routery łączące ze sobą obszary noszą miano routerów międzyobszarowych (ABR - Area Border Router).
Użycie wieloobszarowego OSPF pozwala nam zmniejszenie domeny routingu, co pozwala nieco odciążyć urządzenia, które muszą przetwarzać komunikaty LSA tylko dla swojego obszaru. Po mimo to routing będzie dalej działać, dzięki ABR. W przypadku gdy dochodzi do zmiany topologi routery w innych obszarach nie uruchamiają algorytmu SPF, tylko aktualizują tablicę routingu. Korzyści płynące z podziału jednego dużego obszaru na mniejsze są następujące:
- Mniejsze tablice routingu
- Zmiejszony narzut aktualizacji stanu łącza.
- Zmniejszona częstotliwość obliczeń SPF.
OSPF w wersji 3, służy do wymiany prefiksów sieci IPv6. Wymienia one informacje na temat routingu, aby wypełnić tablicę routingu IPv6 prefiksami sieci zdalnych. Dzięki funkcji rodzin adresów, OSPFv3 może obsługiwać zarówno IPv6 jak i IPv4. Protokół ten posiada te same funkcje co OSPF w wersji 2, natomiast OSPFv3 uruchamia osobne procesy dla IPv4 i IPv6.
Rodziny adresów wykraczają po za zakres kursu CCNA.
3.1.1. Pakiety OSPF
Omawiając OSPF poznaliśmy rodzaje pakietów jakie urządzenia wysyłają między sobą. Pakiety te mają przypisane określone wartości liczbowe, który jest typem pakietów LSP (Link-State Packets).
- Typ 1: Hello - jest używany do ustanawiania i utrzymywania relacji przyległości między innymi routerami OSPF.
- Typ 2: Pakiet opisu bazy danych (DBD) - zawiera skróconą listę LSDB i jest wykorzystywana przez inne routery odbierające do porównania z lokalną bazą LSDB. Baza musi być na wszystkich routerach w danym obszarze identyczna, aby móc zbudować drzewo SPF.
- Typ 3: Pakiet żądania stanu łącza (LSR) - Routery odbierające mogą zarządać dodatkowym informacji o dowolnym wpisie w DBD wysyłając LSR.
- Typ 4: Pakiet aktualizacji stanu łącza (LSU) - służy do odpowiadnia na LSR i ogłaszania nowych informacji. Komunikaty LSU zawierają kilka różnych typów LSA.
- Typ 5: Pakiet potwierdzenia stanu łącza (LSAck) - Po otrzymaniu LSU router wysyła LSAck w celu potwierdzenia. Pole danych pakietu tego typu jest puste.
Początkowo urządzenia wymieniają między sobą pakiety DBD. Jeśli potrzebne są dodatkowe informacje na temat wpisów w bazie, routery mogą wysłać LSR, wówczas inne routery odpowiedzą za pomocą pakietu LSU. Pakiet LSU może zawierać 11 typów LSA dla OSPFv2. Różnica w terminologii między LSU a LSA może być mylącą, ponieważ te określenia stosowane są zamiennie, jednak należy pamiętać, że LSU może zwierać jeden lub więcej komunikatów LSA. Rodzaje komunikatów LSA są następujące:
- LSA Routera.
- Służy do synchronizacji bazy danych topologii pomiędzy routerami.
- Podsumowanie LSA.
- Podsumowanie LSA.
- LSA zewnętrznego systemu autonomicznego.
- LSA transmisji multicast OSFP.
- Zdefiniowane dla obszarów NSSA (Not-So-Stubby-Areas).
- Atrybuty zewnętrzne LSA dla protokołu BGP (Border Gateway Protocol).
Pakiety Hello, posiadają kilka dodatkowych czynności wykonywanych na rzecz protokołu OSPF, do jego zadań należy między innymi:
- Wykrywają sąsiadów OSPF i tworzą z nimi przyległości.
- Ogłaszają parametry, które dwa routery muszą uzgodnić, aby zostać sąsiadami.
- Wybierają router desygnowany i zapasowy router desygnowany w sieciach wielodostępowych, takich jak Ethernet. Łącza typu punkt-punkt nie potrzebują DR ani BDR.
Natomiast sam pakiet Hello, składa się z nagłówka OSPF oraz jego własnych danych. Części te zawierają następujące pola:
Nagłówek pakietu OSPF:
- Typ - pole określające rodzaj informacji zawartych w polu danych pakietów OSPF.
- Identyfikator routera - Identyfikator pozwalający na jednoznaczne określenie routera źródłowego. Identyfikator ten ma postać identyczną z adresem IP.
- Identyfikator obszaru - numer obszaru, z którego pochodzi ten pakiet.
Dane pakietu Hello:
- Maska podsieci - skojarzona z interfejsem wysyłającym.
- Interwał Hello - określa częstotliwość wysłania pakietów Hello. Domyślnie jest 10 sekund. Ważne jest aby routery miały ustawioną taką samą tę wartość, inaczej nie dojdzie do relacji przylegania.
- Priorytet routera - wartość wykorzystywana w wyborze DR/BDR. Domyślną wartością dla wszyskich routerów jest 1. Jednak może przyjmować wartości od 0 do 255. Im wieksza wartość, tym większe prawdopodobieństwo, że router zostanie wybrany desygnowanym na łączu.
- Interwał Dead - określona ilość czasu, przez którą czeka router na sygnał od sąsiada, za nim ogłosi że on nie działa. Domyślnie ta wartość wynosi czterokrotność wartości Hello. Czas ten musi być na wszystkich routerach takich sam, inaczej nie dojdzie do relacji przyleania.
- Router desygnowany (DR) - identyfikator routera desygnowanego (DR).
- Zapasowy router desygnowany (BDR) - identyfikator zapasowego routera desygnowanego.
- Lista sąsiadów - lista zawierająca identyfikatory wszystkich sąsiadujących routerów.
3.1.2. Działanie OSPF
Podczas osiągania zbierzności w sieci protokół OSPF będzie znajdować się kolejno w następujących stanach:
- Stan Down -
- Brak odebranych pakietów Hello = Down.
- Router wysła pakiety Hello.
- Przejście do stanu init.
- Stan Init -
- Pakiety Hello, są odbierane od sąsiada.
- Zawiera identyfikator routera wysyłającego.
- Przejście do stanu Two-Way.
- Stan Two-Way -
- W tym stanie komunikacja między dwoma routerami jest dwukierkowa.
- Na łączach wielodostępowych routery wybierają DR i BDR.
- Przejście do stanu ExStart.
- Stan ExStart -
- W sieciach punkt-punkt, oba routery decydują, który router zainicjuje wymianę pakietów DBD oraz ustalają początkowy numer sekwencji pakietów DBD.
- Stan Exchange -
- Routery wymieniają pakiety DBD.
- Jeśli wymagane są dodatkowe informacje, to następuje przejście do stanu Loading, jeśli nie to do stanu Full.
- Stan Loading -
- W celu uzyskania dodatkowych informacji o trasach wykorzystywane są komunikaty LSU i LSR.
- Trasy są przetwarzane z użyciem algorytmu SPF.
- Przjeście do stanu Full.
- Stan Full - Baza danych łącza stanu router jest w pełni z synchronizowana.
W celu ustalenia relacji przyległości, router w momencie uruchomienia OSPF na określonych interfejsach wysyła przez nie pakiet Hello na adres multicastowy - 224.0.0.5. W ten sposób protokół na tym urządzeniu przechodzi ze stanu Down do stanu Init. W momecie gdy drugi router obierze pakiet Hello dodaje identyfikator (OSFP) nadawcy do swojej listy sąsiadów następnie odpowiada nadawcy pakietem Hello, ze swoim identyfikatorem oraz listą sąsiadów. Nadawca odbiera Hello i dodaje ID drugiego routera do swojej listy sąsiadów. W momencie odebrania listy sąsiadów ze swoim ID protokoł przechodzi w stan Two-Way. Ten stan może wykonać dwie czynności w zależności od tego jakiego rodzaju łącze znajduje się na tym interfejsie jeśli:
- Jest to połączenie punkt-punkt (połączenia szeregowe) to protokół przechodzi natychmast w stan ExStart.
- Jeśli jest to łącze wielodostępowe, np. Ethernet, to zachodzi potrzeba wybrania routera desygnowanego oraz zapasowego routera desygnowanego.
Podczas wyboru DR oraz BDR, cały czas pomiędzy urządzeniami wysłane są pakiety Hello. Pierwszy router - R1 - ma priorytet równy 1 i drugi najwyższy ID routera. Drugi router - R2 - ma również priorytet równy jeden, ale ma wyższe ID routera. Zatem R1 zostanie wybrany jako BDR, a R2 jako DR.
Po osiągnieciu stanu Two-Way przez protokół OSFP, następną czynnością jest synchronizacja baz danych. Do ustalania relacji przyległości wykorzystywaliśmy komunikaty Hello. Natomiast do synchronizacji baz wykorzystamy pakiety DBD oraz LSR.
W stanie ExStart routery decydują o tym, który z nich wyśle DBD jako pierwszy. Router z najwyższym ID wyśle swoje DBD jako pierwszy podczas stanu Exchange.
W stanie Exchange routery wymieniają się pakietami DBD, potwierdzając każdorazowo odbiór takiego pakietu, pakietem LSAck. Pakiet DBD zawiera informacje na temat wpisu nagłówka LSA, który występuje w bazie LSDB nadawcy. Wpisy mogą dotyczyć wybranego łączą lub sieci. Nagłówek każdego LSA zawiera: typ pakiet stanu łącza, adres routera rozgłaszającego, koszt danego łącza oraz numer sekwencyjny. Numer ten jest używany do ustalenia czy informacje zawarte w pakiecie są nadal aktualne.
Oczywiście może zdarzyć się sytuacja, że informacje zawarte DBD będą bardziej aktualne, wówczas protokół przechodzi do stanu Loading. Na podstawie informacji zawartych w DBD, router może zarządać od drugiego routera dodatkowych informacji na temat jednego ze wpisów. W tym celu wysyła do drugiego urządzenia komunikat LSR. Druga strona odpowiada mu komunikatem LSU, zawierającym dodatkowe informacje. Nadawca LSR odpowiada na LSU, komunikatem LSAck.
Natomiast jeśli otrzyma i przetworzy wszystkie żądania, wówczas można uznać go za w pełni zsynchonizowanego i protokół przechodzi w stan Full.
OSFP nie jest rozwiązaniem bez wad. W przypadku łączy wielodostępowych takich jak Ethernet, jeden z routerów będzie mieć relacje sąsiedztwa ze wszystkimi routerami w sieci, nawet tymi odległymi. Zwróćmy uwagę na to, że w sieci może być (jesli liczba routerów to n): n(n-1)/2 relacji przlegania. To całkiem dużo informacji do przetworzenia podczas uzyskiwania zbieżności OSPF. W przypadku 5 routerów relacji przyległości będzie tylko 10, ale w przypadku 20 już 190. Kolejną wadą jest zalewanie sieci przez pakiety LSA. Dlatego też do OSPF wprowadzono koncept routera desygnowanego (DR) oraz zapasowego routera desygnowanego..
Router desygnowany (DR) jest punkt zbierania oraz dystrybucji pakietów LSA, na wypadek jego awarii wybierany jest zapasowy router desygnowany (BDR). Pozostałe routery oznaczane są jako DROTHER, nie są one ani DR, ani BDR. Pozostałe routery tworzą relację przyległości z DR i BDR oraz DR z BDR. Wówczas LSA przesyłane jest tylko do tych dwóch urządzeń natomiast one przekazują te informacje dalej.
Podsumowanie
W pierwszym rodziale 3 modułu, zapoznaliśmy się z jedynym w tym kursie protokółem routingu - OSPF. Poznaliśmy jego elementy składowe, omówiliśmy komunikaty jakim się posługuje, aby wymienia informacje z innymi urządzeniami. Na koniec dowiedzieliśmy się w jaki sposób dokonuj on zbieżonści - poznaliśmy jego działanie.
3.2. Konfiguracja jednoobszarowego OSPFv2
W poprzednim rodziale zapoznaliśmy się z działaniem dynamicznego protokołu routingu, jakim jest OSPF w wersji 2. W tym rozdziale dowiemy się w jaki sposób uruchomić instację OSPF na urządzeniach z systemem IOS. Dla celów szkolenionych przyda nam się topologia utworzona w Packet Tracerze. Topologia powinna składać się z kilku routerów. Za pomocą interfejsów loopback, będziemy symulować obecność sieci lokalnej oraz Internetu. Topologia może wyglądać następująco:
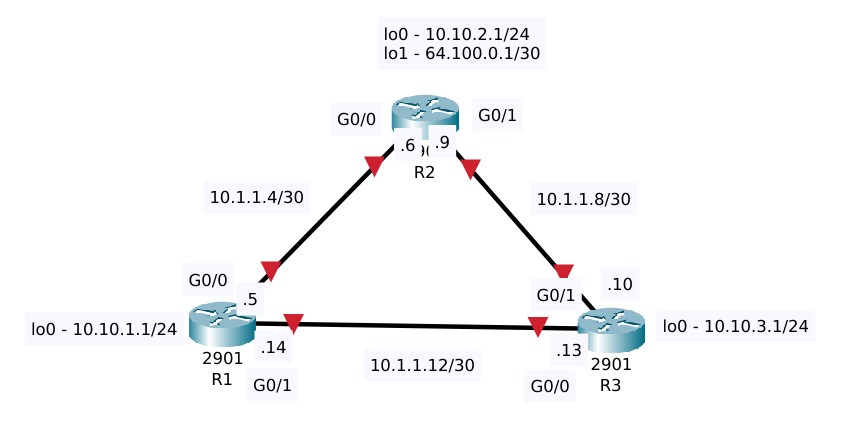
Uruchomienie OSPF w IOS jest czymś w rodzaju uruchomienia odrębnego programu. Ponieważ musimy zdefiniować ID procesu. Jest to wartość lokalna, ustawiana przez administratora. Pozwala ona urządzeniu rozróżnić procesy (na routerach Cisco, można uruchomić wiele instancji OSPF). ID procesu może przyjąć wartość od 1 do 65535. Rozbierzność w identyfikatorach procesu nie wpływa na ustawienie przylegania. Sam proces uruchomiamy w konfiguracji globalnej wydając poniższe polecenie:
R2(config)#router ospf 1 R2(config-router)#? area OSPF area parameters auto-cost Calculate OSPF interface cost according to bandwidth default-information Control distribution of default information distance Define an administrative distance exit Exit from routing protocol configuration mode log-adjacency-changes Log changes in adjacency state neighbor Specify a neighbor router network Enable routing on an IP network no Negate a command or set its defaults passive-interface Suppress routing updates on an interface redistribute Redistribute information from another routing protocol router-id router-id for this OSPF process
Po uruchomieniu procesu, przechodzimy do konfiguracji protokołu. Za pomocą znaku zapytania (?) możemy wyświetlić wszystkie dostępne polecenia w trybie konfiguracji OSPF.
Jak pamiętamy z poprzedniego rozdziału ID routera w OSPF korzysta formatu adresu IP. Nawet lepiej, wykorzystuje adresy które są zdefiniowane na urządzeniu, w przypadku automatycznej konfiguracji - nie podania ID. Nie mniej jednak, należy pamiętać, że to nie są adres IP i nie biorą one udziału w komunikacji. Identyfikator jest potrzebny w stanie Exchange do ustalenia, który router jako pierwszy wyśle komunikat DBD oraz do określania roli (DR/BDR) routera w przypadku łączy wielodostępowych.
Algorytm wyboru identyfikatora przezentuje się w następujący sposób:
- Jeśli identyfikator został jawnie skonfigurowany to wybierz go jako identyfikator routera. Jeśli nie to patrz krok 2.
- Jeśli skonfigurowano interfejs loopback, to użyj jego adresu IPv4 jako identyfikatora routera. Jeśli nie to patrz krok 3.
- Użyj najwyższego skonfigurowanego adresu IPv4 jako ID routera.
W przypadku jeśli skonfigurowano więcej niż jeden loopback, to wówczas algorytm zachowuje się identycznie jak w kroku 3, tylko wobec adresów interfejsów pętli.
W systemach produkcyjnych, możemy skonfigurować sobie interfejs pętli, aby jego adres został użyty jako ID routera w OSPF. W wykorzystywanej tutaj topologii, interfejsy loopback są wykorzystywane więc po uruchomieniu procesu OSPF na R2, przyjął on o taki oto identyfikator:
R2#show ip protocols
Routing Protocol is "ospf 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 64.100.0.1
Number of areas in this router is 0. 0 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
Routing Information Sources:
Gateway Distance Last Update
Distance: (default is 110)
Chcąc jawnie zmienić ID routera, musimy przjeść do konfiguracji
procesu OSPF, następnie użyć polecenia
router-id i jako argument podać ID.
R2(config)#router ospf 1
R2(config-router)#router-id 2.2.2.2
R2(config-router)#exit
R2(config)#do show ip proto
Routing Protocol is "ospf 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 2.2.2.2
Number of areas in this router is 0. 0 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
Routing Information Sources:
Gateway Distance Last Update
Distance: (default is 110)
W przypadku, gdy router bedzie mieć już jakieś relacje przygłości ID nie zostatnie zmienione. Aby nasze zmiany miały skutek, musimy z restartować proces OSPF. Dokonamy tego w trybie uprzywilejowanym EXEC, wydając poniższe polecenie:
R2#clear ip ospf process Reset ALL OSPF processes? [no]: yes
Po wydaniu tego polecenia system zapyta się czy zrestartować wszyskie procesy. Pyta dlatego, że nie podaliśmy ID procesu, nie mniej jednak w Packet Tracerze jest nie zostało to zaimplementowane.
Starsze wersje IOS, nie posiadają polecenia
router-id. Zatem najlepszym sposobem
na ustawienie ID routera jest skonfigurowanie interfejsu loopback.
3.2.1. Sieci w OSPF
Sieci w OSPF możemy konfigurować na dwa sposoby pierwszy z nich jest jest przypisanie sieci do procesu OSPF przy użyciu polecenia network, trybu konfiguracji protokołu. Poniżej znajduje się ogólna składania tego polecenia.
R2(config-router)# network adres-sieci maska-blankietowa area id-obszaru
Kombinacja adres sieci, maska blankietowa służy uruchomieniu OSPF na interfejsach. Natomiast id-obszaru wskazuje numer obszaru, w którym dana sieć ma być rozgłaszana. W przypadku konfiguracji jednoobszarowej, na wszystkich routerach powinien być ustawiony ten sam identyfikator obszaru. Dobrą praktyką jest ustawienie obszaru o ID 0.
Maska blankietowa (wildcard mask) jest odwrotnością, klasycznej maski podsieci. Jak w przypadku klasycznej maski, wartości binarnej 1 na masce oznaczały dopasowanie bitu adresu, a binarne 0 jego brak, tak w przypadku maski blankietowej: binarne 0 oznaczają dopasowanie odpowiedniej wartości bitu w adresie, a jeden zignorowanie wartości tego bitu w adresie. Maskę blankietową najlepiej utworzyć porzez odjęcie od pełnej maski 32-bitowej - 255.255.255.255, maski naszej sieci. Na przykład:
255.255.255.255
- 255.255.255.252
-----------------
0. 0. 0. 3
Maską blankietową dla maski podsieci /30 jest 0.0.0.3.
Teraz znając wszysktie części składni polecenia network możemy przejść do jego konfiguracji.
R1(config)#router ospf 1 R1(config-router)#network 10.1.1.4 0.0.0.3 area 0 R1(config-router)#network 10.1.1.12 0.0.0.3 area 0 R1(config-router)#network 10.10.1.0 0.0.0.255 area 0
Inną metodą na wykorzystanie polecenia jest network jest podanie zamiast adresu sieci, adresu interfejsu oraz maski 0.0.0.0. Uruchomi to proces na tym interfejsach i zacznie rozgłaszać sieci, które są dostępne na tych interfejsach.
R1(config)#router ospf 1 R1(config-router)#network 10.1.1.5 0.0.0.0 area 0 R1(config-router)#network 10.1.1.14 0.0.0.0 area 0 R1(config-router)#network 10.10.1.1 0.0.0.0 area 0
Drugim sposobem na rozgłaszanie sieci przez OSPF jest skonfigurowanie
tego bezpośrednio na interfejsie. Zanim do tego przejedziemy musimy,
wycofać uprzednio wprowadzone polecenia
network.
R1(config)#router ospf 1 R1(config-router)#no network 10.1.1.4 0.0.0.3 area 0 R1(config-router)#no network 10.1.1.12 0.0.0.3 area 0 R1(config-router)#no network 10.1.1.12 0.0.0.3 area 0 R1(config-router)#exit R1(config)#int g0/0 R1(config-if)# ip ospf 1 area 0 R1(config-if)#int g0/1 R1(config-if)# ip ospf 1 area 0 R1(config-if)#int lo0 R1(config-if)# ip ospf 1 area 0
Komunikty OSPF powinny być wysyłane wyłącznie na interfejsach, do których podłączone są inne routery z włączonym OSPF. Domyślnie jednak są one wysyłane przez wszystkie interfejsy, na których został uruchomiony ten protokół, w tym i sieci LAN, tutaj symulowanej za pomocą loopback-a. Takie działanie nie jest za bardzo pożądane, z kilku powodów:
- Nieefektywne wykorzystanie pasa - poprzez przesyłanie nie potrzebnych komunikatów.
- Nieefektywny wykorzystanie zasobów - każdy z hostów w sieci obiera część tych komunikatów, następnie musi je przetworzyć, a następnie odrzucić.
- Zwiększone ryzko bezpieczeństwa - ruch OSPF bez dodatkowych mechanizmów można przechwycić za pomocą takich narzędzi jak Wireshark i następnie wysłać fałszywą aktualizację ruchu i kierować go gdzie to tylko możliwe.
Zapobieganiu tego rodzaju niedogodnościom służy mechanizm interfejsu pasywnego. Jest to rodzaj konfiguracji, w której wskazujemy interfejs pasywny i ograniczamy wysyłanie komunikatów OSPF przez niego, przyczym pozostaje on częścią obszaru, tj. komunikaty na temat jego sieci dalej będą wysyłane do innych routerów. Konfiguracja pasywnego interfejsu znajduje się poniżej.
R1(config)#router ospf 1 R1(config-router)#passive-interface lo0 R1(config-router)#exit
Po uzyskaniu zbierzności OSPF, jeśli przyjrzymy się tablicy routingu to trasy do sieci reprezentowanych przez interfejsy loopback. Sa trasami hostów, a nie trasami do sieci. Jest domyślne działanie. Jeśli miały by być one trasami sieci, to na interfejsie pętli należy wydać poniższe polecenie.
R1(config-if)# interface Loopback 0 R1(config-if)# ip ospf network point-to-point
Wówczas ten interfejs będzie traktowany jako połączenie punkt-punkt. I teraz będzie rozgłaszana trasa to sieci interfejsu pętli.
Zadanie praktyczne - Packet Tracer
Konfiguracja OSPFv2 punkt-punkt - scenariusz
Konfiguracja OSPFv2 punkt-punkt - zadanie
3.2.2. Wielodostępowe sieci OSPF
Jak pamiętamy, jeśli skonfigurujemy OSPF na łączu wielodostępowym to wówczas routery ustalają między sobą rolę, aby zapewnić jak najmniejszy narzut OSPF na urządzenia.
Aby sprawdzić rolę routera możemy odpytać bazę relacji przyległości:
R1#sh ip ospf neigh Neighbor ID Pri State Dead Time Address Interface 3.3.3.3 1 FULL/DR 00:00:31 10.1.1.13 GigabitEthernet0/1 2.2.2.2 1 FULL/DR 00:00:34 10.1.1.6 GigabitEthernet0/0
Na podstawie kolumn State możemy
stwierdzić, że R1 jest w pełnej
zbieżności OSPF FULL oraz jest
zapasowym routerem desygnowanym jeśli role obu sąsiadów to
DR. Innym stanem jaki możemy
spotkać jest 2-WAY/DROTHER, oznacza on, że routery są
w stanie uzyskiwania zbieżności i jeszcze nie mają określonych ról.
Oczywiście możliwy jest wpływ na określanie ról routerów przy łączach wielodostępowych. Możemy swobodnie manipulować priorytetem OSPF. Dzięki czemy możemy jasno określić jakie urządzenie ma pełnić jaką rolę. Aby zmienić priorytet w konfiguracji interfejsu wydajemy poniższe polecenie:
R1(config)#int g0/0 R1(config-if)#ip ospf priority 200
Po zmianie priorytetu musimy zresetować proces OSPF.
Zadanie praktycznie - Packet Tracer
Określanie DR i BDR - scenariusz
Określanie DR i BDR - cenariusz
3.2.2. Modyfikowanie jednoobszarowego OSPFv2
Routery na podstawie metryki zapisanej w trasie, w tablicy routingu dokonują wybory najlepszej ścieżki. W przypadku OSPF tą metryką jest koszt obliczony poprzez iloraz referencyjne szerokości pasma przez szerokość pasma interfejsu. Te wartości wyrażone są w bitach na sekundę. Domyślną referencyjną szerokością pasma jest 100,000,000 b/s. To jeśli przeskalujemy sobie tę wartość na Mb. To wówczas wynik będzie = 100Mb/s, ze zwględu na to, że jest iloraz - metryka dla łączy 100Mb/s będzie równa 1. Dodatkowo te obliczenia są całkowite, więc łącza gigabitowe oraz 10-cio gigabitowe będą mieć tę samą metrykę co 100Mb. Więc ze względu na rozwijające się umożliwiono zmianę referencyjnej szerokości pasma.
Aby zmienić wartość refencyjną szerokości pasma, na wszystkich routerach w trybie konfiguracji protokołu OSPF wydajemy następujące polecenie
Router(config-router)# auto-cost reference-bandwidth Mbps
Zamiast Mbps podajemy wartość
referencyjną w Mb. W zależności od naszej infrastruktury, myślę że
można spokojnie ustawić 10Gb, tj. 10000Mb.
Inna wartością jaką możemy manipulować, aby wpłynąć na wybór najlepszej trasy przez OSPF jest sam koszt ścieżki. Dokonać tego możemy za pomocą poniższego polecenia wydane w konfiguracji interfejsu. Uwaga, należy pamiętać, aby ustawić również taki sam koszt po drugiej stronie ścieżki.
R1(config)# interface g0/1 R1(config-if)# ip ospf cost 30 R1(config-if)# interface lo0 R1(config-if)# ip ospf cost 10 R1(config-if)# end
Częstotliwość wysyłania pakietów Hello oraz czas oczekiwania na nie Dead, są kolejnymi cechami protokołu OSPF, na który my jako administratorzy możemy wpłynąć. Za pomocą polecenia:
R2#show ip ospf int g0/0 ... Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
Możemy sprawdzić jak została ustawiona częstotliwość pakietów Hello oraz ustawiony czas oczekiwania Dead. Dodatkowo czas oczekiwania Dead występuje w innym poleceniu
R2#show ip ospf neigh Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 1 FULL/BDR 00:00:30 10.1.1.5 GigabitEthernet0/0 3.3.3.3 1 FULL/BDR 00:00:30 10.1.1.10 GigabitEthernet0/1 R2#show ip ospf neigh Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 1 FULL/BDR 00:00:39 10.1.1.5 GigabitEthernet0/0 3.3.3.3 1 FULL/BDR 00:00:39 10.1.1.10 GigabitEthernet0/1
Tutaj czas oczekiwania został przedstawiony w kolumnie
Dead Time w postaci licznika, który
odlicza w dół do 0,
każdorazowe nadejście pakietu Hello go restartuje.
Modyfikacji wyżej wymienionych wartości możemy dokonać w konfiguracji interfejsu. Na obu routerach te wartości muszą być takie same inaczej nie dojdzie do relacji przyległości..
R1(config-if)# ip ospf hello-interval S R1(config-if)# ip ospf dead-interval S
Gdzie S, to liczba sekund. Te
wartości domyślnie są oparte o dobre praktyki. Nie ma potrzeby ich
zmieniać nie mniej jednak istnieje taka możliwość i została ona tutaj
przedstawiona.
Zadanie praktyczne - Packet Tracer
Modyfikowanie jednoobszarowego OSPFv2 - scenariusz
Modyfikowanie jednoobszarowego OSPFv2 - zadanie
3.2.4. Propagowanie tras domyślnych w OSPF.
Protokół OSPF daje nam możliwość możliwość rozpropagowania tras domyślnych z jednego routera na pozostałe w danym obszarze. Służy do tego poniższe polecenie wydane w konfiguracji protokołu OSPF.
R2(config)#ip route 0.0.0.0 0.0.0.0 lo1 %Default route without gateway, if not a point-to-point interface, may impact performance R2(config)# R2(config)#route ospf 1 R2(config-router)#default-information originate
Aby sprawdzić czy nasza trasa się rozpropagowała, należy wyświetlić tablicę routingu innego routera:
R1#show ip route ... Gateway of last resort is 10.1.1.6 to network 0.0.0.0 ... O*E2 0.0.0.0/0 [110/1] via 10.1.1.6, 00:04:14, GigabitEthernet0/0
Tak przekazaną trasę IOS traktuje jako zewnętrzną trasę OSPF typu 2.
Zadanie praktyczne - Packet Tracer
Propagowanie trasy domyślnej w OSPFv2 - scenariusz
Propagowanie trasy domyślnej w OSPFv2 - zadanie
3.2.5. Weryfikowanie jednoobszarowego OSPFv2
W celu zweryfikowania konfiguracji OSPFv2 na naszych urządzeniach możemy posłużyć się następującymi poleceniami:
show ip ospf neighbor- weryfikacja sąsiadów OSPF.show ip protocols- weryfikacja ustawień protokołu OSPF.show ip ospf- weryfikacja procesu OSPF.show ip ospf interface- weryfikacja ustawień interfejsu OSPF.
Powyższe polecenia mogą pomóc nam również w rozwiązywaniu problemów konfiguracją OSPF.
Zadanie praktyczne - Packet Tracer
Weryfikowanie jednoobszarowego OSPFv2 - scenariusz
Weryfikowanie jednoobszarowego OSPFv2 - zadanie
Zadanie praktyczne - Packet Tracer
Konfiguracja jednoobszarowego OSPFv2 punkt-punkt - scenariusz
Konfiguracja jednoobszarowego OSPFv2 punkt-punkt - zadanie
Laboratorium
Konfiguracja jednoobszarowego OSPFv2
Podsumowanie
W tym rozdziale przekonaliśmy się jak pomocne mogą być dynamiczne protokoły routingu. Poznaliśmy metody konfiguracji protokołu, konfiguracji jego funkcji, dzięki czemu dowiedzieliśmy się, że możemy dostoswać część jego aspektów, następnie zapoznaliśmy się z propagacją tras domyślnych, a na koniec poznaliśmy serię poleceń, która pozwoli nam zweryfikować działanie OSPF i rozwiązać ewentualne problemy.
3.3. Koncepcje bezpieczeństwa sieci
W pierwszym module poruszaliśmy podstawowe zagadnienia bezpieczeństwa sieci. Teraz możemy omówić sobie te zagadnienia w szerszym spektrum, nieco bardziej skupiając się na ich poszczególnych aspektach.
3.3.1. Obecny stan cyberbezpieczeństwa
Obecnie cały czas trwa wyścig zbrojeń, cyberprzestęcy są w zasięgu jeszcze większej ilość wiedzy technicznej oraz coraz bardziej zawansowanych narzędzi pozwalających na łamanie zabeczpieczeń firm, osób prywatnych czy nawet infrastruktury krytycznej państw. Na wysokim poziomie stoi również rozwój wszelakiej maści złośliwego oprogramowania.
Specjaliści stojący po drugiej stronie barykady muszą aktywnie przyglądać się rozwojowi zagrożeń oraz metod ich wykorzystywania, aby móc przygotować opowiednie środki zaradcze lub też z minimalizować skutek naruszenia naszych zabezpieczeń.
Chcąc zrozumieć opisane tutaj tematy musimy na początku poznać kilka pojęć:
- Zasoby - Zasobem możemy określić wszystko co dla organizacji, może mieć jakąś wartość. Od ludzi, przez sprzęt po dane w różnej postaci.
- Podatność - to słabość w systemie lub jego konstrukcji może być wykorzystana przez żagrożenie.
- Zagrożenie - potencjalne niebezpieczeństwo dla zasobów firmy.
- Exploit - mechanizm wykorzystania podatności.
- Ograniczenie - zmniejszenie prawdopodobniestwa lub dokliwości zagrożenia bądź ryzka.
- Ryzko - prawdopodobieństwo wykorzystania przez zagrożnie podatności zasobów mające negatywny wpływ na organizację. Jest ono mierzone przy użyciu prawdopobieństwa jego wystąpienia oraz jego potencjalnych skutków.
Spośród obecnie przeprowadznych ataków sieciowych możemy wytypować dwa typowe wektory ataków. Pierwszym z nich jest zewnętrzny wektor, oznacza on, że zagrożenie występuje poza naszą siecią wówczas ryzkiem liczyć się muszą urządzenia brzegowe, takie jak router czy zapory sieciowe, ale także aplikacje wystawione do sieci zewnętrznych w celu udostępnienia, niektórych zasobów firmy. Drugim wektorem jest wektor wewnętrzny gdzie zagrożenie stanowią pracownicy tej samej organizacji. Ten wektor jest szczególnie niebezpieczny, ponieważ pracownicy często znają infrastrukturę i często część metod uwierzytelnia i autoryzacji, ale co najważniejsze pracownicy posiadają pewien poziom uprawnień do zasobów firmy.
Jednym z dość szczególnych wektorów zagrożenia, które nie muszą być powiązane z atakami jest utrata danych. Dane są bardzo często najbardziej wartościowymi zasobami w firmie, ich utrata, bądź ich upublicznienie (jak w przypadku danych wrażliwych - np. wyniki badan czy dane osobowe pracowników) może być rownoznacza z zakończeniem jej działalności lub nieprzyjemnymi konsekwencjami prawnymi.
3.3.2. Podmioty zagrożenia
Dawniej hakerzy byli uznawani za żartownisiów, wykonujących przenajróżniejsze dowcipy. Poźniej termin ten ewoluował i by przypisywany wybitnym programistom, którzy dzieli się efektami swoich prac, gdzieś tam pojawili się pierwsi ludzie którzy łamali zabezpieczenia stawiane przez hakerów, którzy działali na zlecenie osób trzecich. Ich z kolei zaczęto nazwywać krakerami. Krakerzy dokonywali swojej działalności, z różnych pobudek, nie zawsze były to motywy finansowe, często było to sprawdzenie swoich umiejętności lub też uwolnienie informacji, która powinnać być dostępna dla opinii publicznej. Obecnie można spotkać się ze stwierdzeniem, że w Internecie panuje trzecia wojna światowa. Co jest poniekąd prawdą obecnie mało kto bawi się w łamanie zabezpieczeń dla zabawy. Jedni robią to z pobudek czysto finansowych i takowe osoby można uznać, za cyberprzestępców, innym rodzajem tego typu ludzi są hakerzy sponsorowani przez państwo, takie cyberarmie, które dokonują ataków na cele często będą infrastrukturą innych państw, motywy ich działania są znane tylko dowócom takich jednostek. Na szczególne omówienie zasługują tutaj haktywiści, dokonujący różnych naruszeń bezpieczeństwa sieci, chcąc zwrócić uwagę na jakiś problem społeczny oraz wywrzeć presję na politykę, aby rząd za przestał potencjalnego działania na szkodę obywateli - takie działanie miało miejsce 2012 przy próbie wprowadzenia ustawy ACTA.
Ostatecznie hakerów można podzielić na podstawie motywów ich działania, przypisując im odpowiedni kolor kapelusza. Tak więc białe kapelusze - to wszelkiego rodzaju programiści - członkowie społeczności otwartoźródłowych, ale również specjaliści do spraw bezpieczeństwa sieci, konsultanci oraz wszyscy dbający o bezpieczeństwo, nie tylko sieci za które są odpowiedzialni. Działają tylko w legalny sposób. Szare kapelusze - są to można by powiedzieć tzw. białe kapelusze, wykonujące nie które ze swoich zadań bez legalizacji. W celach rozrywkowych, poszerzenie swojej wiedzy czy również w celach prostestu (haktywiści). Ostatnią katergorią są czarne kapelusze - działają oni nielegalnie, dokonują włamań oraz zakłóceń w działaniu sieci. Hakerzy tego rodzaju to cyberprzestępcy oraz hakerz sponsorowani przez państwo.
3.3.3. Narzędzia podmiotów zagrożeń
Takim podstawowym narzędziem, każdego kapelusza jest system operacyjny, z możliwością dostosowanie każdego swojego apektu działania. Bowiem hakerzy nie wykorzystują tylko laptopów czy komputerów klasy PC. Wykorzystają całą masę innej elektroniki i czasami ona musi zostać zaprogramowana. Aby umożliwić dostosowanie systemu operacyjnego przez użytkownika musimy mieć możliwość wglądu w jego kod źródłowy, więc takimi systemami są wszystkie otwartoźródłowe systemy uniksopodobne. Od dystrybucji Linuksa po systemy BSD, ich biegła znajomość jest wymagana zarówno przez białe jak i czarne kapelusze.
Oczywiście same systemy, wiosny nie czynią. Potrzebne jest do tego specjalistyczne oprogramowanie. Kiedy jeszcze temat bezpieczeństwa nie był tak powszechny, haker musiał samodzielnie napisać eksploit, jak i program go obsługujący. Hakerzy musieli wyróżniać się wysoką wiedzą techniczną, a mimo to ich narzędzia były często ukierunkowane na jedną podatność. W momencie upowszechnienia się etycznego hakingu, narzędzia stały się bardziej wszechstronne i raczej skupiające się na pewnej funkcji, a niżeli na jednej podatności. Wśród nich możemy wyróżnić takie rodzaje oprogramowania jak:
- Narzędzia do łamania haseł - John The Ripper, Ophcrack, L0pthCrack, THC Hydra, RainbowCrack, Medusa.
- Narzędzia do sieci bezprzewodowych - Aircrack-ng, Kismet, InSSIDer, KisMac, Firesheep, NetStumbler.
- Narzędzia do skanowania sieciowego - Nmap, SuperScan, Angry IP Scanner i NetScan.
- Narzędzia do tworzenia pakietów - Hping, Scapy, Socat, Yersinia, Netcat, Nping i Nemezis.
- Snifery Pakietów - Wireshark, TCPdump, Ettercap, Dsniff, Etherape, Paros, Fidler, Ratproxy, SSLStrip.
- Detektory rootkitów - AIDE, NetFilter i PF (Filtr pakietów OpenBSD).
- Fuzzery do wyszukiwania podatności - Skipfish, Wapiti, W3af.
- Narzędzia kryminalistyczne - Sleuth Kit, Helix, Maltego i Encase.
- Debugery - GDB, WinDbg, IDA Pro i Immunity Debuger.
- Systemy operacyjne do hackingu - Kali Linux, Knopix, BackBox Linux.
- Narzędzia szyfrujące - VeraCrypt, CipherShed, OpenSSH, OpenSSL, Tor, OpenVPN, Stunel.
- Narzędzia eksploracji podatności - Metasploit, Core Impact, Sqlmap, Social Engineer Toolkit i Netsparker.
- Skanery podatności - Nipper, Secunia PSI, Core Impact, Nessus v6, SAINT i Open VAS.
Natomiast do rodzajów ataków możemy zaliczyć kolejno:
- Atak podsłuchiwania - ma miejsce gdy podmiot zagrożeń przechwytuje ruch sieciowy. Określane jako sniffing lub snooping.
- Atak modyfikacji adresów - zmiana danych w pakiety bez wiedzy stron tej komunikacji.
- Ataki z wykorzystaniem haseł - zalogowanie się na aktywne konto, w celach dalszej eskploracji sieci.
- Ataki odmowy usługi - atak symujący duży ruch przeciążając tym samym serwer. Staje się on niedostępne dla innych użytkowników.
- Ataki typu man-in-the-middle - wpięcie się pomiędzy nadawcą a odbiorcą zapewniając tym samym transparentną pełną kontrolę nad tą transmisją.
- Ataki za pomocą zagrożonego klucza - Podmiot zagrożenia uzyskuje klucz do szyfrowanej transmisji, wówczas w taki przesył informacji można ingrerować.
- Atak z użyciem sniffera - Użycie aplikacji pozwalającej na monitorowanie i przechwytwanie danych w sieci i odczytwanie pakietów.
3.3.4. Złośliwe oprogramowanie
Na początku rozdziału wspomniano, że obecnie bardzo prężnie działa rozwój złośliwego oprogramowania. Gdzieś tam kiedy, każdemu udało się zawirusować swój komputer, najczęściej odbywało się to poprzez pobranie jakiegoś szemranego pliku z Internetu. Najczęściej bywały to konie trojańskie, ale też słyszało się o wirusach, czy innych bardziej niechcianych programach. Najczęstszymi czynnościami wykonywanymi przez złośliwe oprogramowanie są:
- Różnego rodzaju modyfikacje plików, wraz z ich usunięciem.
- Zaburzenie uruchamiania systemu operacyjnego lub uszkodzenie aplikacji.
- Przekazywanie poufnych informacji do podmiotów zagrożeń.
- Uzyskanie dostępu do poczty elektronicznej i wykorzystanie jej do rozprzestrzeniania sie.
- Oczekiwać na sygnały od podmiotów zagrożenia.
Wirusy do rozprzestrzeniania się wymagają działalności człowieka, my natomiast możemy określić kilka ich rodzajów:
- Wirus sektora rozruchowego - wirus atakujący sektor rozruchowy, tablicę partycji lub system plików.
- Wirus oprogramowania układowego - wirus atakuje oprogramowanie układowe urządzenia.
- Wirus makr - wirusy złośliwe wykorzystujące funkcję makr w MS Office czy w innych aplikacja.
- Wirus programu - wirus wstawia się w inny program wykonywalny.
- Wirus skryptu - wirus atakuje interpreter poleceń systemu operacyjnego, wykorzystywany do wykonywania skryptów.
Innym ciekawym rodzaje złośliwego oprogramowania, wspominanego już w tym temacie, jest koń trojański, przypomina on przydatny program, jednak jego funkcje są rozszerzone o potencjalnie niebezpieczne dla nas działanie, takie jak np.: umożliwienie zdalnego dostępu, przekazywanie danych, destrukcję plików, uruchomienie proxy (przekaźnika) - pozwalającego na wykorzystanie połączenia komputera do innych celów; uruchomienie serwera FTP - w celu kradzieży plików, dezaktywacja oprogramowania antywirusowego - w celu przeprowadzenia dalszej mniej wyrafinowanej infekcji; przeprowadzanie z naszego komputera ataków odmowy usług - DoS oraz zbieranie i przesyłanie uderzeń w klawiaturę - keylogging.
Innymi rodzajami złośliwego oprogramowania są:
- Adware - oprogramowanie wyświetlające na często nachalne reklamy, najczęscięj treści tylko dla dorosłych.
- Ransomware - złośliwe oprogramowanie szyfrujące dyski i żądające okupu za wydanie klucza deszfrującego.
- Rootkit - oprogramowanie stosowane przez podmioty zagrożeń w celu uzyskania dostępu do konta administratora systemu.
- Spyware - oprogramowanie szpiegowskie, wykorzystywane w celu uzyskania osobistych informacji o użytkowniku.
- Robak - samoreplikujący się program wykorzystujący przy tym podatności. Najcześciej wykorzystuje on sieć do wyszukiwania systemów z tą samą podatnościa..
3.3.5. Ataki sieciowe
Ataki sieciowe, które mają stricte nie wiele wspólnego z siecią poza tym sieć jest medium przesyły informacji, mniej jednak możemy wróżnić takie ataki jak: ataki rozpoznania, ataki dostępu, czy ataki DoS.
Ataki rozpoznania zwykle polegają na poszukiwaniu hostów w sieci z wybraną przez nas podatnością, lub przeskanowaniem hostów w sieci pod kątem występowania podatności w ogóle i w zależności od tego co zostanie znalezione, to może to zostać wykorzystane. Tego typu atak możemy podzielić na:
- zapytanie informacyjne dotyczące celu - popularnym narzędziem na tym etapie są wyszukiwarki czy baza WHOIS (zawierająca informacje o domenie, czy przypisanej adresacji IP)
- wykrywanie aktywnych/osiągalnych hostów w sieci - w tej fazie czasami może wystarczyć zwykłe polecenie ping, szczególności jeśli działamy z sieci wewnętrznej.
- skanowanie portów osiąglanych hostów - kiedy już wiemy co możemy atakować, to wówczas musimy dowiedzieć się co jest na tych hostach uruchomione. Do tego mogą posłużyć nam skanery portów takie jak np. Nmap. Chciaż część skanerów podatności posiada również funkcję skanowania portów.
- skanowanie podatności - następną częścią jest wykrycie dziur w oprogramowaniu, z którym możemy się polączyć. Takim skanerem podatności jest np. Nessus.
- wykorzystanie podatności - po znalezieniu podatności pozostaje nam dobrać dla niej odpowiedni exploit, aby uzyskać zdalny dostęp do systemu. Takim narzędziem jest Metasploit.
- Ataki ICMP - podmiot zagrożeń może wykorzystać komunikaty protokołu ICMP, takie jak echo do odkrywania hostów, ataków DoS, czy innych komunikatów np. do wpływania na routing hostów.
- Ataki wzmacniania i odbijania - rodzaj ataku DoS, polegający na wysłaniu żądań echa z tym samym adresem źródłowym do wielu hostów. Wówczas zapytane hosty odpowiedzą atakowanemu hostowi zalewając go odpowiedziami echo.
- Ataki fałszowania - ataki pozwlajace fałszować informacje zawarte w nagłówkach przez co podmiot zagrożeń może podawać się za uprawnionego użytkownika. Nieślepe ataki fałszowania pozwalają ustalenia stanu zapory sieciowej oraz ustalenie numerów skewencyjnych przez co możliwe jest przechwycenie sesji.
- Ataki typu man-in-the-middle - Podmiot zagrożeń może umieścić się w komunikacji między źródłem a celem i transparentnie monitorować, przechwytywać i kontrolować komunikację. Może on sprawdzać pakiety, zmieniać ich zwartość i przekazywać dalej do celu.
- Przechwytywanie sesji - Podmiot zagrożenia uzyskuje dostęp do sieci fizycznej, następnie dokonuje ataku man-in-the-middle w celu przechwycenia sesji.
- Ataki na DNS typu open resolver - są w głównej mierze ataki DoS, takie jak: atak wzmacniania i odbijania lub atak wykorzystania zasobów DNS. Innym rodzajem ataku bo atakiem fałszowania jest atak zatrucia pamięci podręcznej, po którego nazwie możemy wywnioskować co robi i jaki będzie jego skutek.
- Ataki z ukrycia DNS - te ataki polegają szybkim manipulowaniu adresami IP DNS, aby ukryć strony wyłudzające informacje oraz roznoszące złośliwie oprogramowanie takimi atakami jest FastFlux oraz Double FastFlux. Działającym na innej zasadzie atakiem tego typu jest algorytm generowania domen, które potem stają się domem dla hostów kontrolujacyh botnety.
- Cieniowanie domeny DNS - jest technika polegającą uzyskaniu dostępu do konfiguracji domeny i utworzenie wielu subdomen, które mogą posłużyć poźniej do ataku.
- Tunelowanie DNS - technika pozwalająca na zawarcie jednego ruchu DNS wewnątrz drugiego, pozwala to na kradzież informacji lub komunikację z hostami botnetu wewnątrz chronionej sieci.
- Poufności - tylko upoważniony personel oraz procesy może mieć dostęp do poufnych informacji. Może być tutaj wymagane stosowanie silnego szyfrowania.
- Integralność - jest ochrona danych przed nieautoryzowanymi zmianami. Do tego wykorzystuje się różne kryptograficzne funkcje skrótu.
- Dostępność - jest zapewnienie nie przerwanego dostępu do ważnych zasobów przez uprzywilejowany personel. W tym celu będą potrzebne np. łącza, bramy oraz usługi nadmiarowe.
- Integralność danych - gwarantuje, że komunikat nie został zmieniony, zapewniają to algorytmy skrótów MD5 oraz SHA.
- Uwierzytleniania pochodzenia - gwarantuje, że wiadomość pochodzi z zaufanego i legalnego źródła, zapewnia to protokół HMAC.
- Poufność danych - gwarancja, że przesyłane informacje nie zostaną przez nikogo odczytane. Zapewniają to algorytmy szyfrowania asymentrycznego i symetrycznego.
- Niezaprzeczalność danych - gwarancja, że nadawca nie będzie mógł odrzucić lub zaprzeczyć wysłanej wiadomosci. Nadawca ma unikalne cechy, określające sposób traktowania takiej wiadomości.
- MD5 z 128-bitowym odciskiem - jest to funkcja jednokierunkowa generująca 128-bitowy komunikat. Obecnie MD5 jest wykorzystywane tylko tam gdzie jest to konieczne, ponieważ istnieją lepsze alternatywy.
- Algorytm SHA-1 - algorytm ten jest uznawany za przestarzały i posiada znane wady. Generuje 160 bitowy komunikat. Obecnie jest zastępowany przez generację funkcji sktóru SHA-2.
- SHA-2 - obejmuje kilka algorytmów takich jak np. SHA-256 czy SHA-512. Te algorytm to standard i powinny być stosowane jeśli tylko są dostępne.
- Ogranicznie ruchu w celu zwiększenia wydajności sieci.
- Zapewnienie kontroli przepływu.
- Zapewnienie podstawowych zabezpieczeń podczas dostępu do sieci.
- Filtrowanie ruchu w oparciu o typ ruchu.
- Kontrolowanie hostów aby zezwolić lub zablokować dostęp do sieci.
- Zapewnienie priorytetu określonym klasom ruchu sieciowego.
- Standardowe ACL - ACL filtruje tylko w warstwie 3, na podstawie adresu źródłowego.
- Rozszerzone ACL - ACL może filtrować w warstwie 3 lub 4 na podstawie adresu źródłowego lub docelowego, protokołu, czy numeru portu.
- any - 255.255.255.255
- host - 0.0.0.0. Przyczym słowo host zapisujemy przez adresem IP hosta.
- Opierać listy ACL na zasadach bezpieczeństwa organizacji.
- Określić co ma robić konkretna lista ACL.
- Użyć edytora tekstu, aby tworzyć, edytować i zapisywać wszystkie listy ACL.
- Dokumentować listy ACL za pomocą polecenia remark.
- Testować listy w sieci testowej przed zastosowaniem jest w sieci produkcyjnej.
- Standardowe ACL - ich kryteria dopasowania dotyczną jedynie adresów źródłowych (działają w warstwie 3).
- Rozszerzone ACL - działają w warstwie 4, w jednej regule możemy zapisać do 5 warunków: protokoł (najczęściej TCP lub UDP), adres, port - źródłowy, adres, port - docelowy.
- ACL standardowe - umieszczamy jak najbliżej celu.
- ACL rozszerzone - umieszczamy jak najbliżej źródła.
access-list-number- numer listy ACL, dla standardowych list jest od 1 do 99 lub 1300 do 1999.deny- odmowa dostępu, jeśli warunek został spełniony.permit- udzielenie dostępu, jeśli warunek został spełniony.remark text- opcjonalny komentarz dla celów dokumentacji. Długość komentarza jest ograniczona do 100 znaków.source- określa adres sieci hosta źródłowego do filtrowania. Tutaj możemy posłużyć się, słowem kluczowym any, aby określić wszystkie sieci oraz słowem kluczowym host ip-address lub poprostu ip-address, aby zidentyfikować konkretny adres IP.source-wildcard- opcjonalna 32-bitowa maska blankietowa stosowana dla adresów źródłowych. Jeśli zostanie pominięta, zakłada się domyślną maskę 0.0.0.0.log- opcjonalne słowo kluczowe generujące i wysłające komunikat gdy ACE (wpis w ACL) zostanie dopasowany. Wysyłany komunikat zawiera numer ACL, dopasowany warunek (permit or deny), adres źródłowy oraz liczbę pakietów. Komunikat generowany jest dla pierwszego pasującego pakietu. Wysyłanie komunikatów powinno być stosowane wyłączenie w celach diagnostycznych lub ze względów bezpieczeństwa.- Klasa A - 10.0.0.0 - 10.255.255.255 - 10.0.0.0/8
- Klasa B - 172.16.0.0 - 172.31.255.255 - 172.16.0.0/12
- Klasa C - 192.168.0.0 - 192.168.255.255 - 192.168.0.0/16
- Wewnętrzny lokalny (Inside local) - adres źródła widziany z perspektywy wnętrza sieci. Zwykle jest to prywatny adres IPv4.
- Wewnętrzny globalny (Inside global) - adres źródła widziany z zewnątrz sieci. Jest to zazwyczaj globalnie rutowalny adres IPv4.
- Zewnętrzny globalny (Outside global) - adres docelowy widziany z zewnątrz sieci. Jest adresm IPv4 globalnie rutowalny przypisanym hostowi w Internecie.
- Zewnętrzny lokalny (Outside local) - Adres docelowy widziany z perspektywy wnętrza sieci. Nie jest to powszechnie praktykowane, ale adres ten może być inny niż adres publiczny.
- Mapowanie jeden do jeden między adresami wewnętrznymi lokalnymi a wewnętrznymi globalnymi.
- Używa tylko adresów IPv4 w procesie translacji.
- Unikalny adres wewnętrzny globalny jest wymagany, dla każdego wewnętrznego hosta łączącego się z siecią zewnętrzną.
- Jeden adres wewnętrzny globalny można mapować na wiele adresów wewnętrznych.
- Używa adresów IPv4 i numerów portów źródłowych TCP lub UDP w procesie translacji.
- Pojedynczyny unikalny adres wewnętrzny globalny, może być wspołdzielony przez wiele wewnętrznych hostów łączących się z siecią zewnętrzną.
- Zmniejszenie zapotrzebowania na publiczne adresy IP.
- Zwiększenie elastyczności połączenia z siecią zewnętrzną.
- Zapewnienie spójności schematów adresowania.
- Ukrycie adresów IPv4 użytkowników i urządzeń sieci lokalnej.
- Wydajność sieci, szczególnie widoczna w protokołach czasu rzeczywistego takich VoIP.
- Translacje z adresu prywatnego na prywatny.
- Utrata adresowania end-to-end, co może powodować zaburzenie działania aplikacji bezpieczeństwa, np. podpisu elektronicznego.
- Utrata śledzenia pakietów IP end-to-end.
- Komplikacje podczas używania protokołów tunelowania - przez ingerencje w pakiety.
- Zakłócenie działania protokółów inicjujących połączenia TCP z zewnątrz (FTP), czy protokołów bezstanowych UDP.
- show ip nat translations - wyświetlenie tablicy
NAT-u, w przypadku NAT-u statycznego, mimo że nie było żadnych
połączeń to i tak zawiera ona mapowania.
Router# show ip nat translations Pro Inside global Inside local Outside local Outside global --- 209.165.201.5 192.168.10.254 --- --- Total number of translations: 1
W tablicy znajdują się kolumny, które powinniśmy znać z początku rozdziału, dodatkową kolumną jestPro, oznaczająca protokół. Tablicę można wyczyścić za pomocą polecenia:clear ip nat translations *, gwiazdka (*) oznacza, że należy wyczyścić tablicę dla obu kierunków - inside oraz outside. Polecenie to wydaje w trybie uprzywilejowanym EXEC. - show ip nat statistics - wyświetlenie statystyk
dotyczących NAT-u. To polecenie wyświetla nam ilość połaczeń, w
których zostały zamienione adresy.
Router# show ip nat statistics Total active translations: 1 (1 static, 0 dynamic; 0 extended) Outside interfaces: Serial0/1/1 Inside interfaces: GigabitEthernet0/2 Hits: 0 Misses: 0 ...
Podczas interpretacji wyniku tego polecenia powinno, nam najbardziej zależeć na linii:Hits: 0 Misses: 0. Pokazują one w ilu połączeniach zostały zmienione adres (Hits:), oraz ile połączeń nie udało się zrealizować (z różnych powodów) - (Misses:). - Połaczenie punkt-punkt - połaczenie łączące dwa punkty siecią rozległą. Dla stron w komunikacji rozwiązanie tego typu jest transparente. Najczęściej jest nim dzierżawiona linia abonencka.
- Topologia Hub-and-spoke - topologią umożliwiająca łączność mniejszych sieci za pośrednictwem tylko i wyłącznie jednego punktu centralnego.
- Topologia dual-homed - jest to zwielokrotniona topologia Hub-and-spoke, niewelująca wadę poprzedniej topologii, jaką był pojednyczy punkt awarii. Topologia ta zawiera zwielokrotnione punkty centralne (podwójne) oraz dodatkowe łącza z mniejszych sieci (po dwa na sieć).
- Topologia pełnej siatki - jest połączenie każdy z każdym. Topologia jest drogą w budowie, ale zapewnia najlepsze warunki podwzględem niezawodności i wydajności.
- Topologia siatki niepełnej - jest topologia zapewniająca pewien procent, nadmiarowych łączy pomiędzy węzłami sieci, jednak nigdy nie będzie to 100%, tj. każdy z każdym (topologia pełnej siatki). Mimo to taka topologia może zapewnić komunikację miedzy wszystkimi urządzeniami.
- Synchronus Digital Hierarchy (SDH),
- Synchronus Optical Networking (SONET),
- Dense Wavelength Division Multiplexing (DWDM).
- Połączenia szerokopasmowe (tj. DSL i kablowe),
- Łączność bezprzewodowa,
- Ethernet WAN,
- Multiprotocol Label Switching (MPLS).
- Urządzenie końcowe (DTE) - urządzenie abonenta, zazwyczaj jest to router, jednak równie dobrze może to być serwer.
- Urządzenie komunikacyjne (DCE) - urządzenie najczęściej dzierżawione lub przezkazane przez operatora na czas świadczenia usługi. Urządzenie jest dostosowane do medium stosowanego przez operatora i służy do komunikacji z jego siecią.
- Urządzenia końcowe użytkownika (CPE) - termin określający urządzenie lub zestaw urządzeń przekazanych do abonenta. Abonent może dzierżawić CPE lub być ich właścicielem. Mianem CPE określa się zbiorczo DCE i DTE oraz często samego abonenta.
- Punkt obecności (POP) - punkt, w którym abonament łączy się z usługodawcą.
- Punkt graniczy (punkt demarkacyjny) - skrzynka z kablowaniem, znajdująca się na terenie abonenta łącząca CPE do lokalnej pętli.
- Pętla lokalna (ostatnia mila) - fizyczne połączenie łącze CPE do CO usługodawcy, może być to kabel miedziany lub światłowód.
- Biuro centralne (Central Office - CO) - lokalny obiekt usługodawcy lub budynek łączący CPE z siecią usługodawcy.
- Sieć płatna - dedydkowane łączą komunikacyjne wykorzystujące infrastrukturę usługodawcy.
- Sieć dostępowa - sieć połączonych ze sobą punktów dostępowych do sieci usługodawcy. Sieci tego typu obejmują powiaty, województwa lub regiony.
- Sieć szkieletowa - sieci o dużej pojemności wykorzystywane do łączenia sieci dostawcy usług i tworzenia sieci nadmiarowych.
- Protokół PPP może zapewnić uwierzytelnianie abonenta.
- PPP może przypisać adres publiczny IP.
- PPP zapewnia zarządzanie jakością łączy.
- Fiber to the Home (FTTH) - najpopularniejsza opcja. Operator podłącza nam światłowód w mieszkaniu, wówczas naszym DCE może być konwerter optyczny, pozwalający podłączyć się do sieci światłowodowej zwykłą skrętką.
- Fiber to the Building (FTTB) - światłowód do budynku, np. do bloku (domu wielorodzinnego).
- Fiber to the Node/Neighborhood (FTTN) - światłowód do węzła optycznego na osiedlu.
- Miejska sieć bezprzewodowa - pozwala na uzyskanie dostępu do Internetu z wykorzystaniem takich samych technologii, jak WLAN. Wymaga jednak zakupu anten kierunkowych.
- Sieć komórkowa - wykorzystanie sieci komórkowej jest wstanie zapewnić szybki dostęp do Internetu. W tym przypadku wymagany jest zakup routera ze specjalnym modemem, do którego wkładana jest karta SIM. Sieć LTE (4 generacji) oraz 5 generacji (tzw. 5G) mogą osiągać przepustowości rzędu setek megabitów na sekundę. Taki bezprzewodowy światłowód.
- Dostęp satelitarny - drogi oraz nie zbyt szybki dostęp do sieci Internet. Zaletą tej technologii jest to, że zadziała w każdym możlwiwym miejscu na ziemi.
- Oszczędność wydatków
- Bezpieczeństwo
- Skalowalność
- Kompatybilność z technologiami szerokopasmowymi
- IPSec VPN
- GRE przez IPSec
- Cisco Dynamic Multipoint Virtual Private Network (DMVPN)
- Interfejs wirtualnego tunelu IPsec (VTI)
- Połączenie IPSec oparte na kliencie.
- Bezklientowe połączenie SSL.
- MPLS VPN Warstwy 3 - dostawca usług uczestniczy w kierowaniu klientów przez ustanowienie komunikacji równorzędnej między ruterami klienta i routerami dostawcy.
- MPLS VPN Warstwy 2 - usługodawca nie jest zanagażowany w routing klienta. Zamiast tego dostawca wdraża usługę wirtualnej prywatnej sieci LAN (VPLS), aby emulować wielodostępny segment sieci LAN Ethernet w sieci MPLS. Routery klienta należą wówczas do tej samej sieci wielodostępowej.
- Poufność - IPsec wykorzystuje algorytmy szyfrowania, aby uniemożliwić cyberprzestępcom odczytanie zawartości pakietu.
- Integralność - IPsec używa algorytmów mieszania, aby zapewnić, że pakiety nie zostały zmienione między źródłem a miejsce docelowym.
- Uwierzytelnianie pochodzenia - IPsec używa protokołu Internet Key Exchange do uwierzytelnienia źródła i miejsca docelowego. Metody uwierzytelniania, w tym korzystanie z klucz wstępnych (haseł), certyfikatów cyfrowych lub certyfikatów RSA.
- Algorytm Diffie-Hellman - Bezpieczna wymiana kluczy, wykorzystując różne grupy algorytmu DH.
- Protokołu IPsec - tutaj mamy do wyboru: nagłówek uwierzytelniania (AH), Encapsulation Securty Protocol (ESP). AH uwierzytelnia pakiety warstwy 3, a ESP je szyfruje. Kombinacja ESP+AH jest rzadko używana, gdyż nie jest w stanie przejść przez NAT.
- Poufność - szyfrowanie zapewnia poufność pakietu w.3. Do wyboru mamy DES, 3DES, AES oraz SEAL.
- Integralność - zapewnia, że dane dotrą w niezmienionej postaci do miejsca docelowego za pomocą algorytmu haszującego, takiego jak MD5 lub wariant SHA (SHA-256).
- Uwierzytelniania - Protokół IPsec używa usługi Internet Key Exchange (IKE) do uwierzytelnienia użytkowników i urządzeń, które mogą prowadzić komunikację niezależnie. IKE używa kilku rodzajów uwierzytelnienia w tym nazwa użytkownika, hasło, jednorazowe hasło, dane biometryczne, klucze wstępne (PSKs) oraz certyfikaty RSA.
- Diffie-Hellman - Protokół IPsec używa algorytmu DH w celu udostępnienia metody wymiany klucz publicznych dla dwóch peerów w celu ustanowienia wspolnego tajnego klucza. Isnieje kila różnych grup do wyboru, w tym DH14, 15, 16 i DH 19, 20, 21 i 24. DH1, 2 i 5 nie są już zalecane.
- Przepustowość - liczba bitów, którą można przesłać w ciągu jednej sekundy. Innym określenie z jakim możemy się spotkać jest szerokość pasma.
- Opoźnienie - jest to czas z jakim podróżuje pakiet od źródła do miejsca docelowego. Istnieją dwa rodzaje opóźnienia. Opóźnienie stałe (o stałej wartości czasu) oraz zmienne, którego czas może być nie dokońca określony. Opóźnienie zmienne, może mieć wpływ na takie czynniki ilość przysyłanego ruchu.
- Jitter - jest to potoczna nazwa dla zmiennego opóźnienia. Pakiety w komunikacji sieciowej są przesyłane w równych odstępach. Jednak przeciążenie sieci, niewłaściwe kolejkowanie czy błędy w konfiguracji mogą doprowadzić zmiennej długości odstępów między pakietami.
- Opóźnienie kodu - stała ilość czasu potrzebna do skompresowania danych przed wysłanie i wysłaniem jej do pierwszego urządzenia.
- Opóźnienie pakietowania - Stały czas potrzebny do enkapsulacji pakietu ze wszystkimi niezbędnymi informacjami w nagłówkach.
- Opóźnienie kolejkowania - zmienna ilość czasu, w której pakiet lub ramka czeka na przesłanie na łączu.
- Opóźnienie serializcji - stała ilość czasu potrzebna na przesłanie ramki przez okablowanie.
- Opóźnienie propagacji - zmienne ilość czasu potrzebna na przejście ramki od nadawcy do odbiorcy.
- Opóźnienie eliminacji jittera - Stała ilość czasu potrzebna na zbuforowanie przełpływu pakietów, a następnie przesłanie ich w równych odstępach.
- Czy dane podchodzą z aplikacji interaktywnej?
- Czy dane są krytyczne?
- First In First Out (FIFO)
- Ważone uczciwe kolejkowanie (Weighted Fair Queuing - WFQ)
- Uczciwe kolejkowanie oparte na klasach (Class-Based Weighted Fair Queuing - CBWFQ.
- Kolejkowanie o niskim opoźnieniu (Low Latency Queuing - LLQ).
- Model best-effort
- Usługi zintegrowane (IntServ)
- Usługi zróżnicowane (DiffServ)
- Model best-effort - To tak naprawdę nie jest implementacja, ponieważ QoS nie jest jawnie skonfigurowana. Można użyć tej metody gdy jakość usług nie jest wymagana.
- Usługi zintegrowane (IntServ) - IntServ zapewnia bardzo wysoką jakość usług dla pakietów IP z gwarantowaną dostawą. Definiuje proces sygnalizacji dla aplikacji w celu zasygnalizowania sieci, że wymagają specjalnego QoS przez pewien okres i że przepustowość powinna być zarezerewowana. IntServ może poważnie ograniczyć skalowalność sieci.
- Usługi zróżnicowane (DiffServ) - DiffServ zapewnia wysoką skalowalność i elastyczność we wdrażaniu QoS. Urządzenia sieciowe rozpoznają klasy ruchu i zapewniają różne poziomy jakości usług do róznych klas ruchu.
- Zwiększ pojemność łącza, aby ułatwić lub zapobiec zatłoczeniu.
- Zapewnij wystarczającą przepustowość i zwiększ przestrzeń buforową, aby pomieścić impulsy ruchu z delikatnych przypływów. WFQ, CBWFQ i LLQ mogą zagwarantować przepustowość i zapewnić priorytetowe przekazywanie do aplikacji wrażliwych.
- Utrata pakietów o niższym priorytecie przed wystąpieniem zatorów Cisco IOS QoS zapewniają mechnizmy kolejkowania, takie jak ważone losowe wczesne wykrywanie (WRED), które rozpoczynają odrzucanie pakietów zanim wystąpi przeciążenie.
- Narzędzia do klasyfikacji i znakowania - Sesje lub przepływy są analizowane w celu określenia, która klasa ruchu jest do nich przydatna. Po określeniu klasy ruchu pakiety są oznaczone.
- Narzędzia do unikania zatorów - Na klasy ruchu przydzielane są porcje zasobów sieciowych, zgodnie z zaleceniami przez badanie QoS. Zasady QoS określają również, w jaki sposób część ruchu może być selektywna utracona, opóźniona lub ponownie oznaczona, aby uniknąć zatorów. Głównym narzędziem do unikania przeciążenia WRED i służy do regulacji ruchu danych TCP w sposób efektywny pod względem przepustowści, za nim wystąpi tail drop spowodowane przepełnieniem kolejki.
- Narzędzia do zarządzania zatorami - Gdy ruch przekracza dostępne zasoby sieciowe, jest umieszczany w kolejce w oczekiwaniu na dostępność zasobów. Wspólne narzędzia do zarządzania ograniczeniami oparte na systemie Cisco IOS obejmują CBWFQ i algorytmy LLQ.
- Ethenet(802.1Q, 802.1p) - warstwa: 2, znakowanie pola: Klasa usług (CoS), Szerokość w bitach: 3
- 802.11 (Wi-Fi) - warstwa: 2, znakowanie pola: Identyfikator ruchu Wi-Fi (TID), szerokość w bitach: 3
- MPLS - warstwa: 2, znakowanie pola: Eksperymentalne (EXP), szerokość w bitach: 3.
- IPv4 i IPv6 - warstwa: 3, znakowanie pola: Pierwszeństwo IP (IPP), szerokość w bitach: 3.
- IPv4 i IPv6 - warstwa: 3, znakowanie pola: DSCP (Differentiated Services Code Point), Szerokość w w bitach: 6.
- Wartość CoS: 0 - binarnie: 000, dane best-effort.
- Wartość CoS: 1 - binarnie: 001, dane o średnim priorytecie.
- Wartość CoS: 2 - binarnie: 010, dane o wysokim priorytecie.
- Wartość CoS: 3 - binarnie: 011, sygnalizacja połączeń.
- Wartość CoS: 4 - binarnie: 100, wideokonferencje.
- Wartość CoS: 5 - binarnie: 101, nośnik głosu (ruch głosowy).
- Wartość CoS: 6 - binarnie: 110, zarezerwowane.
- Wartość CoS: 7 - binarnie: 111, zarezerwowane.
- Best-effort (BE) - domyślny tryb dla wszystkich pakietów IP. Wartość DSCP wynosi 0. Gdy router doświadczy przeciążenia, pakiety te zostaną usunięte. Nie wdrożono planu QoS.
- Przyspieszone przekazywanie (Expedited Forwarding - EF) - RFC 3246 definiuje EF jako wartość dzięsiętną DSCP 46 (binarna 101110). Pierwsze trzy bity odwzorowują bezpośrednio wartość 5 CoS warstwy 2 używaną do ruchu głosowego. W warstwie trzeciej zaleca używanie EF tylko do oznaczania pakietów głosowych.
- Zapewnione przekazywanie (Assured Forwarding - AF) - RFC 2597 definiuje AF, aby używać 5 najważniejszych bitów DSCP do wskazywania kolejek i preferencji utraty pakietów.
- Klasa 4 - niski spadek: AF41 (34), średni spadek: AF42 (36), wysoki spadek: AF43 (38).
- Klasa 3 - niski spadek: AF31 (26), średni spadek: AF32 (28), wysoki spadek: AF33 (30).
- Klasa 2 - niski spadek: AF21 (18), średni spadek: AF22 (20), wysoki spadek: AF23 (22).
- Klasa 1 - niski spadek: AF11 (10), średni spadek: AF22 (12), wysoki spadek: AF13 (14).
- Pierwsze 3 najbardziej znaczące bity są używane do wyznaczania klasy. Klasa 4 to najlepsza kolejka, a klasa 1 to najgorsza kolejka.
- Czwarty i piąty najbardziej znaczący bit są używane do określenia preferencji gubienia pakietów.
- Szósty najbardziej znaczący bit jest ustawiony na zero.
- Zaufane punkty końcowe mają możliwość do oznaczania ruchu aplikacji do odpowiednich wartości CoS warstwy 2 i/lub DSCP warstwy 3. Przykłady zaufanych punktów końcowych obejmują telefony IP, bezprzewodowe punkty dostępowe, bramy i systemy wideokonferencyjne, stacje konferencyjne IP i inne.
- Bezpieczne punkty końcowe mogą mieć ruch oznaczony na przełączniku warstwy 2.
- Ruch można również oznaczać na przełącznikach/routerach warstwy 3.
- Włącz kolejkowanie na każdym urządzeniu na ścieżce między źródłem a celem.
- Klasyfikuj i oznaczaj ruch tak blisko źródła jak to możliwe.
- Ukształtowany ruch objęty polityką QoS przepływa jak najbliżej swoich źródeł.
- Identyfikator urządzenia
Device ID- nazwa hosta urządzenia sąsiada. - Identyfikator portu - jest to nazwa portu lokalnego
(
Local Intrfce) oraz portu zdalnego (Port ID). - Lista możliwości
(
Capability) - rodzaj urządzenia (S- przełącznik). - Platforma -
Platform- jest to platforma urządzenia. - Menedżera SNMP
- Agenci SNMP (węzeł zarządzany)
- Baza danych zarządzania (MIB)
- SNMPv1 - poziom: NoAuthNoPriv, uwierzytelnianie: community string, szyfrowanie: nie. Używa dopasowania community string do uwierzytelniania.
- SNMPv2c - patrz: SNMPv1.
- SNMPv3 NoAuthNoPriv - poziom: NoAuthNoPriv uwierzytelnianie: nazwa użytkownika, szyfrowanie: nie. Używa dopasowania nazwy użytkownika do uwierzytelnienia (ulepszenie w stosunku do SNMPv2c).
- SNMPv3 AuthNoPriv - poziom: AuthNoPriv, uwierzytelnianie: MD5 lub SHA, szyfrowanie: nie. Zapewnia uwierzytelnianie oparte na algorytmach HMAC-MD5 lub HMAC-SHA.
- SNMPv3 AuthPriv - poziom: AuthPriv (wymaga wersji IOS z rozszerzenie kryptograficznym), uwierzytelnianie: MD5 lub SHA, Szyfrowanie: DES lub AES. Zapewnia uwierzytelnianie oparte na algorytmach HMAC-MD5 lub HMAC-SHA. Umożliwia określenie modelu bezpieczeństwa (USM) z algorytmami szyfrowania DES i AES.
- Tylko do odczytu (ro) - ten typ zapewnia dostęp do zmiennych MIB, ale nie pozwala na ich zmianę.
- Odczyt i zapis (rw) - ten typ zapewnia możliwość odczytania zawartości zmiennych MIB oraz ich modyfikacji.
- Możliwość zbierania rejestrowania informacji na potrzeby monitoringu i rozwiązywania problemów.
- Możliwość wyboru rodzaju informacji rejestrowanych, które mają zostać przechwycone.
- Możliwość zdefiniowania odbiorców przechwytywanych informacji syslog.
- Nagła sytuacja - poziom: 0 - System nie nadaje się do użytku.
- Alarm - poziom: 1 - Potrzebne natychmiastowe działanie.
- Krytyczne - poziom: 2 - Stan krytyczny.
- Błąd - poziom: 3 - Stan błedu.
- Ostrzeżenie - poziom: 4 - Stan ostrzegawczy.
- Powiadomienie - poziom: 5 - Stan normalny, ale istotny.
- Informacyjny - poziom: 6 - Komunikat informacyjny.
- Debugowanie - poziom: 7 - Komunikat debug.
- IP
- OSPF
- system operacyjny (SYS)
- Zabezpieczenia na poziomie IP
- Interfejs IP
- Wejść w tryb ROMMON.
Jest tak jakby dostęp do urządzenia z poziomu programu ładującego. Aby wejść w ten tryb należy albo nacisnąć Ctrl+Break (dla programu PuTTY), zaraz po podłączeniu urządzenia do prądu. Drugą możliwością jest usunięcie zewnętrznej pamięci Flash gdy urządzenie jest wyłączone. - Zmienić rejestr konfiguracji.
Tryb ROMMON jest dość biednie wyposarzony, ale obsługuje jedno interesujące nas polecenie - jest nim confreg. Jako argument tego polecenia podajemy wartość 0x2142. Ten tryb wymusi na IOS, aby ten nie ładował konfiguracji z NVRAM-u, udostępnił czysty nie skonfigurowany system. Po zmianie rejestru wznawiamy ładowanie systemu operacyjnego poleceniem reset. - Skopiować konfigurację startowa do bierzącej.
To tutaj odbywa się cała magia. Za pomocą zmiany tryby mamy pełen dostęp do urządzenia bez hasła, teraz więc możemy załadować konfigurację, w której znajduje się zapomniane hasło i je zmienić. System nas nie wyloguje, nie wyrzuci, ani nie zapyta o stare hasło. - Zmienić hasło.
- Skopiować bierzącą konfigurację do startowej.
Przed tą czynnością można już przywrócić normalny tryb rozruchu, tym razem konfigurując rejestr już z poziomu systemu za pomocą poleceniaconfig-registerprzy użyciu argumentu 0x2102. - Załadować ponownie urządzenie
- Hierarchiczność - wykorzystanie lub stworzenie projektu, który pozwoli na określenie roli każdego urządzenia w każdej warstwie, uprości wdrożenie, obsługę i zarządzanie oraz redukuje domeny błedów na każdej z warstwa.
- Modułowość - Konstrukcja umożliwia bezproblemową rozbudowę sieci i wyłączenie zintegrowanych usług na żądanie.
- Odporność - projekt musi spełniać oczekiwania użytkowników w zakresie utrzymania sieci zawsze włączonej.
- Elastyczność - Konstrukcja umożliwia inteligente dzielenie obciążenia ruchu przy użyciu wszystkich zasobów sieciowych.
- Warstwa dostępu - reprezeuntuje ona brzeg sieci, w którym ruch wychodzi lub wchodzi do niej. Podstawowym funkcją przełącznika warstwy dostępu jest zapewnie użytkownikowi dostępu do sieci.
- Warstwa dystrybucji - warstwa między warstwą dostępu, a warstwą rdzeniową. Zapewnia takie funkcje jak różnego rodzaju agregacje, wyznaczanie granic routingu, zapewnienie intligentnego przełącznia i routingu oraz dostępności i nadmiarowości Dostarcza również rózne usługi dla różnych klas aplikacji.
- Warstwa szkieletowa - szkielet łączy poszczególnych warstw, dla których służy głównie jako agregator. Jej główną funkcją jest izolacja błedów oraz zapewnienie bardzo szybkiej łączności pomiędzy warstwami.
- Korzystaj z rozszerzalnego sprzętu lub urządzeń w klastrze, które można łatwo zaktualizować w celu zwiększenia możliwości.
- Zaprojektuj hierarchiczna się tak, aby zawierała moduły, które w razie potrzeby można dodawać, ulepszać i modyfikować bez wpływu na projekt innych obszarów sieci.
- Utwórz hierarchiczną strategię adresów IPv4 i IPv6.
- Jeśli to możliwe wybierz routery działające na różnych warstwach modelu OSI (wielowarstowe) w celu ograniczenia domeny rozgłoszeniowych i filtrowania pozstałego niepożądanego ruchu w sieci.
- Routery dla oddziałów - optymalizują na jednej platformie obsługę aplikacji w oddziałach i infrastrukturach WAN.
- Routery brzegowe - umożliwiają brzegowi sieci dostarczenie wysokowydajnych, wysoce bezpiecznych i niezawodnych usług, które łączą kampus, centrum danych i sieć oddziałów.
- Routery dostawców usług sieciowych - zapewniają kompleksowe, skalowalne rozwiązania i usługi dostosowane do abonentów.
- Przemysłowe - są zaprojektwane tak, aby zapewniać funkcję klasy korporacyjnej w trudnych i bardzo trudnych warunkach.
- Diagramy fizycznej i logicznej topologii sieci.
- Dokumentacja urządzenia sieciowe rejestrująca wszystkie istotne informacje o urządzeniu.
- Dokumentacja bazowa wydajności sieci.
- Nazwę urzadzenia
- Lokalizację urządzenia (adres, numer pokoju, lokalizaję szafy)
- Interfejs i używane porty
- Typ okablowania
- Identyfikatory urządzeń
- Adresy IP i długości prefiksów
- Identyfikatory interfejsu
- Protokół routingu / trasy statyczne
- Informacje warstwy 2 (tj. sieci VLAN, połączenia trunk, EtherChannel
- Jak sieć funkcjonuje podczas normalnego lub typowego dnia?
- Gdzie może wystąpić najwięcej błędów?
- Która część sieci jest najintensywniej wykorzystywana?
- Która część sieci jest najmniej wykorzystywana?
- Jakie urządzenia należy monitorować i jakie progi alarmowe należy ustawić?
- Czy sieć może spełniać określone zasady?
- Określić jakie typu dane trzeba zebrać, aby analiza była łatwa ale zarazem miarodajna.
- Zindentyfikować interesujące urządzenia i porty, na który powinien odbywać się pomiar. Mogą być to porty urządzeń sieciowych, serwery czy kluczowi użytkownicy.
- Określ czas zbieraniania danych, aby ustalić normalny obraz sieci.
- Etap 1: - zebranie objawów.
- Etap 2: - wyizolowanie problemu.
- Etap 3: - wdrożenie działań naprawczych.
- Zdefiniuj problem.
- Zbierz informacje.
- Analizuj informacje.
- Wyeliminuj możliwe przyczyny.
- Zaproponuj hipotezę.
- Przetestuj hipotezę.
- Rozwiąż problem i udokumentuj rozwiązanie.
- Stosowanie języka technicznego na poziomie rozmówcy, unikanie złożonej terminologii.
- Skupienie się na komunikat przekazywanych przez użytkownika. Tworzenie notatek, może okazać się przydatne.
- Wykazanie się empatią, wobec zgłaszających.
pingtraceroutetelnet/sshshow ip interface briefshow ip route- Od dołu - rozwiązywanie problemów zaczynamy od dołu od fizycznych komponentów sieci i przechodzimy przez kolejne warstwy OSI.
- Od góry - rozwiązywanie problemów rozpoczynamy od użytkownika końcowego i przechodzi przez kolejne warstwy OSI.
- Dziel i rządź - w tej metodzie adminstrator wybiera jedną w warstw pośrednich następnie przeprowadza testy w obu kierunkach rozpoczynają od tej warstwy.
- Podążanie ścieżka - Podejście najpierw odkrywa rzeczyswitą drogę od źródła do miejsca docelowego. Zakres tego rozwiązania problemów jest ograniczony tylko do linków i urządzeń znajdujących się na ścieżce przesyłania dalej.
- Podmiana - w tym podjeściu fizycznie zamieniamy problematyczne urządzenie na znane działające.
- Porównanie - w tym podejściu próbujemy rozwiązać problem przez porównanie i zmiane elementów nieoperacyjnych z tymi działającymi.
- Zgadywanie na podstawie doświadczenia.
- System zarządzania siecią - systemy zarządzania siecią zawierają oprogramowanie do monitorowanie na poziomie urządzenia, konfiguracji i oraz zarządzania usterkami.
- Bazy wiedzy - bazy wiedzy online dostawców urządzeń sieciowych stały się przydatnym źródłem informacji. Często są zintegrowane z wyszukiwarkami.
- Narzędzia do tworzenia stanu odniesienia - Dostępnych jest wiele narzędzi służących do automatyzowania dokumentacji sieciowej oraz procesu stanu odniesienia. Narzędzia do pomiaru stanu odniesienia pomagają w wykonaniu typowych zadań związanych z dokumentacją sieci.
- Cyfrowy multimetr - badanie zasilania urządzeń, np. Fluke 179.
- Tester kabli - badanie długości oraz ciągłości przewodowów, np. Fluke LinkRunner AT.
- Analizator okablowania - testowanie oraz certyfikowanie kabli miedziany pod kątem różnych usług i standardów. np. Fluke DTX Cable Analyser.
- Przenośne analizatory sieci - rozwiązywanie problemów z sieciami przełączanymi i sieciami VLAN.
- Konsola
- Linie terminala
- Rejestrowanie buforowane
- Pułapki SNMP
- Syslog (zewnętrzna usługa)
- Wydajność poniżej poziomu odniesienia.
- Utrata łączności.
- Zatory lub przeciążenia w sieci.
- Wysokie wykorzystanie procesora.
- Komunikat o błędzie konsoli.
- Przyczyny związane z mocą.
- Usterki sprzętowe.
- Błędy okablowania.
- Tłumienie.
- Zakłócenia.
- Błędy konfiguracji interfejsu.
- Przekroczenie limitów projektowych.
- Przeciążenie CPU.
- Nieprawidłowe funkcjowanie brak łączności w warstwie sieci lub wyższej.
- Działanie sieci wyjściowej poniżej poziomów wydajności.
- Nadmierne rozgłoszenia.
- Komunikaty konsoli.
- Błędy enkapsulacji
- Błędy mapowania adresu
- Błędy ramek
- Błędy i pętle STP
- Awaria sieci
- Nieoptymalna wydajność
- Ogólne problemy z siecią
- Problemy z łącznością
- Tabela routingu
- Problemy z ustanowieniem sasiedztwa
- Baza danych topologii
- Problemy z łącznością
- Problemy z dostępem
- Konfiguracje ACL
- Konfiguracje NAT
- Wybór strumienia ruchu.
- Kolejność wpisów ACL.
- Domyślny deny any.
- Adres i maski blankietowe IPv4.
- Wybór protokołu warstwy transportowej.
- Porty źródłowe i docelowe.
- Użycie słowa kluczowego established.
- Rzadko używane protokoły
- Sprawdź fizyczne połącznie w punkcie, w którym zauważono przerwę w
komunikacji sieciowej. Obejmuje ono sprzęt i okablowanie. Problem
może być spowodowany przez uszkodzony przewód lub interfejs, albo
może dotyczyć nieskonfigurowanego lub wadliwego urządzenia.
Do badania warstwy fizycznej możemy wykorzystać takie polecenia jak:
show interfacesshow memoryshow processes cpu
- Sprawdź zgodność interfejsu, poleceniem
show interface. - Sprawdź adresację warstwy łącza danych i warstwy sieci lokalnej.
Należy skontrolować takie elememnty jak tablice ARP IPv4, tablicę
sąsiadów IPv6 tablicę MAC oraz przepisania do sieci VLAN. Polecenia:
arp -a(MS Windows)netsh interface ipv6 show neighbor(MS Windows)show arpshow mac address-table
- Upewnij się, że brama domyślna jest prawidłowo ustawiona. Polecenia:
show ip route | include Gateway|0.0.0.0netstat -rlubroute print(MS Windows).
- Upewnij się, że urządzenia ustalają prawidłową trasę od źródła do
celu. Jeśli to konieczne skorygować informacje o routingu.
Polecenia:
show ip/ipv6 route. - Sprawdź, czy warstwa transportowa działa prawiłowo, do tego można użyć polecenia telnet lub nc.
- Sprawdź, czy nie skonfigurowano list blokujących ACL. Polecenia:
show ip access-listsshow ip interface ifX/Y | include access list
- Upewnij się czy ustawienia DNS są prawidłowe. Przynajmniej jeden
serwer DNS powinien być osiągalny. Polecenia:
show running-configip host nazwa adres_ippingnslookup(MS Windows, Linux)
ip hostsłuży do tworzenia statycznych mapować nazw na adresy IP. - Umożliwia dostęp do danych organizacji w dowolnym miejscu i czasie
- Usprawnia operacje IT organizacji, subskrybując tylko potrzebne usługi.
- Eliminuje lub ogranicza potrzebę posiada sprzętu IT na miejscu, konserweracji i zarządzania.
- Zmniejsza koszty sprzętu, energii, fizycznych wymagań zakładu i potrzeb szkoleniowych personelu.
- Umożliwia szybkie reagowanie na rosnące zapotrzebowanie na dane.
- Oprogramowanie jako usługa (SaaS) - Dostawca chmury jest odpowiedzialny za dostęp do aplikacji i usług, takich jak poczta e-mail, komunikacja i usługa Office 365, które są dostarczane przez Internet. Użytkownik nie zarządza żadnym aspektem usług w chmurze, z wyjątkiem ograniczonych ustawień aplikacji specyficznych dla użytkownika. Użytkownik musi jedynie podać swoje dane.
- Platforma jako usługa (PaaS) - Dostawca chmury jest odpowiedzialny za zapewnienie użytkownikom dostępu do narzędzi programistycznych i usług używanych do dostarczenia aplikacji. Ci użytkownicy są zazwyczaj programistami i mogą mieć kontrole na ustawieniami konfiguracyjnymi środowiska hostingu aplikacji usług w chmurze. Infrastruktura jako usługa (IaaS) - Dostawca chmury jest odpowiedzialny za zapewnienie kierownikom IT dostępu do sprzętu sieciowego, zwirtualizowanych usług sieciowych i infrastruktury pomocnicznej. Korzystanie z tej usługi w chmurze umożliwia menedżerom IT wdrażanie i uruchamianie kodu oprogramowania który może obejmować systemy operacyjne i aplikacje.
- Chmury publiczne - Aplikacje i usługi oparte na chmurze oferowane ogółowi populacji. Usługi mogą być bezpłatne lub oferowane w modelu płatności za użycie.
- Chmury prywatne - Aplikacje i usługi przeznaczone dla określonej organizacj lub podmiotu, takiego jak rząd.
- Chmury hybrydowe - Chmura hybrydowa składa się z dwóch lub więcej modeli chmury. Może być częściowo publiczna oraz częściowo prywatna.
- Chmury społecznościowe - Chmury społecznościowe jest tworzona do wyłącznego użytku przez określoną społeczność.
- Centrum danych - zazwyczaj obiekt do przechowywania i przetwarzania danych prowadzonych przez wewnętrzny dział IT lub wynajmowany poza siedzibą firmy.
- Obliczanie w chmurze - zwykle usługa zewnętrzna, która oferuje dostęp na żądanie współużytkowanej puli zasobów obliczeń, które możemy dostosowywać do własnych potrzeb.
- Virtual PC
- VMWare Workstation
- Oracle VM VirtualBox
- VMware Fusion
- Mac OS X Parallels
- Płaszycznę sterowania - służy do podejmowania decyzji dotyczących przekazywania. Płaszczyzna sterowania odpowiedzialna jest za switching czy routing.
- Płaszczynę danych - zwykle struktura przełącznika łącząca różne porty sieciowe w urządzeniu. Płaszczyzna danych każdego urządzenia służy do przesyłania strumieni ruchu.
- Software-Defined Network - architektura sieci, która wirtualizuje sieć, oferując nowe podejście do administrowania siecią i zarządzania nią, które ma na celu uproszczenie i usprawnienie procesu administracyjego.
- Cisco Application Centric Infrastructure - Specjalnie zaprojektowane rozwiązanie sprzętowe do integracji przetwarzania w chmurze i zarządzania centrum danych.
- OpenFlow - zarządzanie ruchem miedzy urządzeniami, protokół jest podstawowym elementem budowania rozwiązań SDN.
- OpenStack - platforma wirtualizacji i orkiestracji zaprojektowana do budowania skalowalnych środowisk chmury i zapewnienia rozwiązania IaaS.
- Inne komponenty - I2RS, TRILL, Cisco FP i IEEE 802.1aq.
- Profil sieci aplikacji (ANP)
- Kontroler infrastruktury zasad aplikacji - APIC
- Przełączniki Cisco Nexus z serii 9000
- SDN na urządzeniu - urządzenia są programowalne przez aplikacje na samym urządzeniu lub na serwerze.
- SDN na kontrolerze - Ten typ sieci SDN wykorzystuje centralny kontroler, mający wiedzę o wszystkich urządzenia w sieci.
- SDN na zasadach - wariacja SDN-a opartego na kontrolerze, zawiera dodatkową warstwę abstrackcji do automatyzacji zaawansowanych zadań konfiguracyjnych.
- Składnia, która obejmuje typy używanych nawiasów takich jak [], (), {}, użycie białych znaków, cudzywsłowów i innych.
- Sposób reprezentowania obiektów, takich jak znaki, łańcuchy, listy i tablice.
- Sposób reprezentacji par klucz/wartość. Klucz jest zawsze po lewej stronie identyfikuje lub opisuje dane. Wartości po prawej stronie to same dane i mogą być znakiem, łańcuchem, liczbą, listą lub innym typem danych.
- JavaScript Object Notation - JSON
- YAML
- XML
- Otwarte/publiczne interfejsy API.
- Wewnętzne/prywatne interfejsy API.
- API dla partnerów.
- Simple Object Access Protocol - SOAP
- Representational State Transfer - REST
- eXtensible Markup Language-Remote Procedure Call - XML-RPC
- JavaScript Object Notation-Remote Procedure Call - JSON-RPC
- Ansible
- Chef
- Puppet
- Saltstack
Ataki dostępu służą wykorzystaniu podatności w funkcjach uwierzytelniania w celu uzyskania dostępu do kont czy to na portalach internetowych czy to do zasobów plikowych. Jednym z najcześciej stosowanych ataków jest atak na hasło stosowany w celu poznania krytycznych dla systemów haseł, tego rodzaju ataków dokonuje się poprzez programy do łamania haseł. Innym rodzajem ataków dostępu są ataki fałszowania, przeprowadzane w celu podszycia pod inne urządzenie i pozostania jak najdłużej niezauważonym, do tego rodzaju ataków możemy przypisać dobrze znane nam man-in-the-middle, wykorzystanie zaufania, przekierowanie portów czy przepełnienie bufora.
Przeprowadzenie ataków na hasła jest czaschonne i często nie przynosi skutków. Obecnie często nie ma sensu się tym zajmować przejmować ponieważ to często użytkownicy podają swoje dane logowania jak na tacy. Atakujący zazawyczaj posługują się wówczas socjotechnikami - są techniki manipulacyjne pozwalające na wprowadzenie, kogoś w błąd, aby móc wyłudzić od niego poufne informacje.
Jednym z takich metod jest phising - najprościej rzecz ujmując próba wyłudzenia informacji, po przez podanie fałszywego linku, z identyczną stroną logowania do jednego z serwisów. Strona tego typu różni się drobnymi szczególami, na które na codzień nie zwracamy uwagi, np. literówką w adresie strony. Ta strona moze kolekcjonować wpisane dane i przekazać je podmiotowi zagrożenia. Dlatego trzeb mieć się na baczności i zastanowić się dwa razy klikając w link dodany do dziwnej wiadomości e-mail. Ciekawym narzędziem w tym przypadu jest SET Social-Engineering Toolkit, pozwalający na przygotowanie ataków phishingowych w celu przetestowania własnych użytkowników.
Ataki DoS, inaczej ataki odmowy usługi polegają one na zalaniu serwera żądaniami dostępu do zasobu o bardzo dużej częstotliwości. Ten atak ma na celu pozbawienie dostępu do usługi prawowitym użytkownikom. Takie ataki są dość trudne w zapobieganiu, ponieważ w jaki sposób oddzielić taki atak od wzmożonej aktywności użytkowników? Tego typu ataki są często wykorzystywane przez haktywistów, manifestując tym samym społeczne nieposłuszeństwo. Takie ataki są rownież banalne do przeprowadzenia, ponieważ sposób ich przeprowadzania nie skupia się na jakości a na ilości, najcześciej standardowych żądań. Jeśli taki atak pochodzi z jednego adresu IP, to wówczas mamy doczynienia z atakiem DoS, ale jeśli zapytania przychodzą z różnych hostów to mówimy o wersji rozproszonej - DDoS.
3.3.6. Podatności i zagrożenia IP
Obecnie stosowane protokoły sieciowe nie były konstruowane z myślą o bezpieczeństwie, ponieważ wówczas bardziej kładziono nacisk na swobodę komunikacji. Dlatego też w protokołach IP możemy dowolnie manipulować polami nagłówków pakietów. Do najbardziej powszechnych ataków związanych z adresami IP możemy wymienić:
3.3.7. Podatności TCP i UDP
Podaności protokołów warstwy czwartej polegają na daniu możliwości zalania wybranego serwera - w przypadku protokołu TCP pakietami z ustawionym bitem kontrolnym SYN, lub datagramami w przypadku protokołu UDP. Wówczas jest taki komputer nie jest wstanie przetwarzać żądań uprawnionych do korzystania z niego, użytkowników. W przypadku protokołu TCP, dość kłopotliwe mogą być inne flagi czy też bity kontrolne, za pomocą pakietu z ustawionym bitem kontrolnym Fin oraz sfałszowanym adresem źródłowym możemy zresetować lub zakończyć połaczenie TCP, co może zaburzać zwykłym uzytkownikom korzystanie z usług. Innym rodzajem ataku opartego na TCP jest przjęcie sesji TCP, poprzez zdobycie pakietu źródłowego oraz odgadnięcie numeru sekewencji. UDP można wykorzystać podbnie jak TCP do zalewania hostów. Ze w zględu, że UDP nie ustala żadnego połączenia, serwer może podejść do sprawy w dwojaki sposób albo zignorować albo wysłać odpowiedź o nieosiągalnym porcie przez protokoł ICMP.
3.3.8. Usługi IP
Pierwszą usługą, która jest związana z IP i może powodować przykre skutki, jeśli zostanie wykorzystana w niecnym celu jest protokół ARP. Dzięki zatruwaniu ARP, podmiot zagrożenia może fałszować odwzrowania adresów IP na adresy MAC, co pozwoli na przkierowanie ruchu np. przez swój komputer, co daje nam man-in-the-middle. Co najciekawsze, protokół ARP przewiduje tzw. pakiet gratisowy, który wręcz wymusza aktualizację wpisu pamięci podręcznej ARP hosta. Do narzędzi pozwalających na tego typu ataki możemy zaliczyć takie programy jak dsnif, Cain&Abel czy ettercap.
System DNS pozwala nam na posługiwanie się w Internecie przyjaznymi nazwami, dzięki czemu wpisujemy morketsmerke.org a nie adresy IP. System DNS jest bardzo ważną częścią obecnych sieci, a bywa zaniedbany jeśli chodzi o funkcje bezpieczeństwa. Ataki na DNS, lub te z jego wykryciem, możemy podzielić na kilka kategorii.
Ostatnim rodzajem usług IP jakie mogą być podatne na ataki jest serwer DHCP. Są to albo ataki DoS w postaci zagłodzenia, lub fałszowania, gdzie do manipulacji wykorzystuje się takie parametry jak sam adres IP, żeby pozbawić użytkownika dostępu do sieci lub adres bramy oraz adresy serwerów DNS, aby przekierować ruch.
Laboratorium
3.3.9. Najlepsze praktyki bezpieczeństwa sieci
Chcąc dobrze zabezpieczyć naszą sieć musimy poznać nie tyle techniki jak się bronić prze konkretnymi atakami, ale musimy wypracować w nas czy użytkownikach naszej sieci pewne schematy działania, aby zapobiec powstawaniu głupich błędów. Trzeba sobie również uświadomić jedną rzeczy, że przed nie którymi atakami nie będzie możliwa ochrona, u innych uda nam się zminimalizować skutek wykorzystania podaności, a przed nie którymi nie uda nam się zabezpieczyć w ogóle. Ten temat jest poświęcony zapoznaniu się dobrymi przedsięwzięciami w celu ochrony naszej sieci.
W wielu organiazacjach stosuje się takie podejście do bezpieczeństwa jaką jest triada PID lub trójkąt CIA. Ta koncepcja składa się z trzech pojęć:
Inną praktyką jest dogłebne podejście do ochrony. Polega ono na podziale infrastruktury na warstwy, przy wykorzystaniu wielu urządzeń współpracujących między sobą, między innymi: tuneli VPN, inteligentych zapór sieciowych, systemów zapobiegania/wykrywania włamań, filtrów treści oraz systemów uwierzytelniania. Część z tych rozwiązań będzie fizycznymi urządzeniami, a część z nich usługami gdzieś na serwerach, należy wówczas pamiętać aby dołożyć wszelkich starać aby zabezpieczyć te komponenty, to samo tyczy się transmisji danych.
Zapory sieciowy to podstawowy mechanizm obronny, zaporę najczęściej ustawia się w punkcie styku sieci. Chroni ona hosty sieci lokalnej przed zagrożeniami z zewnątrz. Ważna jest dobra konfiguracja zapory, przeciwnym wypadku może być ona jednym wielki punktem awarii. Zapora odfiltrowuje na podstawie zestawu reguł nieporządany ruch, dopuszczając tylko ten potencjalnie bezpieczny. Jednak nie jest to rozwiązanie bez wad. Techniki tunelowania oraz inne metody ukrywające potrafią oszukać zaporę.
Technologie IDS/IPS są wyposażone w sensory, które na podstawie wzorców (sygnatur), potrafią wyłapywać typowe ataki sieciowe i gromadzić na ich temat informacje, które są potem przekazywane do administratora. Sygnaturą może być nawet pojedynczy pakiet lub niewieki fragment ich strumienia.
Filtry treści, możemy podzielić np. na podstawie protokółów są filtry zająmujące się samą pocztą elektroniczą i będące przekaźnikiem wiadmości i przy okazji skanującym je podkątem zagrożenia i ewentualnego odrzucenia. Firma Cisco posiada takie rozwiązanie i nazywa się ESA. Innym rodzajem filtru jest filtrowanie stron internetowych, ale i nie tylko bo za pomocą rozwiązań tego typu możemy decydować do czego użytkownik może mieć dostęp w Internecie w czasie pracy. Możemy tworzyć listy stron zablokowanych, filtrować ruch aplikacji internetowych, a nawet zaglądać do transmisji szyfrowanych, rozwiązaniem tego typu Cisco jest - WSA.
3.3.10. Kryptografia
Wykorzystując standardowe wersje protokołów sieciowych, treść ich komunikatów jest przesyłana w sposób jawny. Pozwala on bezproblemowe odczytanie ich treści. W sieci zaufanej nie stanowi to bowiem problemu, gorzej jest w przypadku kiedy trzeba informacje poza nią. Dawniej nikt nie przykładał do tego zbytniej uwagi, jednak czasy się zmieniły i już na pewno wiemy, że nie możemy ufać nikomu po drugiej stronie routera lub zapory i w przypadku komunikacji sieciowej możemy skorzystać z bezpiecznych wersji protokołów (szyfrowanych) lub z samych elementów kryptografii, zabezpieczejąc transmisje protokołu nie posiadającego bezpieczenej wersji przy użyciu dodatkowego tunelu.
W celu zabezpieczenie komunikacji wymagane są cztery elementy takie jak:
Sprawdzenie integralności danych, polega obliczeniu tzw. skrótu z podanej wiadomości przez obie strony komunikacji. Jeśli skrót jest taki sam po obu stronach ozaczna to tyle, że nie doszło do żadnej ingerencji z zewnątrz w wiadomość. Do obliczania skrótów używa się specjalnych funkcji skrótu.
Obecnie w kryptografi stosowane są trzy funkcje skrótu:
Funkcje skrótu są w stanie ochronić nas przed przypadkowymi zmianami, ale nie jeśli zmiany są celowe, wówczas podmiot zagrożeń może wygenerować nowy skrót dla zmienionych pakietów i przedstawić go jako skrót nadawcy.
Wyżej wymieniona wada była dość dużym problemem, z którym poradzono sobie dodając uwierzytelnienie do zapewnienia integralności za pomocą protokołu HMAC. Działanie tego algorytmu opera się uzupełenienie danych wejściowch do funkcji skrótu, o znanym przez strony tajny klucz. Wówczas atakujący nie będzie mógł ingerować w komunikację, ponieważ jego skróty generowane funkcję nie bedą posiadać znanego klucza i przy sprawdzaniu takie dane zostaną odrzucone.
Wyżej wymienione metody zapewniają integralność czy wiarygodność przesyłanych komunikatów, ale ich treść jest nadal dostęna dla osób postronnych. Kryptografia zapewnia nam dwa rodzaje szyfrowania.
Szyfrowanie symetryczne - algorytmy wykorzystujące ten sam klucz do szyfrowania i odszyfrowywania informacji, klucze są krótkie zazwyczaj mają długość od 40 do 256-bitów. Algorytmy te są szybsze od algorytmów szyfrowania asymetrycznego. Szyfrowanie tego rodzaju służy do zabezpieczenia masowych danych takich jak tunele VPN. Do tego rodzaju szyfrowania możemy przypisać takie algorymy jak: DES, 3DES, AES, SEAL, RC.
Szyfrowanie asymetryczne - algorytmy wykorzystują różne klucze do szyfrowania i deszyfrowania wiadomości. Klucze są długie od 512 do 4096-bitów. Przez długie klucze wydłuża sie sam proces szyfrowania, przez co te algorymy są wolniejsze. Służą do zabezpieczenia szybkich pojednycznych transakcji danych, takich jak połączenia HTTPS. Do tego rodzaju szyfrowania, możemy przypisać takie algorytmy jak: DH, DSS i DSA, RSA, EiGamal, Techniki krzywej eliptycznej.
Techniki szyfrowania są powszechne wśród bezpieczenych protokołów, nie które z nich wykorzystują jeden lub drugi rodzaj, nie które oba, wykorzystując jednen do jednej czynności drugi do kolejnej. Takimi protokołami są: IKE (podstawowy składnik sieci IPSec VPN), TLS (standard bezpieczeństwa komunikacji w sieciach), SSH czy PGP (zapewniające prywatną i poufną korespodencję elektroniczną z wykorzystaniem technik kryptografi).
Ciekawym algorymem kryptograficznym jest algorytm Diffie-Hellman, którego działanie opiera się na wygenerowaniu tego samego tajnego klucza po przez wymianę tak szczątkowych informacji, że nie które źródła podają że hosty ze sobą w ogóle się nie komunikują. Klucze tego algorytmu stosowane są przez IPSec (rodzaj sieci VPN), TLS czy wymianie danych SSH. Powszechną praktyką jest stosowanie algorytmu DH (Diffie-Hellman), do generowania klucza współdzielonego algorytmów symetrycznych jak 3DES czy AES.
Podsumowanie
Ten rodział przedstawił nam kompleksową wiedzę na temat zagrożeń bezpieczeństwa sieciowego, poznaliśmy rodzaje hakerów, ich narzędzia, rodzje złośliwego oprogramowania, typowe ataki sieciowe. Podatności protokołów sieciowych IP, TCP i UDP czy usług IP. Na koniec poznaliśmy najlepsze praktyki bezpieczeństwa oraz podstawy kryptografii.
3.4. Koncepcje ACL
ACL, czyli listy kontroli dostępu do seria poleceń IOS służąca do filtrowania ruchu. Filtrowanie ruchu odbywa się na podobnej zasadzie do routingu. Informacje z nagłówków są konfrontowane z kryteriami reguł ACL i na podstawie najlepszego dopasowania, ruch może zostać albo przepuszczony dalej albo zablokowany. Listy składają się z sekwencyjnych instrukcji zezwolenia albo odmowy te reguły są nazywane ACE - wpisami listy kontroli.
Poniżej znajduje się lista zadań, które mogą zostać wykonane za pomocą ACL:
Filtrowanie pakietów może wystąpić w warstwie 3 lub w 4, w zalezności od zastosowanych przez nas list kontroli dostępu. Routery Cisco obsługują dwa rodzaje list ACL:
Dla ACL ważny jest również kierunek przesyłanie pakietu. Każdy interfejs mimo, że transmisja odbywa się w dwóch kierunkach naraz to możemy określić czy dana transmisja pakietów opuszcza interfejs lub przez niego wchodzi. I to niezależnie od sieci, bowiem każdy z interfejsów przesyła ruch w obu kierunkach, a my możemy nałożyć po jednej z list każdy z kierunków.
Listy muszą mieć chociaż jedną wpis zezwolenia, w przeciwnym razie wszelki ruch zostanie odrzucony z powoduje niejawnego wpisu odrzucania całego ruchu. Każda z list posiada taką niejawną regułę.
Zadanie praktyczne - Packet Tracer
Demonstracja działania listy ACL - scenariusz
Demonstracja działania listy ACL - zadanie
3.4.2. Maska blankietowa w listach ACL
ACL używają w regułach masek blankietowych. Obliczanie tych masek poznaliśmy w przypadku omawiania OSPF-a. Dla przypomnienia aby tworzyć maskę blankietową, musimy odjąć od maski /32 bitowej maskę podsieci w postaciach dziesiętnych. W przypadku maski blankietowej, 0 oznaczają zgodność a 1 ignorowanie.
ACL-ki wprowadzają dwa słowa kluczowe dla konkretynych wartości masek blankietowych:
Możemy również tworzyć maski blankietowe dla zakresów IP, jeśli chcemy aby jeden wpis obejmował kilka sieci. to wówczas możemy utworzyć taki o to wpis w ACL:
access-list 10 permit 192.168.16.0 0.0.15.255
Ten wpis spowoduje zezwolenie na ruch z adresów 192.168.16.0 do 192.168.31.0.
3.4.2. Wytyczne do tworzenia ACL
Do interfejsu możemy przypisać określoną liczbę ACL, są to dwie listy dla każdego protokołu - IPv4 i IPv6, dla ruchu przychodzącego i wychodzącego.
Podczas implementacji ACL w sieci musimy wykazać się sporą starannością, ponieważ błędy w listach mogą doprowadzić do przestojów w łączności. Poniżej znajdują się zasady jakimi należy kierować się.
3.4.3. Typy list ACL IPv4
Routery Cisco obsługują dwa rodzaje ACL-ek:
Listę standardową możemy utworzyć na przykład za pomocą poniższego polecenia:
access-list 10 permit 192.168.10.0 0.0.0.255
Standardowa ACL, filtruje wyłącznie po adresie źródłowym, tym samym dopuszczając całą sieć 192.168.10.0. Rozszerzoną ACL możemy utworzyć na przykład za pomocą poniższego polecenia:
access-list 100 permit tcp 192.168.10.0 0.0.0.255 any eq www
Rozszerzona ACL, może znacznie bardziej kształtować ruch, w przypadku wyżej wymienionej list, to zezwala ona wyłącznie na ruch HTTP dla sieci 192.168.10.0/24.
ACL mogą być numerowane, tak jak to było w powyższym przypadku. Tutaj musimy wiedzieć jedną rzecz - z ACL numerowanymi wiąża się zakresy numerów jakie możemym nadać listom, tym samym deklarując ich typ. Listy standardowe mają numery od 1 do 99 oraz od 1300 do 1944. Natomiast Listy rozszerzone mają numery od 100 do 199 oraz od 2000 do 2699.
Inną opcją są listy nazwane, ich tworzenie przypomina trochę zakładanie puli DHCP. Na początku wydajemy polecenie z rodzajem oraz nazwą listy, i następnie w trybie konfiguracji listy podajemy kolejne wpisy.
Czynnikiem dość istotnym podczas wdrażania ACL-ek jest określenie miejesca gdzie należy je umieścić. Generalnie posługujemy się zasadą, że ACL-ki umiescza w miejscach gdzie będą one miały najwiekszy wpływ na wydajność i wobec tego istnieją dwie reguły oparte o rodzaj ACL-ek:
Najlepiej obrazuje to blokowanie, ponieważ ruch który ma niedocierać jest już wycinany na pierwszym routerze. Z kolei jeśli już stosujemy standardowe ACL-ki, to warto wykorzystać je do dopuszczenia ruchu z zaufanych sieci, na końcu każdej listy znajduje się nie jawna reguła, która zablokuje pozostały ruch.
Podsumowanie
W tym rodziale dowiedzliśmy się w jaki sposób kształtować ruch za pomocą ACL. Poznaliśmy czym są listy dostępowe, ich rodzaje oraz dobre praktyki podczas ich tworzenia przypomnieliśmy sobie również w jaki sposób oblicza się maski blankietowe.
3.5. Konfiguracja list ACL dla IPv4
W poprzednim rodziale dowiedzieliśmy się czym są ACL-ki i w jaki sposób możemy wykorzystać je do kształtowania ruchu. Poznaliśmy również podstawowe polecenia, ale bez ich omawiania. Ten rozdział przedstawi nam w jaki sposób tworzyć oraz modyfikować, standardowe i rozszerzone listy ACL oraz dodatkowo jak wykorzystać ACL do kontroli zdalnego dostępu do urządzeń.
3.5.1. Konfiguracja standardowych ACL dla IPv4
Tworzenie ACL najlepiej rozpocząć od zapisania w edytorze tekstu specyfiki polityki bezpieczeństwa organizacji, następnie musimy przełożyć te zasady na polecenia IOS, w tym momencie warto dołączać komentarze. Kiedy nasza lista jest hipotetycznie gotowa, możemy ją skopiować do środowiska testowego - może to być PT lub fizyczne urządzenia.
Chcąc utworzyć standardową numerowaną listę ACL w konfiguracji globalnej wydajemy następujące polecenie:
Router(config)# access-list access-list-number {deny | permit | remark text}
source [source-wildcard] [log]
Jeśli będziemy chcieli usunąć listę użyjemy polecenia:
no access-list access-list-number
Poszczególne elementy składni polecenia tworzenia standardowych numerycznych ACL znajduje się poniżej:
Chcąc utworzyć listę ACL standardową nazwaną, w konfiguracji globalnej musimy wydać następujące polecenie:
Router(config)# ip access-list standard access-list-name
access-list-name to unikatowa nazwa
dla listy. Zatwierdzenie tego polecenia, spowoduje, że przejedziemy
w trybu konfiguracji listy ACL. Wówczas konfiguracja takiej listy
skupia się tworzeniu reguł rozpoczynających się od słów kluczowych
permit, deny i ewentualnie
remark.
R1(config)# ip access-list standard PERMIT-ACCESS R1(config-std-nacl)# remark ACE permits host 192.168.10.10 R1(config-std-nacl)# permit host 192.168.10.10
Chcąc usunąć taką listę poprzedzamy polecenie
ip access-list standard PERMIT-ACCESS
słowem kluczowym no.
Określenie listy nie czyni jej jeszcze działającą. Jak pamiętamy listy są przypisywane do interfejsów i to na określonych kierunkach transmisji, więc chcąc podłączyć listę do interfejsu należy wydać poniższe polecenie:
Router(config-if) # ip access-group {access-list-number | access-list-name} {in | out}
Po słowie access-group, podajemy
albo numer listy, albo jej nazwę i na koncu podajemy kierunek dla
ruchu wychodzącego - out a dla ruchu
przychodzącego - in. Aby odwołać
listę musimy poprzedzić polecenie
ip access-group słowem no
oraz podać numer bądź nazwę listy.
Zadanie praktyczne - Packet Tracer
Konfigurowanie numerowanych standardowych list ACL IPv4 - scenariusz
Konfigurowanie numerowanych standardowych list ACL IPv4 - zadanie
Konfigurowanie nazywanych standardowych list ACL IPv4 - scenariusz
Konfigurowanie nazywanych standardowych list ACL IPv4 - zadanie
3.5.2. Modyfikowanie list ACL dla IPv4
Modyfikowanie ACL-ek, nie uchodzi za szczególnie przyjmne zajęcie. To zadanie może zrealizować na dwa sposoby. Możemy użyć albo wcześniej zapisanej w edytorze tekstu listy - tę listę wdrożoną należy usunąć poprzez słowo no, zmieć co trzeba i następnie utworzyć nową listę wklejając jej polecenia z edytora. Drugim sposobem jest użycie numerów sekwencyjnych.
Numery sekwencyjne wyświetlane są gdy używamy polecenia
show access-list do wyświetlenia
list ACL.
R1# show access-lists
Standard IP access list 1
10 deny 19.168.10.10
20 permit 192.168.10.0, wildcard bits 0.0.0.255
R1#
Do ich edycji musimy skorzystać z polecenia
ip access-list standard, następnie
usuwamy wadliwy wpis, w tym przypadku jest
10 poprzedzając numer sekwencji
słowem no i następnie poprawiony wpis rozpoczynamy od numeru
sekwencji. Poniżej znajduje się przykład z IOS:
R1# conf t
R1(config)# ip access-list standard 1
R1(config-std-nacl)# no 10
R1(config-std-nacl)# 10 deny host 192.168.10.10
R1(config-std-nacl)# end
R1# show access-lists
Standard IP access list 1
10 deny 192.168.10.10
20 permit 192.168.10.0, wildcard bits 0.0.0.255
R1#
W przypadku nazwanej listy postępujemy podobnie, tylko zamiast numeru podajemy nazwę. Użycie numerów sekencyjnych daje nam jeszcze jedną dodatkową funkcję, mianowicie pozwala nam wprowadzać wpisy w konkretne miejsca, na liście. Biorąc pod uwagę poprzedni przykład chcąc dodać host 192.168.10.5, którego ruch ma również zostać zablokowany, to jeśli dopiszemy ją to ta reguła nie będzieć mieć sensu. Druga reguła dopuszcza ruch z całej sieci 192.168.10.0/24. Zatem musimy wstawić regułę zablokowania hosta 192.168.10.5 pomiędzy regułę 10 a 20, na przykład. Możemy ją również wstawić na początku samej listy, również będzie ona miała swoje zastosowanie.
R1# configure terminal
R1(config)# ip access-list standard NO-ACCESS
R1(config-std-nacl)# 15 deny 192.168.10.5
R1(config-std-nacl)# end
R1#
R1# show access-lists
Standard IP access list NO-ACCESS
15 deny 192.168.10.5
10 deny 192.168.10.10
20 permit 192.168.10.0, wildcard bits 0.0.0.255
R1#
Chcąc wstawić w regułę edytujemy listę za pomocą polecenia
ip access-list następnie
rozpoczynamy wpis od numer np. 15. Na koniec opuszczamy tryb
konfiguracji listy i wyświetlamy zawartość listy. Wydawać by się
mogło, że
nie takiego efektu się spodziewaliśmy. Ten efekt jest spowodowany
działaniem funkcji mieszaczjącej na standardowych listach ACL dla
IPv4.
Wyświetlając listę za pomocą polecenia
show access-lists możemy zauważyć,
że IOS zlicza przypasowania do wpisów w ACL, dzięki czemu możemy
zauważyć, czy te wpisy mają w ogóle zastosowanie. Czyszczenia
liczników możemy dokonać za pomoca polecenia:
R1# clear access-list counters
Wydanego w trybie uprzywilejowanym EXEC.
3.5.3. Zabezpieczenia linii VTY za pomocą standardowyej ACL IPv4.
Przy użyciu ACL możemy określić, kto może się podłączyć do naszego urządzenia zdalnie, a kto nie. Cała metoda polega na utworzeniu standardowej listy ACL i następnie na liniach VTY możemy za pomocą polecenia access-class wskazać ACL, która będzie zezwalać lub blokować zdalny dostęp dla zapisanych w niej sieciach lub hostach. Poniżej znajduje się składania polecenia access-class:
R1(config-line)# access-class {access-list-number | access-list-name} { in | out }
Zwróć my uwagę to polecenie pozwala również na ustalenie kierunku.
Stosowanym w praktyce kierunkiem jest
in, drugi kierunek odfiltrowuje
ruch VTY wychodzący i jest on rzadko stosowany.
R1(config)# username ADMIN secret class R1(config)# ip access-list standard ADMIN-HOST R1(config-std-nacl)# remark This ACL secures incoming vty lines R1(config-std-nacl)# permit 192.168.10.10 R1(config-std-nacl)# deny any R1(config-std-nacl)# exit R1(config)# line vty 0 4 R1(config-line)# login local R1(config-line)# transport input ssh R1(config-line)# access-class ADMIN-HOST in R1(config-line)# end R1#
Przy tak skonfigurowanej liniach VTY, dostęp przez SSH do urządzenia będzie mieć wyłącznie host o adresie 192.168.10.10.
3.5.4. Rozszerzone listy ACL
Rozszerzone listy ACL pozwalają nam na dodanie większej ilości kryteriów dopasowania pakietów. Listy rozszerzone podobnie jak listy standardowe również mogą być numerowane oraz nazwane. Składnia tworząca listę wraz ze wpisem wygląda następująco:
Router(config)# access-list access-list-number {deny | permit | remark text}
protocol source source-wildcard [operator {port}] destination destination-wildcard
[operator {port}] [established] [log]
Pierwszą zmianą odnośnie list standardowych jest:
protocol - nazwa lub numer protokołu
sieci Internet. Typowymi słowami kluczowymi są tutaj:
ip, tcp, udp, icmp. Pełną listę możemy wyświetlić za pomocą
znaku zapytania (?). Słowo kluczowe IP pasuje do
wszystkich protokołów IP;
destination i
destination-wildcard - adres ip oraz
maska blankietowa dla sieci bądź hosta docelowego. Mogą tutaj
występować słowa kluczowe host oraz any;
operator - porównuje porty źródłowe
i docelowe. Możliwe argumenty to: lt (mniejsze niż),
gt (większe niż), eq (równy), neq
(nie równy) oraz range (zakres);
port - numer bądź nazwa portu TCP
lub UDP. Pod znakiem zapytania (?), dostępna jest
pełna lista wraz z numerami portów;
established - funkcja
zapory pierwszej generacji, tylko dla TCP.
Włączanie list rozszerzonych wygląda tak samo jak w przypadku list standardowych, oto przykład:
R1(config)# access-list 110 permit tcp 192.168.10.0 0.0.0.255 any eq www R1(config)# access-list 110 permit tcp 192.168.10.0 0.0.0.255 any eq 443 R1(config)# interface g0/0/0 R1(config-if)# ip access-group 110 in R1(config-if)# exit R1(config)#
Stosowanie list rozszerzonych umożliwia nam dostęp do bardzo wygodnej funkcji. Jeśli chcemy zabezpieczyć naszą sieć wewnętrzną za pomocą ACL-ek, to utworzyli byśmy dwie listy jedną na ruch wchodzący do interfejsu sieci wewnętrznej, zezwalający np. jej użytkownikom na korzystanie z HTTP/S. Wówczas hosty naszej sieci, nie będą mogły korzystać z innych protokołów, jednak ta pojedyncza lista daje możliwość skomunikowania się z hostami naszej sieci z zewnątrz. Potrzebujemy drugiej ACL-ki, która zablokuje taką możliwość. Mogli byś my utworzyć pustą listę i przypisać ją do kierunku wychodzącego naszego interfejsu wewnętrzego i to tyle. Cały ruch zablokowany, w tym odpowiedzi od serwerów WWW dla hostów naszej sieci. Oczywiście przy takiej transmisji moglibyśmy dopuścić ruch na porcie źródłowym TCP/80 lub TCP/443 (HTTP, HTTPS). Co nie jest dobrym rozwiązaniem, ponieważ nie jest problemem wysłanie pakietu o sfałszowanym porcie źródłowym. W tym przypadku skorzystamy z wpisu dopuszczającego cały TCP dla sieci 192.168.10.0/24, ale tylko dla połączeń już nawiązanych, blokując tym samym możliwość nawiązania nowego połączenia z zewnatrz temu służy opcja established. Należa zapamiętać, że z tej funkcji może skorzystać tylko dla protokołu TCP.
R1(config)# access-list 120 permit tcp any 192.168.10.0 0.0.0.255 established R1(config)# interface g0/0/0 R1(config-if)# ip access-group 120 out R1(config-if)# exit R1(config)#
Wiele pozostałych czynności dokonywanych na listach rozszerzonych dokonuje się w sposób analogiczny do listy standardowych. Przyczym w przypadku wstawiania zasad do listy, to na listach rozszerzonych nie działa algorytm mieszający, zatem kolejność wpisów powinna być taka jaką my sobie zadeklarowaliśmy, ale nie jak ustalił to IOS.
Do weryfikacji ACL, możemy wykorzystać polecenia:
show ip interface, pokaże nam ono
jakie listy są przypisane do tego interfejsu;
show access-list, zwróci
zdeklarowane w systemie listy ACL;
show running-config | begin ip access-list,
wyświetla listy ACL z bierzącej konfiguracji urządzenia.
Zadanie praktyczne - Packet Tracer
Konfiguracja rozszerzonych list ACL IPv4 - Scenariusz 1 - scenariusz
Konfiguracja rozszerzonych list ACL IPv4 - Scenariusz 1 - zadanie
Konfiguracja rozszerzonych list ACL IPv4 - Scenariusz 2 - scenariusz
Konfiguracja rozszerzonych list ACL IPv4 - Scenariusz 2 - zadanie
Zadanie praktyczne - Packet Tracer
Wdrażanie ACL IPv4 - wyzwanie - scenariusz
Wdrażanie ACL IPv4 - wyzwanie - zadanie
Laboratorium
Konfiguracja i weryfikacja rozszerzonych list ACL IPv4
Podsumowanie
Ten rozdziała pokazał nam w jaki sposób tworzyć oraz modyfikować listy ACL. Poznaliśmy sposób na zabezpieczenie linii VTY za pomocą ACL oraz funkcję established rozszerzonych list dostępu. Na koniec poznaliśmy w jaki sposób możemy weryfikować listy ACL na naszych urządzeniach.
3.6. NAT dla IPv4
Jak może pamiętamy z poprzedniego modułu pula adresów IPv4 jest na wyczerpaniu. W obecnym stanie rzeczy nie wystarcza adresów dla wszystkich urządzeń podłączonych do Internetu. Gdy osoby odpowiedzialne za rozwój sieci globalnej spostrzegli, że pula adresów jest alokowana w bardzo szybkim tempie i za jakiś czas ich po prostu zacznie brakować, wydzielono trzy klasy adresów prywatnych. Adresy tego rodzaju są nie jednoznaczne dlatego też nie mogą być routowane w Internecie. Nie należą bowiem one do żadnej organizacji. Za definicję adresów odpowiada dokument RFC 1918, wydzielając tym samym:
Lokalne sieci komputerowe wykorzystują klasę adresów prywatnych do adresowania swoich komputerów. Jako, że te adresy nie mogą funkcjonować poza sieciami lokalnymi, to musi istnieć mechanizm, który pozwoli na zamianę adresów prywatnych na adresy publiczne. Tym właśnie jest NAT. Jak wszsystko na świecie, ta funkcjonalność posiada wady i zalety, które zostaną omówione w tym rozdziale.
Mechanizm translacji adresów, zamienia adresy prywatne na adresy publiczne. W zależności czy są to adresy prywatne czy publiczne lub ruch jest przychodzący lub wychodzący spotkamy się z takimi określeniami adresów jak:
Terminy te wypełniąją taką instyucję jak tablica NAT, zawiera ona wszystkie mapowania adresów oraz portów.
3.6.1. Typy NAT
Mechnizm NAT może występować w kilku wariantach. Które różnią się technikami mapowania adresów. Pierwszym z nich jest statyczny NAT, w którym to jeden adres prywatny zamieniany na jeden adres publiczny. Translacja jeden-do-jeden (1:1). Takie mapowania są wykonywane przez administratora i są niezmienne bez rekonfiguracji.
Drugim rodzajem jest dynamiczny NAT - przypisuje on adresy na podstawie kolejności żądań dostępu do sieci zewnętrznej. Obie te metody NAT, wymagają odpowiednio dużej puli adresów publicznych przydzielonych przez operatora internetowego, jeśli pula będzie za mała, to tylko część z hostów będzie mieć dostęp do sieci zewnętrznej. A jak możemy się domyślić to operatorzy obecnie już nawet klientom biznesowym niechętnie ustępniają adresy IPv4.
Istnieje również mechanizm, który jest w stanie zapewnić dostęp do sieci zewnętrznej przy jednym lub kilku adresach zewnętrznych. Takim mechanizmem jest PAT (Port Address Translation) nazywany również NAT-em z przeciążeniem. Ponieważ przeciążamy jeden adres, ruchem większym niż pochodzący z jednego komputera. Poza zwykłą translacją adresów, działa on na zasadzie zmiany portu źródłowego jeśli do routera docierają połączenia z różnych hostów z tymi samymi numerami portów źródłowych. Wówczas dla adresu wewnętrznego globalnego przypisywany jest inny numer portu i tak przetworzony pakiet wysyłany jest do hosta docelowego. W taki sposób działają mechnizmy NAT w urządzeniach domowych lub przeznaczonych dla małych firm.
Podczas działania mechaznizm PAT stara się zachować oryginale porty, jeśli jest to jednak niemożliwe, wówczas używa on pierwszego dostępnego z odpowiedniej grupy portów: 0-511, 512-1023 lub 1024-65535. Jeśli jakimś cudem wszystkie porty zostaną wykorzystane, to dopiero mechanizm przechodzi do kolejnego adresu.
Porównując PAT oraz NAT. To NAT:
A PAT z kolei:
W przypadku mechanizmu PAT, pozostaje jedna nierozwiązana kwestia. Otóż wymiana komunikatów echo protokołu ICMP przez PAT. Tak naprawdę to TCP, UDP i ICMP przez PAT osbługiwane są w nieco inny sposób. W przypadku działania narzędzia ping wykorzystywane jest pole Query ID zawarte w komunikatach echo request i echo reply. To pole zwiększane jest o jeden z każdym wysłanym zapytaniem do sieci zewnętrznej.
Zadanie praktyczne - Packet Tracer
Badanie działania NAT - scenariusz
Badanie działania NAT - zadanie
3.6.2. Zalety i wady mechanizmu NAT
Do zalet mechanizmu NAT możemy zaliczyć:
Natomiast do wad mechanizmu NAT możemy zaliczyć:
3.6.3. NAT statyczny w IOS
Załóżmy hipotetycznie, że mamy serwer WWW o adresie 192.168.1.10, ma on być dostępny dla klientów z sieci zewnętrznej pod adresem 209.169.201.6. Co należy zrobić, aby zrealizować to zadanie przy użyciu routera Cisco?
Otóż na początek tworzymy odwzorowanie między adresem wewnętrznym lokalnym, a adresem wewnętrznym globalnym.
Router(config)# ip nat inside source static 192.168.10.254 209.169.201.5
W powyższym polecenie użyliśmy słów kluczowych:
inside ze względu, że dokonujemy
mapowań wewnętrznych (lokalny do globalnego),
source, ponieważ router ma zamieniać
adresy źródłowe oraz static,
ustawiamy NAT statyczny, to jest mapowanie adresów 1:1.
Następnym zadaniem jest określenie stron translacji. Sieć LAN wykorzystuje Ethernet więc ostatni port będzie łączem z sieci do routera. Natomiast port szeregowy będzie symulować naszą sieć rozległą.
Router(config)# interface GigabitEthernet0/2 Router(config-if)# ip address 192.168.1.2 255.255.255.0 Router(config-if)# ip nat inside Router(config-if)# exit R2(config)# interface serial 0/1/1 R2(config-if)# ip address 209.169.200.1 255.255.255.252 R2(config-if)# ip nat outside
Teraz adresy źródłowe serwera WWW będą tłumaczone na nasz adres wewnętrzny globalny.
Jeśli chcielibyśmy sobie przeanlizować jak to wygląda, to klient gdzieś w Internecie, wpisuje adres strony. System DNS tłumaczy ten adres strony na adres IP pod którym widnieje nasz serwer w sieci zewnętrznej. Pakiet z żądaniem strony dociera do naszego serwer i ten mu odpowiada. Pakiet z odpowiedzią zawiera adres źródłowy prywatny - tj. 192.168.1.10 i adresem docelowym jest adres źródłowy żądania strony. Oczywiście adres jest poza siecią więc docelowym adresem MAC ramki Ethernet będzie adres MAC interfejsu bramy. W momecie gdy pakiet osiągnie router, dochodzi do translacji adresów. W tym momencie dochodzimy różnicy w rodzajach mechanizmu NAT, ponieważ w przypadku statycznego NAT-u, adres źródłowy zostanie zamieniony na zmapowany wcześniej adres publiczny. Zatem do naszej bramy adresem źródłowym będzie: 192.168.1.10, natomiast po jej opuszczeniu adresem źródłowym będzie 209.169.201.5.
Do w celu weryfikacji ustawień NAT-u możemy posłużyć się dwoma poleceniami:
3.6.4. Dynamiczny NAT w IOS
Poprzedni rodzaj NAT-u wymagał zmapowania adresów prywatnych z publicznymi, jeden do jeden. W tym przypadku mapowanie będzie odbywać się na podstawie żądania do sieci zewnętrznej i będzie odbywać się dynamicznie. Wcześnie to administrator decydował o tym jaki adres prywatny będzie mapowany na adres publiczny. Teraz decyduje o tym router. Ten stan rzeczy powoduje, że konfiguracja będzie nieco bardziej skomplikowana.
Załóżmy, że mamy dwa komputery w dwóch różnych sieciach, mają one następujące adresy: 192.168.10.10/24 oraz 192.168.11.10/24. Komputery chcą skomunikować się z serwerem od adresie 209.165.200.254.
Na początku musimy rozpocząć naszą konfigurację od określenia puli adresów, jakie mogą być mapowane podczas dynamicznego NAT-u. Taką pulę zazwyczaj uzyskuje się od swojego dostawcy usług internetowych. W naszym przypadku są to adresy od 209.165.200.226 do 209.165.200.240 z maską /27. Aby skonfigurować pulę w trybie konfiguracji globalnej wydajemy poniższe polecenie:
Router(config)# ip nat pool NAT-POOL1 209.165.200.226 209.165.200.240 netmask 255.255.255.224
Za pomocą powyższego polecenia zdefiniowaliśmy pulę o nazwie
NAT-POOL1. Teraz musimy utworzyć
warunek, dzięki któremu określimy jakie sieci mają kwalifikować się
tłumaczenia
lub ich adresy mają być tłumaczone na jasno określoną pulę adresów.
Takie warunki tworzy się za pomocą standardowych list ACL.
Router(config)# access-list 1 permit 192.168.0.0 0.0.255.255
Teraz należy połaczyć ze sobą pulę adresów NAT-u oraz listę ACL, w jednej definicji dynamicznej translacji adresów.
Router(config-if)# ip nat inside source list 1 pool NAT-POOL1
Przyczym, ACL nie musi być numerowana, nazwana również jest możliwa do użycia w tym przypadku. Ostatnią czynnością jest określenie wewnętrznych i zewnętznych interfejsów.
Router(config)# interface GigabitEthernet0/1 Router(config-if)# ip nat inside Router(config)# interface GigabitEthernet0/2 Router(config-if)# ip nat inside Router(config)# interface serial 0/1/1 Router(config-if)# ip nat outside
Wersje sprzętowe IOS posiadają dodatkowy słowo kluczowe
verbose dla polecenia
show ip nat translations. Która
wyświetla więcej informacji na temat wpisów w tablicy NAT.
Router# show ip nat translation verbose
Pro Inside global Inside local Outside local Outside global
tcp 209.165.200.228 192.168.10.10 --- ---
create 00:02:11, use 00:02:11 timeout:86400000, left 23:57:48, Map-Id(In): 1,
flags:
none, use_count: 0, entry-id: 10, lc_entries: 0
tcp 209.165.200.229 192.168.11.10 --- ---
create 00:02:10, use 00:02:10 timeout:86400000, left 23:57:49, Map-Id(In): 1,
flags:
none, use_count: 0, entry-id: 12, lc_entries: 0
Zwróćmy uwagę na to, że wpisy w tablicy NAT-u widnieją przez
określony czas. W przypadku NAT-u dynamicznego, domyślnie są to 24
godziny, chyba że zdefiniowano inaczej przy pomocy polecenia
ip nat translation timeout. Nie
musimy jednak wyczekiwać na wygaśnięcie wpisów. Możemy je ręcznie
usunąć, czy przy użyciu tego samego polecenia
(clear ip nat translation),
które czyści całą tablicę - w tym przypadku podajemy
inside lokalny-adr globalny-adr lub
outside lokalny-adr globalny-adr.
W przypadku dynamicznego NAT i polecenie
show ip nat statistics wzraca więcej informacji, np. procent
zaalokowanej puli.
Router# show ip nat statistics Total active translations: 4 (0 static, 4 dynamic; 0 extended) Peak translations: 4, occurred 00:31:43 ago Outside interfaces: Serial0/1/1 Inside interfaces: GigabitEthernet0/1 GigabitEthernet0/2 Hits: 47 Misses: 0 CEF Translated packets: 47, CEF Punted packets: 0 Expired translations: 5 Dynamic mappings: -- Inside Source [Id: 1] access-list 1 pool NAT-POOL1 refcount 4 pool NAT-POOL1: netmask 255.255.255.224 start 209.165.200.226 end 209.165.200.240 type generic, total addresses 15, allocated 2 (13%), misses 0 ...
Wyświetlając bierzącą konfiguracje z poleceniem filtrujący include, możemy podejrzeć konfiguracje NAT-u.
R2# show running-config | include NAT ip nat pool NAT-POOL1 209.165.200.226 209.165.200.240 netmask 255.255.255.224 ip nat inside source list 1 pool NAT-POOL1
Zadanie praktyczne - Packet Tracer
Konfigurowanie dynamicznego NAT - scenariusz
Konfigurowanie dynamicznego NAT - zadanie
3.6.5. PAT w IOS
W większości przypadków, konfiguracji sieci czy to w mniejszych, czy większych organizacjach, nie skorzystamy z żadnej z powyższych metod, gdyż wymagają one puli adresów publicznych, a te obecnie są bardzo rzadko przydzielane. Najczęstszym rodzajem NAT-u jaki będziemy konfigurować jest właśnie PAT.
Scenariusz z dynamicznego NAT-u rozszerzymy od dodatkowy serwer. Serwery będą mieć adresy 209.165.201.1 oraz 209.165.202.129. Adres sieci zewnętrznej naszego routera to 209.165.200.224/27. Natomiast adres interfejsu podłączonego do sieci zewnętrznej to: 209.165.200.225. Adres sieci zewnętrznej określa pulę przydzielonych adresów publicznych od usługodawcy.
Konfigurując PAT, mamy do wyboru tak naprawdę dwa podejścia. Pierszym z nich jest przeciążenie pojedynczego adresu, który mamy przypisany do interfejsu. Tak zazwyczaj będzie w przypadku domów lub małych biur. Konfigurację rozpoczynamy od utworzenia ACL-ki w celu określenia jakie sieci źródłowe mają być tłumaczone.
Router(config)# access-list 1 permit 192.168.0.0 0.0.255.255
Następnie musimy powiązać listę ACL z interfejsem, podobnie jak w przypadku dynamicznego NAT-u, kiedy powiązaliśmy ACL z pulą. W celu uruchomienia PAT-u, dodajemy do polecenia słowo kluczowe overload.
Router(config)# ip nat inside source list 1 interface serial 0/1/1 overload
W tym przypadku wykorzystaliśmy słowo kluczowe
interface i podaliśmy ID interfejsu.
Teraz wszystkie połączenia z dwóch naszych podsieci będą tłumaczone
na ten jeden adres, który jest ustawiony na interfejsie
serial 0/1/1. Poza słowem
overload reszta polecenia pozostaje
taka sama. Ostatnią czynnością jest określenie stron na interfejsach.
Router(config)# interface GigabitEthernet0/1 Router(config-if)# ip nat inside Router(config)# interface GigabitEthernet0/2 Router(config-if)# ip nat inside Router(config)# interface serial 0/1/1 Router(config-if)# ip nat outside
Drugim podejściem jest translacja adresów na adresy z wcześniej
zdefiniowanej puli. Tutaj wykonujemy wszystkie czynności w taki
sam sposób jak w przypadku dynamicznego NAT-u, ale do polecenia
dowiązania listy ACL do puli dodajemy słowo kluczowe
overload.
Router(config)# ip nat pool NAT-POOL1 209.165.200.226 209.165.200.240 netmask 255.255.255.224 Router(config)# access-list 1 permit 192.168.0.0 0.0.255.255 Router(config-if)# ip nat inside source list 1 pool NAT-POOL1 overload Router(config)# interface GigabitEthernet0/1 Router(config-if)# ip nat inside Router(config)# interface GigabitEthernet0/2 Router(config-if)# ip nat inside Router(config)# interface serial 0/1/1 Router(config-if)# ip nat outside
Po uruchomieniu NAT-u wyżej wymienionymi metodami, router będzie starał zachować oryginalne porty, jednak jednak u któregoś z hostów porty źródły będzie się powtarzać to zostanie zmieniony na pierwszy wolny. Router przeszukuje trzy grupy w poszukiwaniu odpowiedniego portu do zmiany. Jeśli w jakiś sposób porty się wyczerpią, wówczas dopiero, albo dalsza możliwość tłumaczenia zaniknie, jeśli tłumaczyliśmy na pojedynczy adres, albo zostanie wykorzystany kolejny adres z puli. Poniżej znajdują się zrzuty tablicy NAT oraz statystyk dotyczących skonfigurowanego przez nas PAT-u.
Router# show ip nat translations
Pro Inside global Inside local Outside local Outside global
tcp 209.165.200.225:1444 192.168.10.10:1444 209.165.201.1:80 209.165.201.1:80
tcp 209.165.200.225:1445 192.168.11.10:1444 209.165.202.129:80 209.165.202.129:80
Router# show ip nat statistics
Total active translations: 4 (0 static, 2 dynamic; 2 extended)
Peak translations: 2, occurred 00:31:43 ago
Outside interfaces:
Serial0/1/1
Inside interfaces:
GigabitEthernet0/1
GigabitEthernet0/2
Hits: 4 Misses: 0
CEF Translated packets: 47, CEF Punted packets: 0
Expired translations: 0
Dynamic mappings:
-- Inside Source
[Id: 3] access-list 1 pool NAT-POOL1 refcount 2
pool NAT-POOL1: netmask 255.255.255.224
start 209.165.200.225 end 209.165.200.240
type generic, total addresses 15, allocated 1 (6%), misses 0
...
Zadanie praktyczne - Packet Tracer
Konfiguracja PAT - scenariusz
Konfiguracja PAT - zadanie
3.6.6. NAT64
Protokół IPv6 nie potrzebuje takich mechanizmów jak NAT, zawiera bardzo dużo adresów - nie wiadomo czy kiedyś się one skończą, Zawiera on także adresy lokalne podobne do tych z RFC1918, ale nie mają one takiej samej funkcji. NAT w IPv6, nazwany NAT64 ma zupełnie inną funkcję, otóż służy on do tworzenia transparentnych połączeń pomiędzy sieciami IPv6 a IPv4. Jest to technologia przejściowa na czas całkowite migracji do IPv6.
Zadanie praktyczne - Packet Tracer
Konfiguracja NAT dla IPv4 - scenariusz
Konfiguracja NAT dla IPv4 - zadanie
Laboratorium
Podsumowanie
W tym rozdziale zapoznaliśmy się z mechanizmem sieciowym NAT dla IPv4. Mechnizm ten zapewnia dostęp komputerom sieci lokalnej do sieci zewnętrznych. Poznaliśmy jego metodę działania oraz jego odmiany. Dowiedziliśmy się w jaki sposób uruchomić go na sprzęcie Cisco z systemami IOS. Na koniec wyjaśniono czym jest NAT64.
3.7. Koncepcje sieci WAN
Sieci lokalne LAN, są sieciami budowanymi na małym obszarze lub na małą skalę. Jednego budynku, jednego przedsiębiorstwa na niewielkim obszarze. Innym rodzajemy sieci jest sieć WAN - sieć rozległa, która rozciąga się swoim poza budynki, często wykorzystując infrastrukturę miejską, łącząc ze sobą również inne miasta czy mniejsze miejscowości. W tym temacie opowiemy sobie o technologiach, które stoją za tym, że w domu mamy puszkę światłowowodową, kabel koncentryczny czy gniazdo telefoniczne za ich pośrednictwem możemy mieć dostęp do sieci Internet, ale i nie tylko. Mając odpowiednie zasoby finansowe możemy połączyć ze sobą dwa budynki będące w różnych częściach mista lub w różnych miastach dedykowanym tylko dla nas łączem.
Sieci LAN, są wyłącznie naszą sprawą prywatną. W przypadku gdy przy sieciach rozległych sprawa nie jest aż tak oczywista. Mimo iż struktura takiej sieci należy do naszego usługodawcy to współdzielimy ją z innymi abonentami. Wyjątkiem tutaj są dzierżawione linie abonenckie, gdzie usługodawca zestawia nam połączenie sieci WAN (w tych technologiach) między jednym a drugim naszym punktem. Jednak ich cena, nawet bogatsze firmy zmusza do wykorzystywania infrastruktury publicznej, oczywiście jako klienci biznesowi są lepiej traktowani i mają wiecej możliwości. Jest jednak branża, która dalej będzie korzystać z dzierżawionych łączy i jest nią bankowość.
Sieci rozległe podobnie jak ich lokalne odpowiedniki posiadają topologie, i wśród nich możemy wyróżnić:
W sieciach korporacyjnych możemy spotkać się z większą niż jeden liczbą połączeń do sieci rozległej, najczęściej zapewnianą przez dwóch różnych operatorów. Ma to na celu zapewnienie niezawodności - dalszego działania usług, pomimo awarii jednego z łączy oraz wydajności poprzez równoważnie obciążenia przez te łącza. Klienci biznesowi (duże firmy) zazwyczaj podpisują z operatorem umowę o poziomie usług - SLA, w której to mogą znajdować się takie zapisy jak możliwa długość braku dostępu do usługi w skali roku lub deklarowana przepustowość.
Sieci lokalne mogą ewoluować, rozrastać się pod względem ilości hostów czy podsieci, ale również rozrastać fizycznie wraz rozwojem firmy. Wówczas technlogie sieci lokalnych, mogą okazać nie wydajne i zbyt drogie, aby móc połączyć ze sobą nawet dwa budynki, ale znajdujące się np. w różnych częsciach miasta czy kraju. Remedium na tego typu problemy są właśnie sieci rozległe oraz ich technologie.
3.7.1. Operacje WAN
Za standardy sieci WAN odpowiedzialne są takie organizacje jak: TIA/EIA, ISO, IEEE.
Sieci WAN najczęsciej operują w warstwie 1 oraz 2. Protokoły warstwy pierwszej opisują elementy elektryczne, mechaniczne oraz operacyjne przesyłania bitów przez medium transmisyjne. Obecnie najczęściej wykorzystywane są światłowody o dużej odległości, a rozwiązania stosowane to między innymi:
SDH oraz SONET zasadniczo świadczą te same usługi. SDH upowszechnił się na kontencie europejskim natomiast SONET stosowany jest w krajach Ameryki Północnej. Te dwie technologie mogą rozszerzyć swoją nośność dzięki zastosowaniu DWDM.
Protokoły warstwy drugiej definiują sposoby przesyłania danych w ramkach. Do rozwiązań stosowanych przez sieci WAN w tej warstwie możemy zaliczyć takie protokoły jak:
Do rzadziej stosowanych technologii, możemy zaliczyć: Point-to-Point Protocol (PPP), czy High-Level Data Link Control (HDLC).
Ze względu na fakt działania sieci WAN w wartstwie 1 i 2 musimy zapoznać się z terminologią związaną z fizycznymi połączeniami pomiędzy siecią firmową a siecią usługodawcy. Poniżej znajduje się lista terminów związanych z sieciami WAN:
Do urządzeń sieci rozległych możemy zaliczyć, różnego rodzaju modemy konwertery optyczne, a czasem nawet routery czy punkty dostępowe.
Komunikację sieciową można zrealizować za pomocą komunikacji z komutacją (przełączaniem) łączy. Sieć z komutacją łączy ustanawia dedykowany obwód (lub kanał) między punktami końcowymi, zanim użytkownicy będą mogli się komunikować. Najpopularniejsze technologie WAN, wykorzystujące komuntację łączy to: PTSN - publiczna komuntowana sieć telefoniczna i cyfrowa sieć z integracją usług - ISDN. Sieci tego rodzaju są zaszłością i zostały wyparte przez sieci z przełączaniem pakietów, takie jak Ethernet WAN (Metro Ethernet) czy MPLS.
Standardy sieci WAN warstwy pierwszej - SONET/SDH, definiują sposób przesyłania ogromnych ilości danych, danych głosowych czy komunikacji wideo, przez swiadłowód na duże odległości. Standardy te są użwane w topologii pierścienia, zawierająca ścieżki nadmiarowe umożliwiające przepływ ruchu w obu kierunkach. Technologia DWDM zwiększa nośność dla SDH i SONET poprzez przesyłanie przez ten sam światłowód impulsów świetlnych o różnej długości fali, zapewniając tym samy odrębne kanały komunikacyjne.
3.7.2. Obecne technologie sieci WAN
Generalnie technologia Ethernet, nie była przeznaczona dla innych sieci poza lokalnymi ze względu na ograniczenia długości okablowania miedzianego, jednak zmianę tego punktu widzenia przyniosły światłowowdy. Dzięki nim Ethernet, stał się jedną z opcji dostępowych dla sieci WAN. Niektóre standardy potrafią przesyłać informacje na odległosci do 70 km (IEEE 1000BASE-ZX).
Innym przykładem może być MPLS to wysoce wydajna technologa routingu WAN dla dostawcy usług bez względu na metodę dostępu lub rodzaj obciążenia. MPLS, może obsługiwać różne metody dostępu klienta - czy łączy się przez Ethernet, czy za pomocą kabla koncentrycznego. MPLS może enkapsulować wszystkie typy protokołów w tym IPv4 czy IPv6. Obecnie MPLS jest najczęściej stosowanym protokółem warstwy 2 w sieciach rozległych.
3.7.3. Łączność internetowa
Sieci WAN, napewno większości będą kojarzyć się z połączeniem z siecią Internet i jest w większości przypadków dobra myśl. Ponieważ jak wcześniej wspominaliśmy, nawet duże przedsiębiorstwa rzadko decydują się na ustanowienie prywatnej sieci WAN, przez jednego z operatorów. Najczęściej wykorzystują oni sieć publiczną - współdzieloną z innymi abonentami, już nie koniecznie biznesowymi. Zapewniając tym samym łączność miedzy np. oddziałami firmy wraz z dostępem do Internetu.
Technologie łączności internetowej możemy podzielić na przewodowe oraz bezprzewodowe. Do sieci przewodowowych możemy zaliczyć technologię takie jak:
DSL jest wykorzystaniem linii telefonicznej dla połączeń szerokopasmowych. Technologia ta wykorzystuje nieużwane przez rozmowy telefoniczne przestrzeń częstotliwości. Istnieje kilka jej odmian oferujących różne przepustowości. Odmiana ADSL - asymetryczny DSL - wykorzystuje węższy zakres częstotliwości dla wysłania danych i szerszy dla ich pobierania, co przełoży się na różnice w przepustowości łącza w tych kierunkach transmisji. Poza częstotliwością na szybkość DSL wpływa długość pętli lokalnej, rodzja użytego kabla oraz jego stan. Dla odmiany ADSL, długość pętli lokalnej możemy wynosić maksymalnie 5,46 km. Poza ADSL, istnieje kilka wersji takich jak, ADSL2+ czy SDSL - symetryczny DSL. Modemy DSL-owe, konwertują sygnał Ethernet-u na sygnał DSL, który jest przesyłany do urządzenia DSLAM i tam jest rodzielany na połaczenie telefoniczne oraz połącznie internetowe. W przypadku DSL każdy abonent ma oddzielne połącznie z DSLAM, który znajduje się w CO operatora, więc ilość użytkowników nie ma wpływu na jego obciążenie, tak jak w przypadku połączenia kablowego.
Technlogia DSL dla warstwy drugiej używa protokołu PPP, mimo że jest on przestarzały to zapewnia następujące czynniki, które z poziomu usługodawcy mogą być dość istotne:
Modemy mają złącza DSL do podłączenia linii telefonicznej oraz Ethernet do podłączenia routera lub hosta. Ethernet nie wspiera PPP i wówczas należy wdrożyć taką metodę jak PPPoE. Host z uruchomionym klientem PPPoE, enkapsuluje ramkę PPP w ramce Ethernet i wysyła ją do modemu. Modem denkapsuluje ramkę PPP z ramki Ethernet i przesyłą ją do usługodawcy za pomocą sygnałów DSL. Jedną z metod wdrożenia PPPoE jest albo uruchomienie klienta na hosie, wówczas jego interfejs zostanie zaadresowany za pomocą publicznego adresu IP. Drugim wariantem jest uruchomienie routera z funkcją PPPoE. Wówczas hosty komunikują się z nim w taki sam sposób jak z innym urządzeniem. Router zajmuję się już obsługą PPPoE.
Technologia kablowa, jest sposobem na uzyskanie dostępu do Internetu przy użyciu kabla koncentrycznego. Nowoczesne systemy technologi kablowej konwergują usługi dostarczając do domostw Internet, telewizję oraz telefonię. Technologie kablowe opisuje standard DOCSIS obecnie w wersji 3, pozwalającej na stosowanie HFC. Jest to topologia hybrydowa pozwalającą wykorzystanie połączenia światłowodowego pomiędzy np. budynkiem wielorodzinnym, a CO operatora. Umożliwia ona przepustowości nawet powyżej 1Gb/s.
W przypadku wyboru światłowodu jako metody na dostęp do Internetu, będzie mieć doczynienia z technologiami Fiber to the i do wyboru możemy mieć:
Obecnie stosowane technologie dostępu do szerokopasmowego Internetu, zapewniają dostęp do niego bez potrzeby przeciągania żadnych kabli. Do wyboru bowiem mamy technologie bezprzewodowe, spośród, których możemy wyróżnić:
Rozpatrując wybór technologii dostępu do Internetu, musimy również zadbać o bezpieczeństwo naszych połączeń. Należy pamiętać, że współdzielimy sieć operatora wraz z innymi abonentami. Jeśli pracownicy naszej firmy będą pracować zdalnie, muszą mieć zapewnione bezpieczne połączenie. I jednym punktem wejścia do firmowej sieci powinny być wirtualne sieci prytwane - VPN. Sieci tego typu są alternatywą dla drogich lączy dzierżawionych, ponieważ mogą wirtualnie zapewniać połączenie punkt-punkt. Sieci VPN zazwyczaj szyfrują swój ruch. Chociaż istnieją rodzaje tuneli (połączenia, wewnątrz innego połączenia), które formalnie są VPN, ale nie zapewniają tej warstwy szyfrowania. Korzyści jakie płyną ze stosowania VPN to:
Do zaimplementowania będziemy mieć dwa podejścia, w zależności od naszych potrzeb. Jeśli będziemy łączyć oddziały w firmie, to wybierzemy podejscie Site-to-site, gdzie tunel rozpoczyna się i kończy na routerach. Klienci nie są swiadomi tego, że ich ruch jest tunelowany (pakiety IP, są przesyłane wewnątrz innej transmisji IP). Drugim podejściem jest dostęp zdalny gdzie np. pracownicy pracują zdalnie i powinni korzystać z tunelu w trakcie pracy lub w momencie gdy potrzebują dostępu do konkretnego zasobu w sieci firmowej. Tunel wówczas jest zestawiany pomiędzy routerem a urządzeniem docelowym - laptopem pracownika.
Oczywiście musimy miec na uwadze fakt, że mogą zdarzyć się takie sytuacje, że nasz operator może mieć awarie i nasi pracownicy zdalni nie są wstanie podłączyć dokońca tunelu VPN. Taka sytuacja będzie mieć miejsce, w momencie nasze połączenie z usługodawcą jest w trybie single-homed - oznacza ono jedno łącze do usługodawcy, rozwiązaniem tego może być tryb dual-homed, który wprowadza nadmiarowość w łączach do operatora. Jednak w naszym przypadku to usługodawca jest kiepski i nonstop ma jakieś mniejsze lub większe awarie. Wówczas pozostaje nam zakupić łączne od kolejnego usługodawcy. Takie podejście nazywamy multihomed, a jeszcze lepiej by było, abyśmy mieli po dwa łącza do każdego z nich - dual-multihomed.
Podsumowanie
W tym rodziale zapoznaliśmy się z technologiami sieci rozległych. Ich działaniem oraz cechami charakterystycznymi poszczególnych ich rodzajów. Na koniec poznaliśmy popularne rodzaje łączności szerokopasmowych zapewniających dostęp do Intenetu. Wspomniane zostały także sieci VPN.
3.8. Koncepcje VPN oraz IPSec
Wirtualne sieci prywatne VPN są obecnie standardem zapewnienia bezpiecznego zdalnego dostępu do zasobów przedsiębiorstw. Sieci te wykorzystują publiczną infrastrukturę do przesyłania szyfrowanych danych.
Jeśli mówimy o sieciach VPN, często mamy namyśli szyfrowany tunel. Istnieje wyjątek od tej reguły. Protokół GRE firmy Cisco jest zwykłym tunelem sieci IP, nie zapewnia warstwy szyfrowania, służy do enkapsulowania protokołów IPv4 i IPv6 tworząc tym samym wirtualny tunel punkt-punkt.
W przypadku technologii VPN firmy najczęściej same zajmują się jej wdrażaniem wśród pracowników czy między oddziałami firmy, wówczas do wyboru dla połączeń lokacja-lokacja mamy takie rozwiązania jak:
Dla połączeń zdalnego dostępu możemy skorzystać z takich rozwiązań jak:
Jeśli firma nie posiada odpowiedniego personelu, który mógłby wdrożyć usługi VPN może wówczas skorzystać z usług VPN oferowanych przez usługowdawcę. Tego rodzaju sieci VPN operają się o protokół MPLS rozszerzając jego działanie na warstwę trzecią.
3.8.2. Rodzaje sieci VPN
W przypadku zdalnego dostępu, mamy dwie opcje - możemy skorzystać z przeglądarki (uwierzytelniając się na specjalnie przygotowanej do tego stronie) zabezpieczając połączenie przy użyciu SSL. Wówczas mówimy o połączeniu VPN bez klienta, połączenia wychodzące z przeglądarki są zabezpieczone tego typu tunelem. Ten tunel działa tylko i wyłącznie dla protokołów obsługiwanych z przez przeglądarki.
Innym rodzajem zdalnego dostępu jest użycie klienta VPN, w przypadku Cisco jest to program Any Connect Secure Mobilty. Użytkownicy muszą zainicjować połączenie VPN i uwierzytelnić się w bramie sieci VPN. Ruch uwierzytelnionych pracowników może być kierowany do sieci firmowej w celu uzyskania dostępu do jej zasobów. Oczywiście wszystko zależy od ustawionych tras. Oprogramowanie klienta szyfruje ruch za pomocą protokołów IPSec lub SSL.
Połączenie VPN przy użyciu SSL ma dość duże ograniczenia - jest więc dość rzadko stosowane. Tunele służące do dostępu zdalnego są najczęściej realizowane przy użyciu klienta VPN z wykorzystaniem szyfrowania IPSec.
Połączenia między routerami, a co za tym idzie między lokalizacjami, wykorzystują szyfrowanie IPSec. Tego rodzaju połączenia VPN są transparentne, użytkownicy sieci lokalnych nawet nie wiedzą, że ich połączenia są szyfrowane i przekazywane przez tunel, w siedzibie firmy brama VPN usuwa nagłówki, następnie deszyfruje i przekazuje pakiet do sieci wewnętrznej.
Wadą połączeń VPN z wykorzystaniem szyfrowania IPSec jest zdolność jedynie do przenoszenia ruchu unicast-wego. Taka zależność powoduje, że protokoły routingu wykorzystujące adresy multicast nie bedą mogły działać przez tunel. Rozwiązaniem tego problemu jest wspomniany już wcześniej protokół GRE, choć tutaj wadą tego protokołu jest brak warstwy bezpieczeństwa. Nie mniej jednak możliwe jest umieszczenie wewnatrz tunelu IPSec danych tunelu GRE. W tej technice używa się nazewnictwa protokołu transportowego - protokołu faktycznie używanego do przekazania pakietów, protokół przewoźnika - protokół używany do noszenia oryginalnego protokołu, w tym przypadku jest GRE oraz protokół pasażera - protokół faktycznie niosący dane, w przypadku protokołów routingu może to byc OSPF.
Połączenia lokacja-lokacja sprawdzają się w przypadku gdy oddziałów jest kilka. Ponieważ bramy VPN oddziałów wymagały statycznej konfiguracji każdego innego oddziału lub oddziału centralnego. Rozwiązaniem tego ograniczenia może być użycie technlogii DMVPN, która działa w technologii Hub-and-spoke. Lokalizacje są konifigurowane przy użyciu wielopunktowej enkapsulacji generycznej routingu (mGRE), wiec dodanie nowej lokalizacji wykorzysta tę samą konfigurację. Natomiast bramy VPN w poszczególnych oddziałach mogą wykorzystać informacje z lokalizacji centralnej do ustanowienia tuneli VPN pomiędzy sobą. Technologia DMVPN wykorzystuje tunel IPSec.
Innym uproszczeniem procesu konfigracji obsługi wielu lokalizacji i zdalnego dostępu jest VTI - interfejs wirtualnego tunelu IPsec. IPSec VTI może wysyłać i odbierać zaszyfrowanych ruch zarówno unicast IP jak i multicast dzięki czemu protokoły routingu są obsługiwane automatycznie i nie ma potrzeby stosowania GRE.
Dostawcy usług MPLS mogą zapewnić klientom zarządzane rozwiązanie VPN, wówczas za zabezpieczenie ruchu odpowiadać będzie dostawca. Istnieją dwa rodzaje rozwiązań MPLS VPN:
3.8.2. IPsec
IPsec to standard definiuje sposób zabezpieczenia VPN w sieciach IP. IPsec chroni i uwierzytelnia pakiety IP między źródłem a miejscem docelowym.
IPsec zapewnia następujące podstawowe funkcje bezpieczeństwa:
IPsec składa się z pięciu różnych funkcji zabezpieczeń:
Skojarzenia zabezpieczeń - SA, są podstawowym element składowym protokołu IPsec. Podczas ustanawiania łącza VPN, urządzenia peerów muszą wynegocjowawać powyższe parametry, aby mieć zgodne SA. Jeśli paramety zostaną ustalone wówczas dochodzi do zestawienia tunelu.
3.8. Podsumowanie
W tym rozdziale zapoznaliśmy się z koncepcjami VPN dowiedzialiśmy się czym są tak naprawdę wirtualne sieci prywatne. Omówiliśmy ich rodzaje, w których to używa się protokołu IPsec, który zapewnia bezpieczeństwo transmisji pakietów w.3. Standard ten tutaj również został omówiony. Poznaliśmy kilka dodatkowych technologii, pozwalających lepsze zarządzanie wieloma tunelami typu lokacja-lokacja.
3.9. Koncepcje QoS
Obecnie w sieciach występuje duże natężenie różnorakiego ruchu. Nowe rodzaje komunikatorów, zamiast wysyłania wyłącznie wiadomości tekstowych pozwalają na komunikację głosową czy transmisję wideo. Tego rodzaju transmisje zarówno dźwieku jak i obrazu w czasie rzeczywistym wymagają lepszych warunków sieciowych.
Niestety często jest tak, że wiele linii komunikacjnych gromadzi się pojedynczym urządzeniu, takim jak np. router. Takie ilości danych są następnie przesyłane przez kilka mniejszych łączy lub jedno łącze o niskiej przepustowości. Takie obchodzenie się z pakietami doprowadza najcześciej do zatorów. Jest to stan, w którym wydłuża się czas oczekiwania na informacje przesyłane przez sieć. Innym czynnikiem powodującym zatory jest transmisja dużych pakietów, która uniemożliwia dostęp do pasma tym mniejszym.Jeśli nie można przesłać, pewnych informacji ze względu na duże natężenie ruchu, pakiety te są kolejkowane w pamięci operacyjnej urządzeń, w oczekiwaniu na zwolnienie się łącza i swoją kolej do do przesłania. Oczywiście do urządzenia mogłą napływać dalsze transmisje tego rodzaju, czego urządzenie nie będzie mogło zmieścić, zostanie poprostu odrzucone. Takie zachowanie generuje opóźnienia we właściwej transmisji z aplikacji do aplikacji. Rozwiązanie tego typu problemu może być klasyfikowanie ruchu.
Router na podstawie różnych parametrów, może utworzyć dla całego ruchu kilka odrębnych kolejek i przesyłać ten ruch do hostów na podstawie przydzielonego kolejkom priorytetu.
Wraz z klasyfikacją ruchu sieciowego używa się kilku terminów, których wyjaśnienie znajduje się poniżej:
Spośród źródeł opoźnienia możemy wyróżnić sobie takie czynniki jak:
Powyższe aspekty transmisji danych, są częścią mechamizmów zapewniających jakość usług - QoS w sieciach IP.
W wyniku przeciążenia urządzenia może ono zacząć odrzucać pakiety. Bez mechaznizmów QoS, pakiety transmisji w czasie rzeczywistym są traktowane na równi z transmisją, której dane nie są za bardzo wrażliwe na opóźnienia. Utrata pakietów jest bardzo często przyczą problemów z jakością głosu w sieci IP. Kodeki obsługujące tego rodzaju ruch posiadają pewną tolerację utraty pakietów bez znacznej utraty jakości połączenia. Aby zapewnić czytelność transmisji w czasie rzeczywistym, używa się mechanizmów QoS do klasyfikowania pakietów pod kątem zerowej utraty pakietów. Często nadaje się tego rodzaju transmisjom pierwszeństwo na innymi mniej wrażliwymi na utratę pakietów.
3.9.1. Specyfikacja ruchu sieciowego
Na początku XXI w. w ruchu sieciowym można było zaobserwować takie transmisje jak klasyczna transmisja danych oraz transmisje głosowe VoIP. Obecenie również dużą częścią ruchu zajmują również transmisje wideo, zarówno spotkania przy użyciu komunikatorów jak i telewizja wykorzystująca obecnie w dużej mierze sieć Intenet. Te rodzaje ruchu mają bardzo specyficzne wymagania odnośnie jakości połączenia.
Ruch transmisji głosowej jest bardzo wrażliwy na opóźnienia oraz na utracone pakiety. Retransmisje w tym przypadku nie mają sensu, dlatego też ruch tego rodzaju musi mieć wyższy priorytet niż ruch innego rodzaju. Transmisje głosowe dopuszczają poźnienie do 150 ms, jitter do 30 ms, strata pakietów do 1% oraz wymaganie przepustowości od 30 do 128 Kb/s. Cechami charakterystycznymi tego ruchu są: płynność, łagodność, wrażliwość na opoźnienia i przerwania oraz preferencja transmisji UDP nad TCP.
W przypadku ruchu wideo jest on bardziej niespójny i nieprzewidywalny w porównaniu do ruchu głosowego. W zależności od dynamiki wyświetlanych treści ruch ten może przesłać znacznie więcej danych tym samym odcinku czasu. Podobnie do ruchu głosowego, ruch ten jest wrażliwy na warunki sieciowe, ale nie aż tak bardzo jak ruch głosowy. Ruch wideo również powinien posiadać zwiększony priorytet, kosztem ruchu mniej wrażliwego na zakłócenia - takiego jak ruch danych. W przeciwnym wypadku transmisje czy strumienie wideo mogą być niezdatne do oglądania. Transmisje wideo dopuszczają opoźnienia na poziomie do 200 - 400 ms. Jitter do 30-50 ms, stratę pakietów na poziomie od 0,1% do 1% oraz minimalną przepustowość na poziomie od 384 Kb/s do 20 Mb/s. Cechy charakterystyczne dla ruchu wideo to: gwałtowność, zachłanność, wrażliwość na przerwania i opóźnienia oraz wybór UDP nad TCP.
W przypadku transmisji danych aplikacje wykorzystują protokoły UDP oraz TCP. Gdy aplikacja nie toleruje błędów, wybrany zostanie protokoł TCP nad UDP, gdyż dokonuje on korekcji błędów przez retransmisje. Ruch danych może być płynny lub gwałtowny, ale zazwyczaj jest płynny i przewidywalny. Przypadku ruchu danych to niektóre aplikacje TCP mogą wykorzystać tyle przepustowości ile da się uzyskać. Ruch danych jest stosunkowo niewrażliwy na spadki i opóźnienia w porównaniu z ruchem wideo czy głosowym, to przy ustalaniu priorytetów, należy wziąć po uwagę doświadczenia użytkowników - istnieją dwa kryteria:
Jeśli aplikacja jest interaktywa, a dane są krytyczne to należy ustawić priorytet dla ruchu tej aplikacji aby uzyskać opoźnienia mieszczące się w granicach ludzkiego czasu reakcji. Około 1 do 2s. Jeśli na dane nie są krytyczne do aplikację zyskają na większym priorytecie/mniejszym opoźnieniu.
Jeśli aplikacja jest nie interaktywna, a dane są krytyczne to opóźnienie może znacznie się różnić, o ile zostanie zapewniona minimalna przepustowość. Jeśli dane są nie krytyczne, aplikacja może pobrać dla siebie pozostałą część przepustowości związaną z obsługą głosu, wideo oraz innych danych.
3.9.2. Algorytm kolejkowania
Do implementacji jakości usług potrzebne są algorytmy kolejkowania. Te mechanizmy stają się aktywne gdy na łączu występuję przeciążenie. Kolejkowanie jest narzędziem do zarządzania ograniczeniami, które można buforować ustalać priorytety i ewentualnie, jeśli to konieczne zmieniać kolejność pakietów przed przesłaniem ich do miejsca docelowego. Do wyboru mamy takie algorytmy jak:
Pierwszą kolejką jest FIFO. Jest to najprostszy model kolejki, przekazuje on pakiety dalej w kolejności ich przybycia. Kolejka tego typu nie rozpoznaje ani priorytetów, ani klas ruchu. Ta kolejka może dopuścić do utraty pakietów ważnego dla nas ruchu. Jeśli nie są wdrożone żadne inne kolejki jest domyślna kolejka dla wszystkich interfejsów z wyjątkiem interfejsów szeregowych E1 (europejskie łącza dzierżawione).
WFQ jest zautomatyzowaną metodą planowania, zapewniającą uczciwy podział przepustowści dla całego ruchu. WFQ stosuje priorytet lub wagi do zidentyfikowania ruchu. WFQ nie zezwala na konfiguracji opcji klasyfikacji. WFQ klasyfikuje ruch do rozmów lub przepływów, następnie określa ile każdy przepływ ma otzymać przepustowości względem innych. WFQ umożliwia nadanie niewielkiemu interaktywnemu ruchowi typu SSH lub ruch głosowy pierszeństwa w stostunku do dużego ruchu takiego jak FTP. WFQ opiera swoje klasyfikacje na adresacji pakietów, adresach MAC, numerach protów, protokołach oraz wartości pola typu usługi (ToS) w nagłówku IPv4. Przy ruchu o niskiej przepustowości otrzymają usługę preferencyjną, która pozwoli na terminowe przesłanie całego ładunku transmisji. Wiekszy ruch jest dzielony proporcjonalnie między pozostałą przepustowość. WFQ nie jest obsługiwana przez funkcje tunelowania oraz szyfrowania, ponieważ te funkcje modyfikują informacje o zawartości pakietów wymaganej przez WFQ do klasyfikacji. Mechanizm ten również trochę mniej precyzyjnie zapewnia kontrolę nad alokacją pasma.
CBWFQ rozszerza standardową funkcjonalność WFQ zapewniając obsługę klas ruchu. Za pomoca CBWQF możemy zdefiniować klasy na podstawie dopasowania do protokołów, listy ACL, czy interfejsów wejściowych. Klasy są przypisywane według kryteriów dopasowania. Definiując klasę określamy jej przepustowość, wagę czy maksymalny limit pakietów, zdefiniowana przepustowość jest to gwarantowana szerokość pasma dostarczana klasie podczas przeciążenia. Chcąc określić klasę, należy również określić limit kolejki dla tej klasy, tj. maksymalną liczbę pakietów, które mogą się w niej znajdować. Po osiągnięciu tego limitu pakiety każdy pakiet docierający na koniec kolejki (nowy pakiet) będzie porzucany. Ten mechanizm nazywa się tail drop - porzucenie ogona. Tail drop, traktuje ruch jednakowo i nie rozróżnia klas usług.
LLQ jest funkcja kolejki zapewniająca ścisłe kolejkowanie priorytetowe (PQ) dla CBWFQ. Ścisłe PQ zapewnia wysłanie pakietów wrażliwych na opoźnienia takich jak transmisja głosowa przed pakietami w innych kolejkach. LLQ zapewnia ścisłą kolejkę priorytetową dla CBWFQ, zmieniejszając zniekształcenia w transmisji głosowej.
3.9.3. Modele QoS
Istnieją trzy modele QoS, które możemy wdrożyć:
QoS jest zaimplementowany w sieci przy użyciu IntServ lub DiffServ. Podczas gdy IntServ zapewnia najwyższą gwarancję jakości usług jest bardzo zasobochłonny, a zatem nie jest łatwo skalowalny. Natomiast DiffServ jest mniej zasobochłonny i bardziej skalowalny. Te dwa podejścia są czasami współwdrażane w sieciowych implementacjach QoS.
Modele do wdrożenia QoS:
3.9.4. Techniki wdrażania QoS
Utrata pakietów jest zwykle wynikiem przeciążenia na interfejsie. Większość aplikacji korzystających z protokołu TCP spowoduje to spowolnienie, ponieważ TCP automatycznie dostosowuje się do przeciążenia sieci. Porzucone segmenty TCP powoduje, że sesje TCP zmniejszają rozmiary okien. Niektóre aplikacje nie używają TCP i nie obsługują zrzutów. Następujące podejścia mogą zapobiegać spadkom w aplikacjach wrażliwych:
Narzędzia do wdrażania QoS:
Zanim pakiet będzie mógł mieć zastosowaną politykę QoS musi zostać sklasyfikowany. Klasyfikacja i znakowanie pozwalają nam identyfikować lub oznaczać typy pakietów. Klasyfikacja określa klasę ruchu, do której należą pakiety lub ramki. Dopiero po zaznaczeniu ruchu można zastosować do niego zasady.
Sposób, w jaki pakiet jest klasyfikowany, zależy od implementacji jakości usług. Metody klasyfikacji przepływów ruchu na warstwie 2 i 3 obejmują korzystanie z interfejsów, ACL i map klas. Ruch można również klasyfikować w warstwach od 4 do 7 przy użyciu funkcji rozpoznawania aplikacji sieciowych (NBAR).
Oznakowanie ruchu dla QoS:
Standard 802.1Q obejmuje również schemat priotetyzacji QoS znany jako IEEE 802.1p. Wykorzystuję on pierwsze trzy bity w polu TCI (Tag Control Information), znane jako pole priorytetu PRI (Priority), to 3-bitowe pole identyfikuje oznaczenia klasy usług (CoS). Trzy bity oznaczają, że ramką Ethernet warstwy 2 może być oznaczona jednym z ośmiu poziomów priorytetu (wartość 0-7).
Wartość klasy usług (CoS) Ethernet:
IPv4 i IPv6 określają 8-bitowe pole w nagłówkach pakietów: Type of Service (ToS) dla IPv4 oraz pole Trafic Class dla IPv6.
Typu usługi (IPv4) i klasa ruchu (IPv6) zawierają oznaczenia pakietów przypisane przez narzędzia do klasyfikacji QoS. To pole jest następnie okreslane przez urządzenia odbierające, które przekazują ruch w oparciu o odpowiednio przypisną politykę jakości usług. RFC 2474 zastępujący RFC 791 i na nowo definiuje pole ToS poprzez zmianę nazwy i oraz rozszerzenie pola IP Precedence (IPP), które wcześniej było używane do oznaczeń QoS - RFC 791. Nowe pole na 6-bitów przydzielone do QoS. Nazwane DSCP (Differentiated Services Code Point) przez długość 6 bitów oferuje maksymalnie 64 klasy usług. Pozostałe dwa bity IP Extended Congestion Notification (ECN) mogą być używane przez routery obsługujące ECN do oznaczanie pakietów zamiast ich odrzucania. Oznakowanie ECN informuje urządzenia o występującym przeciążęniu w ruchu pakietów.
Wartość DSCP są podzielone na trzy kategorie:
Gwarantowane wartości przesyłania. Kolejki posortowane są od najlepszej do najgorszej.
AFxy - wzór jest określony w następujący sposób:
Na przykład AF32 należy do klasy 3 (binarny 011) i ma preferencje średniej utraty pakietów (binarny 10). Pełna wartość DSCP wynosi 28, ponieważ zawiera 6 bit 0 (binarny 011100).
Ponieważ pierwsze 3 bity pola DSCP wskażują klasę, bity te są również nazywane bitami selektora klasy (CS). Te 3 bity odwzorwują bezpośrednio 3 bity pola CoS i pola IPP, aby zachować zgodność z 802.1p i RFC 791.
Ruch powinien być klasyfikowany i oznaczony tak blisko źródła, jak jest to technicznie i administracyjnie wykonalne. Granicę zaufania definiują:
Często również dochodzi do ponownego oznaczenia ruchu, np. przekładając wartość CoS na IPP lub DSCP.
Zarządzanie zatorami obejmuje kolejkowanie i metody planowania, w których nadmiarowy ruch jest buforowany lub umieszczany w kolejce (a czasami odrzucany), gdy czeka na wysłanie przez interfejs wyjściowy. Narzędzia do unikania monitorują obciążenie ruchu sieciowego, starając się przewidywać i unikać zatorów we wspólnych wąskich gardłach sieci i intersieci, zanim zatory staną się problemem.
Niektóre techniki unikania zatorów zapewniają preferencyjne traktowanie, w przypadku którego pakiety są odrzucane. Na przykład Cisco IOS QoS obejmuje ważone losowe wczesne wykrywanie (WRED) jako możliwe rozwiązanie pozwalające uniknąć zatorów. Algorym WRED pozwala na unikanie przeciążeń na interfejsach sieciowych, zapewniając zarządzania buforami i pozwalając na zmniejszenie lub ogranicznie ruchu TCP przed wyczpaniem buforów. Korzystanie z WRED pomaga uniknąć spadków i maksymalizuje wykorzystanie sieci i wydajność aplikacji opartych na protokole TCP. Nie ma jednak techniki unikania zatorów w ruchu opartym na protokole UDP (User Datagram Protocol), takim jak ruch głosowy. W przypadku ruchu opartego na UDP metody takie jak kolejkowanie i techniki kompresji pomagają zmniejszyć, a nawet zapobiec utracie pakietów UDP.
Kształtowanie ruchu i kształtowanie polityki to dwa mechanizmy zapewniane przez oprogramowanie Cisco IOS QoS w celu zapobiegania zatorom. Kształtowanie ruchu zatrzymuje nadmiarowe pakiety w kolejce, a następnie planuje nadwyżkę od poźniejszej transmisji w odstępach czasu. Wynikiem kształtowania ruchu jest wygładzona szybkość przesyłania pakietów. Kształtowanie implikuje istnienie kolejki i wystarczające ilości pamięci do buforowania opóźnionych pakietów, podczas gdy zasady nie działają. Kształtowanie wymaga funkcji planowania dla poźniejszej transmisji wszelkich opóźnionych pakietów. Kształtowanie jest koncepcją wychodzącą - pakiety wychodzące do interfejsu są umieszczane w kolejce i mogą być kształtowane. Natomiast polityka jest stosowan dla ruchu przychodzącego na interfejsie. Gdy natężenie ruchu osiągnie skonfigurowaną maksymalną szybkość, nadmiar ruchu jest odrzucany (lub oznaczany). Usługi polityki są powszechnie wdrażane przez dostawców usług w celu wyegzekwowania wkaźnika informacji o klientach objętych umową (CIR). Jednakże dostawca usług może również zezwolić na przepuszczanie przez CIR, jeśli sieć usługodawcy nie jest obecnie przeciążona.
Polityka QoS musi uwzględniać pełną ścieżkę od źródła do celu. Jesli jedno z urządzeń używa innej zasady niż jest wymagane, może mieć to wpływ na całą implementację QoS. Na przykład zacina się podczas odtwarzania wideo może być wynikiem jednego przełącznika na ścieżce, który nie ma odpowiedniej wartości CoS. Poniżej znajduje się kilka wskazówek, które pomgają zapewnić lepsze wrażenia użytkownikom końcowym:
Podsumowanie
Na początku zdefiniowaliśmy sobie takie pojęcia jak klasyfikowanie ruchu, opoźnienia i jitter. Dowiedzilismy się także czym grozi utrata ruchu. Następnie sklasyfikowaliśmy sobie ruch sieciowy, poznaliśmy algorytm kolejkowania oraz modele QoS na koniec zaznajomiliśmy się z teoretycznymi podstawmi technik wdrażania mechnizmu QoS.
3.10. Zarządzanie siecią
Za pomocą protokołu CDP możemy utworzyć mapę sieci. CDP to zastrzeżony protokół warstwy 2 firmy Cisco, który służy do zbierania informacji o urządzeniach Cisco współużytkujących to samo łącze danych. Protokół CDP jest niezależny od mediów czy innych protokołów działa na wszystkich urządzeniach Cisco, takich jak routery, przełączniki czy serwery dostępowe.
Urządzenia wysyłają między sobą okresowe ogłoszenia CDP z informacjami na temat rodzaju wykrytego urządzenia, jego nazwie oraz typie i ilości interfejsów. Protokół ten może pomóc w podejmowaniu decyzji dotyczących projektu sieci, rozwiązywaniu problemów czy wprowadzaniu zmian w sprzęcie. Protokół może być również używany jako narzędzie do wykrywania sieci w celu określenia informacji i sąsiednich urządzeniach. Te informacje mogą pomóc przy tworzeniu logicznej topologii sieci.
Protokół CDP jest domyślnie włączony na wszystkich urządzeniach w sieci, jednak ze względów bezpieczeństwa może być pożądne jego wyłączenie, na niektórych interfejsach bądź globalnie. Może on zdradzać cenne informacje jakie adresy IP, wersja Cisco IOS oraz typ urządzenia.
Aby zweryfikować stan CDP i wyświetlić informacje o CDP w trybie uprzywilejowanym EXEC wydajemy następujące polecenie:
Router# show cdp
Global CDP information:
Sending CDP packets every 60 seconds
Sending a holdtime value of 180 seconds
Sending CDPv2 advertisements is enabled
Aby wyłączyć CDP globalnie dla wszystkich obsługiwanych interfejsów w trybie konfiguracji globalne wydajemy następujące polecenie:
Router(config)# no cdp run Router(config)# exit Router# show cdp CDP is not enabled
Natomiast włączenie globalne CDP, odbywa się w tym samym trybie przy użyciu następującego polecenia:
Router(config)# cdp run
Wyłączenie oraz włączenie CDP dla interfejsów odbywa się w trybie
konfiguracji interfejsu, poprzez wydanie polecenia
no cdp enable - dla wyłączenia CDP na
interfejsie lub cdp enable dla
włączenia CDP na interfejsie.
Aby wyświetlić listę sąsiadów, możemy użyć polecenia
show cdp neighbors w trybie
uprzywilejowanym EXEC. CDP zwraca kilka przydanych informacji.
Router#show cdp neighbors
Capability Codes: R - Router, T - Trans Bridge, B - Source Route Bridge
S - Switch, H - Host, I - IGMP, r - Repeater, P - Phone
Device ID Local Intrfce Holdtme Capability Platform Port ID
Switch Gig 0/1 146 S 2960 Gig 0/2
Za pomocą polecenia show cdp interface
możemy wyświetlić podsumowanie interfejsów z włączonym CDP.
Router#show cdp interface Vlan1 is administratively down, line protocol is down Sending CDP packets every 60 seconds Holdtime is 180 seconds GigabitEthernet0/0 is administratively down, line protocol is down Sending CDP packets every 60 seconds Holdtime is 180 seconds GigabitEthernet0/1 is up, line protocol is up Sending CDP packets every 60 seconds Holdtime is 180 seconds
Polecenie show cdp neighbors zawiera
przydantne informacje o każdym sąsiednim urządzeniu.
Router#show cdp neighbors
Capability Codes: R - Router, T - Trans Bridge, B - Source Route Bridge
S - Switch, H - Host, I - IGMP, r - Repeater, P - Phone
Device ID Local Intrfce Holdtme Capability Platform Port ID
Switch Gig 0/1 146 S 2960 Gig 0/2
Zadanie praktyczne - Packet Tracer
Użyj CDP do mapowania sieci - scenariusz
Użyj CDP do mapowania sieci - zadanie
3.10.1. Odkrywanie urządzeń z protokołem LLDP
Protokół LLDP (Link Layer Discovery Protocol) robi to samo co CDP, ale jest on protokołem otwartym, dostępnym również na sprzęcie Cisco.
W zależności od urządzenia LLDP może być domyślnie wyłączone, tak też jest w przypadku sprzętu Cisco (preferują swój protokół CDP). Aby włączyć protokół LLDP, w trybie konfiguracji globalnej wydajemy poniższe polecenie:
Switch(config)#lldp run
Protokół LLDP możemy włączyć również niekoniecznie dla całego urządzenia, ale dla konkretnych interfejsów. W przeciwieństwie do CDP, LLDP na interfejsie musi być skonfigurowany zarówno do odbierania i wysyłania pakietów, tak jak na poniższym przykładzie:
Switch(config)# interface gigabitethernet 0/1 Switch(config-if)# lldp transmit Switch(config-if)# lldp receive Switch(config-if)# end
Za pomocą polecenia show lldp możemy
sprawdzić stan protokołu na naszym urządzeniu. Natomiast za pomocą
polecenia show lldp neighbors możemy
wyświetlić listę wykrytych sąsiadów oraz kilka informacji o nich.
Router#show lldp
Global LLDP Information:
Status: ACTIVE
LLDP advertisements are sent every 30 seconds
LLDP hold time advertised is 120 seconds
LLDP interface reinitialisation delay is 2 seconds
Router#show lldp neighbors
Capability codes:
(R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device
(W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other
Device ID Local Intf Hold-time Capability Port ID
Switch Gig0/1 120 B Gig0/2
Total entries displayed: 1
LLDP zwraca podobną ilość informacji jak CDP, jedak brakuje tutaj informacji o platformie. Przełączniki tutaj są oznaczane jako mosty (B - Bridge).
Zadanie praktyczne - Packet Tracer
Użyj LLDP do mapowania sieci - scenariusz
Użyj LLDP do mapowania sieci - zadanie
3.10.2. NTP
Poprawne ustawienie daty i czasu na urządzeniach sieciowych jest ważne
jeśli korzystamy z usługi dziennika - syslog (omówiony poźniej
w tym rozdziale). Samą czynność ustawienia bierzącej daty i czasu
możemy dokonać na dwa sposóby, albo za pomocą polecenia
clock set w trybie uprzywilejowanym
EXEC, albo za pomocą protokołu NTP. Mając wiele urządzeń ciężko sobie
wyobrazić, że będziemy ręcznie ustawiać wszystkie zegary, dlatego też
wykorzystamy protokół NTP.
Protokół NTP umożliwia routerom w sieci synchronizację ustawień czasu z serwerem NTP. Klienci wykorzystujący NTP, uzyskują informacje o czasie i dacie z jednego źródła i mają bardziej spójne ustawienia czasu. Protokół NTP jest zaimplementowany w sieci, mozna go skonfigurować tak, aby synchronizował się z prywatnym zegarem głównym lub może synchronizować się z publicznie dostępnym serwerem NTP w Internecie. NTP używa protokołu UDP na port 123.
Protokół NTP jest usługą hierarchiczna, każdy z poziomów nazywany jest warstwą lub Stratum, im niższa warstwa czas jest mniej dokładny. Warstwa maksymalnie jest 15. Wartstwa 0 zawiera urządzenia wystawiające wzrorzec czasu, kiedy przechodzi między warstwami jego stan odchyla się stanu rzecywistego (są to wartości, które zwykłym ludzią nie robią różnice, ale jednak występują). Warstwa 16 oznacza brak synchronizacji z NTP.
Konfiguracja serwera NTP na sprzęcie Cisco polega na wydaniu poniższego polecenia w trybie konfiguracji globalnej.
R1(config)# ntp server 209.165.200.225
Synchronizacje naszego urządzenia z serwerem NTP możemy zweryfikować za pomocą poleceń:
R1# show ntp associations address ref clock st when poll reach delay offset disp *~209.165.200.225 .GPS. 1 61 64 377 0.481 7.480 4.261 * sys.peer, # selected, + candidate, - outlyer, x falseticker, ~ configured R1# show ntp status Clock is synchronized, stratum 2, reference is 209.165.200.225 nominal freq is 250.0000 Hz, actual freq is 249.9995 Hz, precision is 2**19 ntp uptime is 589900 (1/100 of seconds), resolution is 4016 reference time is DA088DD3.C4E659D3 (13:21:23.769 CET Mon Dec 09 2024) clock offset is 7.0883 msec, root delay is 99.77 msec root dispersion is 13.43 msec, peer dispersion is 2.48 msec loopfilter state is 'CTRL' (Normal Controlled Loop), drift is 0.000001803 s/s system poll interval is 64, last update was 169 sec ago.
Serwer NTP znajduje się w warstwie 1, swiadczy o tym kolumna
st zwracana przez polecenie
show ntp associations. Nasz router,
zaś w warstwie drugiej, urządzenia Cisco, które są skonfigurowane
na synchonizację czasu z NTP, automatycznie też stają się serwerami
tej usługi świadcząc wzorzec czasu na danym poziomie w sieci.
Zadanie praktyczne - Packet Tracer
Skonfiguruj i zweryfikuj NTP - scenariusz
Skonfiguruj i zweryfikuj NTP - zadanie
3.10.3. SNMP
SNMP został opracowany aby umożliwić administratorom zarządzanie wezłami, takimi jak serwery, stacje robocze, routery, przełączniki itp. Umożliwia administratorom sieci monitorowanie jej wydajności, zarządzanie nią znajdowanie i rozwiązywanie problemów, planowanie rozwoju sieci. SNMP jest protokołem warstwy aplikacji, zapewniającymi format wiadomości, wykorzystywany w komunikacji pomiędzy urządzeniami, tzw. menedżerami a agentami. System SNMP składa się z trzech elementów:
Menadżer SNMP jest częścią zarządzania siecią. Uruchamia się na nim oprogramowanie do zarządzania SNMP. Może on zbierać informacje od agenta SNMP za pomocą akcji get i zmieniać konfigurację za pomocą akcji set. Dodatkowo agenci mogą przekażywać informacje bezpośrednio do menedżera sieci za pomocą traps (pułapek).
Agent SNMP i baza MIB znajdują się na urządzeniach klienckich SNMP. Urządzenia sieciowe wyposażone są w oprogramowanie agenta SNMP. Bazy MIB przechowuje dane o urządzeniu oraz statystyki operacyjne. Agent SNMP jest również odpowiedzialny za zapewnienie dostępu do bazy MIB. Protokół określa też, w jaki sposób informacje sterujące wymieniane są miedzy aplikacjami zarządzającymi siecią a agentami. Menedżer SNMP bada agentów i wysyła zapytania dla agentów SNMP na porcie UDP 161, agenci wysyłają pułaki do menedzera na porcie 162 UDP.
Pułapki (Traps) to komunikaty alarmowe generowane bez żądania, informujące menedżera SNMP o stanie sieci i ewentualnych zdarzeniach, które wystąpiły. Przykładowo komunikaty trap mogą zawierać informacje i nieprawidłowym uwierzytelnieniu, zmianach stanu łączy, czy nawet zamknięciach połączeń TCP. Powiadomienia kierowane przez pułapki zmniejszają zasoby sieci i agentów, eliminując potrzebę niektórych żądań odpytywania SNMP.
SNMP istnieje w 3 wersjach. Wersja 1 jest starym roziwązaniem i nie jest już często spotykana. W ramach tego kursu zajmiemy się wersjami 2c oraz 3. Druga wersja zawiera mechamizmy grupowego pobierania i szczegółowego raportowania do menedżerów, posiada ona także poprawioną obsługę błędów w tym rozszerzone kody błędów. Wersja 1 oraz 2 oferują minimalne funkcje bezpieczeństwa, co zostało poprawione z wersją 3 posiada ona bowiem kilka dodatkowych modeli i poziomów bezpieczeństwa:
Wybór odpowiedniej wersji SNMP wymaga konfiguracji agenta na urządzeniu, ponieważ może on komunikować się z wieloma menedżerami SNMP, możliwe jest skonfigurowanie oprogramowania do obsługi komunikacji przy użyciu protokołu SNMPv1, SNMPv2c lub SNMPv3.
W celach uwierzytelniania, protokoły SNMPv1 oraz SNMPv2 wykorzystują tzw. community strings - łańcuchy społeczności, które kontrolują dostęp do bazy MIB. Są to hasła zapisane jawnym tekstem. Łańcuchy społeczności SNMP uwierzytelniają dostęp do obiektów MIB.
Istnieją dwa rodzaje ciągów społeczności:
Zmienne MIB pozwalają oprogramowaniu zarządzającemu na monitorowanie i zarządzanie urządzeniami. Zmienne są zorgranizowane w sposób hierachiczny. Formalnie, baza MIB definiuje każdą zmienną przy pomocy identyfikatora obiektu OID. OID umożliwia unikatową identyfikację zarządzanych obiektów w hierarchii MIB. Baza MIB organizuje obiekty OID w sposób hierarchiczny, zazwyczaj w postaci drzewa bazujac na standardadach RFC. Standardy te definiują wspolne zmienne publiczne. Większość urządzeń implementuje te zmienne MIB. Ponadto, producenci sprzętu sieciowego, tacy jak Cisco, mogą definiować własne gałęzie drzewa i tym sposobem wprowadzać nowe zmienne specyficzne dla swoich urządzeń. Identyfikatory należą do Cisco są ponumerowane w następujący sposób: .iso(1) .org(3) .dod(6) .internet(1) .private(4) .enterprises(1) .cisco(9). Dlatego OID to .1.3.6.1.4.1.9.
Chcąc uzyskać jakieś informacje za pomocą SNMP możemy wydać następujące polecenie.
$ snmpget -v2c -c community 10.250.250.14 .1.3.6.1.4.1.9.2.1.58.0 SNMPv2-SMI::enterprises.9.2.1.58.0 = INTEGER: 11
To polecenie jest element wieloplatformowego pakiety obsługującego
protokół SNMP. -v2c - jest wersją
protokołu SNMP, -c community - jest
podanie ciągu społeczności, następnie występuje adres oraz numer OID
pobieranego parametru. Tym parametrem jest 5-minutowa średnia krocząca
procentu zajętości procesora.
Laboratorium
Oprogramowanie do monitorowania sieci badawczej
3.10.4. Syslog
Syslog - standard uzyskiwania dostępu do komunikatów systemowych (wpisów dziennika zdarzeń), również pod postacią protokołu sieciowego pozwalającego na wysłanie powiadomień do specjalnie przygotowanego serwera. Syslog używa portu 514 UDP.
Usługi rejestrowania syslog zapewniają trzy podstawowe funkcje takie jak:
Urządzenie Cisco generują komunikaty syslog w następstwie różnych zdarzeń sieciowych. Każdy komunikat syslog zawiera obiekt, którego dotyczy oraz stopień ważności. Im niższy numer stopnia ważności, tym poważniejszy problem sygnalizowany przez urządzenie. Poniżej znajduje się lista poziomów syslog.
Oprócz poziomu ważności, komunikaty syslog zawierają także informacje o obiekcie, którego dotyczą. Obiety syslog to identyfikator usługi, pozwalającej zidentyfikować i skategoryzować dane na temat stanu systemu na potrzeby raportowania błedów i zdarzeń. Opcje rejestrowania, dostępne dla danego obiektu są specyficznego dla danych urządzeń. Do typowych obiektów syslog, raportowanych w komunikatach na routerach z systemem Cisco IOS, należą:
Domyślny format komunikatów syslog oprogramowania Cisco IOS, wygląda następująco:
%facility-severity-MNEMONIC: description
Natomiast przykładowy komunikat z systemu Cisco IOS może wyglądać w następujący sposób:
%LINK-3-UPDOWN: Interface Port-channel1, changed state to up
Obiektem tutaj jest LINK, ustawiono
poziom ważności komunikatu na 3, natomiast nazwą menmoniczną jest
obiektu jest UPDOWN.
Domyślnie komunikaty diagnostyczne zwracane przez urządzenie wyświelane i przekazywane poźniej do syslog bez daty czy godziny. Co może czynić je bezużytecznymi. Jednak możemym użyć poniższego polecenia w trybie konfiguracji globalnej, aby wymusić wyświetlanie zrejestrowanych zdarzeń z datą oraz godziną.:
R1(config)# service timestamps log datetime
3.10.5. Konserwacja plików routera i przełącznika.
System plików Cisco IOS (IFS) umożliwia administratorowi przechodzenie do różnych katalogów i wyświetlanie listy plików w katalogu. Administrator może również tworzyć podkatalogi w pamięci flash lub na dysku. Dostępność katalogów zalęzy od urządzenia.
Za pomocą polecenia show file systems,
możemy wyświelić listę obsługiwanych przez nasze urządzenie systemów
plików.
Dla nas najbardziej istotnymi systemami plików (obsługa) będzie TFTP,
pamięć flash oraz pamięć NVRAM. Wyświetlenia zawartości
pamięci flash, możemy dokonać za pomocą polecenia
dir. Natomiast aby wyświetlić
zawartość NVRAM, należy przejść do niej i wydać ponownie polecenie
dir. Pokazano to na poniższym
przykładzie.
Router#
Router# cd nvram:
Router# pwd
nvram:/
Router# dir
Directory of nvram:/
32769 -rw- 1024 startup-config
32770 ---- 61 private-config
32771 -rw- 1024 underlying-config
1 ---- 4 private-KS1
2 -rw- 2945 cwmp_inventory
5 ---- 447 persistent-data
6 -rw- 1237 ISR4221-2x1GE_0_0_0
8 -rw- 17 ecfm_ieee_mib
9 -rw- 0 ifIndex-table
10 -rw- 1431 NIM-2T_0_1_0
12 -rw- 820 IOS-Self-Sig#1.cer
13 -rw- 820 IOS-Self-Sig#2.cer
33554432 bytes total (33539983 bytes free)
Router#
Wersje systemów IOS na przełączniki również obsługują kilka rodzajów plików. Na pewno te same, które mogą nas interesować. Pełną listę wspieranych przez przełączniki systemów plików, możemym podejrzeć znanym nam już poleceniem.
Wiele programów pozwalających nam podłączyć nasz system do konsoli urządzenia posiada w swoich opcjach funkcje logowania sesji, to jest zapisania do tekstowego wszystkie co jest wyświetlone w oknie programu. Dzięki tej funkcji możemy wyświetlić bierzącą konfigurację i automatycznie zapisać ją jako kopię bezpieczeństwa. Niektóre z programów pozwalają nawet wysłać pliki linia po linii przez konsole do urządzenia jako kolejne wpisywane polecenia.
Innym sposobem zachowanie kopii konfiguracji, może być użycie
serwera TFTP (prostej usługi transferu plików, bez uwierzytelniania,
bez poleceń, poprostu adres serwera, nazwa docelowa dla pliku i plik
zostaje przesłany. To samo w odwrotną strone. TFTP używa protokołu UDP
zamiast TCP). TFTP jest docelowym systemem plików. Do wykonania kopii
wykorzystamy standardowe polecenie copy
R1# copy running-config tftp Remote host []?192.168.10.254 Name of the configuration file to write[R1-config]? R1-Gru-2024 Write file R1-Gru-2024 to 192.168.10.254? [confirm] Writing R1-Gru-2024 !!!!!! [OK]
Niektóre z routerów Cisco są wyposarzone w porty USB, pozwalają one
podłączenie pamięci flash USB firmy Cisco i wykonanie na nich
kopii zapasowej czy to konfiguracji czy też obrazów z systemem IOS.
Procedura wygląda identycznie jak w przypadku protokołu TFTP, ale
zamiast tftp podajemy
usbflash0: i przywracanie również wygląda analogicznie.
Jednak co się stanie jeśli zapomnimy hasła do np. trybu uprzywilejowanego? Otóż posiadając fizyczny dostęp do urządzanie, mogąc podłączyć się do niego za pomocą konsoli. Jednak to nie wszystkie czynności jakie trzeba wykonać. Po podłączeniu konsoli należy:
Zadanie praktyczne - Packet Tracer
Tworzenie kopii zapasowych plików konfiguracyjnych - scenaiusz
Tworzenie kopii zapasowych plików konfiguracyjnych - zadanie
Laboratorium
Użyj Tera Term do zarządzania plikami konfiguracyjnymi routera
Stosowanie TFTP, Flash i USB do zarządzania plikami konfiguracyjnymi
Zbadaj procedury odzyskiwania hasła
3.10.6. Zarządzanie obrazami IOS
Podobnie do plików konfigurajcyjnych możemy chcieć zapisać - oczywiście ze względów bezpieczeństwa obraz Cisco IOS na naszym serwerze. Jednak najbardziej prawdopodobnym scenariuszem będzie sytuacja odwrotna, gdzie wykorzystamy nasz serwer TFTP do aktualizacji wersji IOS na naszym urządzeniu. Z serwerem TFTP mieliśmy styczność we wcześniejszym podrozdziale. Aby dokonać takie aktualizacji, na początku sprawdzamy czy nasz serwer TFTP jest osiągalny z naszego urządzenia - za pomocą polecenia ping.
R1# ping 2001:db8:cafe:100::99 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 2001:DB8:CAFE:100::99, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 56/56/56 ms
Następnie za pomocą ostaniej linii wyjścia polecenia
show flash: ostalamy ilość wolnego
miejsca w pamięci flash.
R1# show flash: -# - --length-- -----date/time------ path ... 6294806528 bytes available (537251840 bytes used) R1#
Następną czynnością jest skopiowanie obrazu IOS z TFTP do pamięci flash.
R1# copy tftp: flash: Address or name of remote host []?2001:DB8:CAFE:100::99 Source filename []? isr4200-universalk9_ias.16.09.04.SPA.bin Destination filename [isr4200-universalk9_ias.16.09.04.SPA.bin]? Accessing tftp://2001:DB8:CAFE:100::99/ isr4200- universalk9_ias.16.09.04.SPA.bin... Loading isr4200-universalk9_ias.16.09.04.SPA.bin from 2001:DB8:CAFE:100::99 (via GigabitEthernet0/0/0): !!!!!!!!!!!!!!!!!!!! [OK - 517153193 bytes] 517153193 bytes copied in 868.128 secs (265652 bytes/sec)
Po zakończonym kopiowaniu należy pamiętać o aktualizacji domyślnego obrazu IOS. Dokonać tego możemy za pomocą poniższego polecenia w trybie konfiguracji globalnej.
R1(config)# boot system flash0:isr4200-universalk9_ias.16.09.04.SPA.bin
Po tej czynności nie pozostaje nam nic innego jak zapisać konfigurację i uruchomić nasze urządzenie ponownie.
Zadanie praktyczne - Packet Tracer
Użyj serwera TFTP do aktualizacji obrazu Cisco IOS - scenariusz
Użyj serwera TFTP do aktualizacji obrazu Cisco IOS - zadanie
3.10. Podsumowanie
W tym rozdziale zapoznaliśmy się z protokołami CDP, LLDP oraz protokołem synchronizacji czasu NTP. Następnie omówilśmy sobie w jaki sposób może być przydatny protokół SMNP oraz jak czytać komunikaty diagnostyczne zwracane na przez urządzenia. Na koniec dowiedzieliśmy się w jaki sposób tworzyć kopie bezpieczeństwa konfiguracji urządzeń oraz wykorzystać serwer TFTP do aktualizacji Cisco IOS.
3.11. Projektowanie sieci
Obecnie swiat cyfrowy ulega znacznym przemianom. Wiele firm dzięki dostępności Internetu oraz sieci firmowej nie musi już być ograniczona do pojedynczych biur, nawet pracownicy mogą zamieć biura na kąt w domowy zaciszu pracując zdalnie lub nawet pracować z dowolnego miejsca na świecie. To powoduje, że nie tylko branża IT ale także wszystkie inne gałęzie gospodarki państw stają się uzależnione od infrastruktury sieciowej. Dzięki niej firma może się rozwijać. Zmiany te mają znaczący wpływ na wymagania sieci, która musi skalowalna.
Sieć musi być opracowywana w architektonicznym podejściu, które posiada wbudowaną inteligencję, upraszcza operacje oraz jest skalowalna pod przyszłe wymagania. Takie sieci są nazwywane nieograniczonymi sieciam przełączanymi.
Budowa takie sieci oparta jest o następujące zasady:
Projektowanie nieograniczonej sieci przełączanej w sposób hierarhiczny tworzy podstawę, która zezwala projektantom sieci na pokrycie bezpieczeństwa, mobilności oraz jednolitych właściwości komunikacyjnych. Dwie sprawdzone w czasie i sprawdzone hierarhiczne struktury projektowe dla sieci kampusowych to modele trójwarstwowe oraz dwuwarstwowe.
Model trójwarstwowy posiada warstwę dostępu, dystrybucji oraz rdzenia. Każda z tych warstw jest dobrze zdefiniowany strukturalnym modułem pełniącym określone role i funkcje w sieci. Model dwuwarstwowy, spłyca warstwę dystrybucji oraz rdzenia do jednej wspólnej warstwy. Takie rozwiązanie może zostać zastosowane w mniejszych sieciach kampusowych.
3.11.1. Sieci skalowalne
Aby obsługiwać dużą czy mała sieć, projektant musi opracować strategię umożliwijającą dostęp do sieci oraz efektywne i łatwe skalowanie. Skalowalność to termin, dla sieci która może się rozwiajać bez utraty dostępności i niezawodności. Poniżej znajdują się podstawowe zalecenia odnośnie projektowania sieci:
W sieciach skalowanych, ważne jest zapewnienie redundancji, metodą jej implementacji może być trasy nadmiarowe - dodatkowe fizczne połączenia między urządzeniami służace do transmisji danych przez sieć. Zapewniają one wysoką dostępność w sieciach przełączanych. Jednakże, ze względu na zasadę działania przełączników, trasy nadmiarowe w sieci przełączanych mogą powodować pętle na poziomie warstwy 2. W takie sytuacji wymagane jest zastosowanie protokołu STP. Korzystanie z warstwy 3 w szkielecie to inny sposób na nadmiarowość bez konieczności stosowania STP w warstwie 2. Warstwa 3 zapewnia również nalepszy wybór ścieżek i szybszą konwergencję podczas pracy awaryjnej.
W dobrze zaprojektowanej sieci nie tylko występuje odpowiednia kontrola ruchu, orgraniczony jest także rozmiar domeny awarii. Domena awarii to obszar, w którym sieć jest narażona jest na uszkodzenie w sytuacji gdy występują problemy z urządzeniem lub usługą sieciową. Zakres domeny awarii wyznaczony jest przez funkcję, jaką spełnia urządzenie, które początkowo uległo awarii. Przykładowo, nieprawidłowe działanie przełącznika w segmencie sieci, w normalnej sytuacji wpływa tylko na hosty w tym segmencie. Jednakże, w momencie gdy awarii ulegnie router, lączący ten segment z innymi, jej zakres będzie znacznie większy. W celu zminimalizowani ryzyka awarii, powinno się stosować bardziej niezawodne urządzenia klasy enterprise oraz łącza nadmiarowe.
W sieci hierarhicznej konieczne może być zwiększę przepustowości na niektórych łączach. W tym celu możemy wykorzystać EtherChannel oraz ogólne technologii agregacji łączy, wykorzystując do tego porty przełącznika. Z punktu widzenia urzadzenia kanał widoczny jest jako jedno łącze. EtherChannel jest także sposobem na lepsze wykorzystanie łączy nadmiarowych, wyłączonych przez STP.
Sieć musi zostać zaprojetowana tak, aby można było ją rozszerzyć w zależności od indywidualnych potrzeb oraz dostępnych urządzeń. Do komunikacji bezprzewodowej, urządzenia końcowe wymagają bezprzewodowej karty sieciowej, natomiast aby hosty bezprzewodowe mogły korzystać z zasobów sieci kablowej potrzebny punkt dostępu, umożliwiwający im dostęp do sieci firmowej (kablowej).
W większych sieciach stosowany jest OSPF. Jest to protokół routingu według stanu łącza. Routery OSPF ustanawiają i utrzymują sąsiedztwo z innymi podłączonymi routera OSPF. Routery synchronizują swoją bazę stanu łącza. W przypadku zmiany sieci wysłane są aktualizacje stanu łączą, które informują inne routery OSPF o zmianie i ustanawiają nową najlepszą ścieżkę, jeśli jest dostępna.
3.11.2. Platformy sprzętowe przełączników
Jednym z prostych sposobów tworzenia hierarchicznych i skalowanych sieci jest użycie odpowiedniego sprzętu do pracy. Istnieje wiele platform przełączników i innych funkcji, które należy wziąć pod uwagę przed wyborem przełącznika. Projektując sieć, ważne jest, aby wybrać odpowiedni sprzęt, który spełni aktuane wymagania sieci, a także pozwoli na rozbudowę sieci. Urządzenia takie jak przełączniki i routery spełniają w korporacjach kluczową role w procesie komunikacji sieciowej.
Administratorzy sieci muszą określić czynniki, na podstawie których będą decydować o wyborze przełącznika. Obejmuje to stałą konfigurację, konfigurację modułową, możliwość układania w stos lub ich brak.
Parametr gęstości portów przełącznika określa ilość dostępnych portów przypadającą na jeden przełącznik. Przełącznik o stałej konfiguracji obsługują różne konfiguracje gęstości portów. Przełączniki 48 portowe mogą być dodatkowo wyposażane o dodatkowe porty.
Szybkość przekazywania jest miarą ilości danych, które przełączniki może przetworzyć w ciągu sekundy. Serie przełączników są klasyfikowane na podstawie ich szybkości przekazywania. Przełączniki niższej klasy mają na ogół mniejszą przepustowość niż przełączniki klasy enterprise Szybkość przekazywanie jest istotnym parametrem, który można uwzględnić, dobierając przełącznik. Na przykład typowy 48-portowy przełącznik gigabitowy działający z pełną prędkością okablowania generuje ruch 48Gb/s. Jeśli przełącznik obsługuje tylko szybkość przekazywania 32Gb/s, nie może działać z pełną prędkością na wszystkich portach.
Funkcja zasilanie przez Ethernet (PoE - Power over Ethernet) umożliwia przełącznikowi dostarczenie enegrii elektrycznej do urządzenia przez istniejące okablowanie ethernetowe. Ta funkcja może być używana przez Telefony IP i niektóre bezprzewodowe punkty dostępowe, dzięki czemu można jest zainstalować w dowolnym miejscu, w którym jest kabel Ethernet. Przełączniki tego typu są dość drogie, więc trzeba się upewnić czy na pewno potrzebujemy takiej funkcji.
Przełączniki wielowarstwowe są zwykle wdrażane w warstwie rdzenia i warstwach dystrybucyjnych sieci przełączanej. Ich cechą charakterystyczną jest możliwość tworzenia tablic routingu, obsługa niektórych protokołów routingu oraz przekazywanie pakietów IP z szybkością zbliżoną do przełączania w warstwie 2. Obecnie w sieciach występuje tendencja tworzenia środowisk opartych wyłącznie na urządzeniach warstwy 3. Obecnie prawie wszystkie przełączniki obsługują routing. Prawodopodobnie wkrótce wszystkie przełączniki będą miały wbudowany procesor routingu. Przełączniki Catalyst 2960 ilustrują migrację do czystego środowiska warstwy 3. Przed IOS 15.x, przełączniki obsługiwały tylko jeden interfejs SVI, od momentu wydania IOS 15.x przełączniki obsługują teraz wiele aktywnych interfejsów SVI. Oznacza to, że przełącznik może mieć wiele skonfigurowanych adresów IP w różnych podsieciach i łączyć się zdalnymi sieciami.
3.11.3. Komponenty sprzętowe routera
Wybór routera to kolejna bardzo ważna decyzja. Routery odgrywają kluczową rolę w tworzeniu sieci. Wykorzystują one część sieciową (prefiks) docelowego adresu IP do kierowania pakietów do właściwego miejsca docelowego. W przypadku zerwania łącza wybierają alternatywną ścieżkę. Wszystkie hosty w sieci lokalnej umieszczają swojej konfiguracji adres IP interfejsu lokalnego routera, podłączonego do tej sieci. Interfejs ten pełni funkcję bramy domyślnej. Zdolnośc do wydajnego trasowania i odtwarzania po awarii łącza sieciowego ma kluczowe znaczenie dla dostarczania pakietów do miejsca przeznaczenia.
Istnieją różne kategorie routerów Cisco:
Zadanie praktyczne - Packet Tracer
Porównaj urządzenia warstwy 2 i warstwy 3 - scenariusz
Porównaj urządzenia warstwy 2 i warstwy 3 - zadanie
3.12. Rozwiązywanie problemów z sieciami
Rozwiązywanie problemów na początek rozpoczniemy od zagadanienia utworzenia i prowadzenia dokumentacji.
Aby skutecznie monitorować i rozwiązywać problemy z siecią, wymagana jest dokładna i kompletna dokumentacja sieciowa. Taka dokumentacja powinna zawierać nastepujące elementy:
Dokumentacja sieciowa powinna być przechowywana w formie papierowej w jednym miejscu lub w sieci na chronionym serwerze. Jej kopia zapasowa powinna być zabezpieczona i przechowywana w osobnej lokalizacji.
Topologia fizyczna - przedstawia fizyczny układ urządzeń podłączonych do sieci. Informacje zapisne w topologi fizycznej zazwyczaj obejmują:
Topologia logiczna - ilustruje w jaki sposób urządzenia są ze sobą logicznie połaczone. Odnosi się do sposóbu przsyłania danych przez sieć podczas komunikacji z innymi urządzeniami. Informacje zapisane w logicznej topologii sieći mogą obejmować:
Jeśli nasz sieć działa w podwójnym stosie to możemy również dodać do topologi logicznej adresy IPv6, lub utworzyć dla niej zupełnie oddzielną.
Dokumentacja urządzeń sieciowych powinna zawierać dokładne i aktualne zapisy sprzętu sieciowego. Dokumentacja powinna zawierać wszystkie istotne informacje takie jak nazwa urządzenia, model, opis, lokalizację, wersję oprogramowania oraz datę ostatniej jego aktualizacji. W przypadku routerów ważne jest opisanie każdego z interfejsów, przypisanych mu adresów IP, adresu MAC oraz przeznaczenia, podobnie w przypadku przełączników opis z czym łaczy się dany port, opisy konfiguracji VLAN czy port trunk czy działa w EtherChannel, dla trunk-ów ID natywnego VLAN oraz stan portów - włączony/wyłączony.
Celem procesu monitorowania sieci jest obserwacja wydajności i porównanie jej z wyznaczonym punktem odniesienia. Stan odniesienia służy do ustalenia normalnej wydajności sieci lub systemu w celu określenia osobowości sieci w normalnych warunkach. Wyznaczenie stanu odniesienia wymaga zebrania danych o wydajności z poszczególnych portów i urządzeń, niezbędnych do działania sieci. Stan odniesienia powinien odpowiadać na następujące pytania:
Przygotowując punkt odniesienia należy:
Podczas zbierania informacji do dokumentacji, możemy swobodnie
posługiwać się poznanymi dotychczas wariacjami polecenia
show.
3.12.1. Proces rozwiązywania problemów
Istnieje kilka procesów rozwiązywania problemów, dla przykładu możemy użyć trzech prostych logicznych etapów.
Jeśli problem wydaje się rozwiązny, to należy udokumentować rozwiązania i zapisz zmiany. Jeśli nie, lub też tworzony kolejny problem to należy cofnąć działania naprawcze i rozpocząć od początku.
Oczywiście istnieje bardziej szczegółowy 7-etapowy proces rozwiązywania problemów, nie ma on już tak określonej kolejności dziań i dowolnie można skakać między wewnętrznymi krokami. Poniżej znajdują się omawiane kroki:
Krok pierwszy oraz ostatni można uznać za kroki zewnętrzne.
Wiele problemów z siecią jest początkowo zgłaszanych przez użytkownika końcowego. Jednakże dostarczone informacje są często niejasne lub wprowadzają w błąd. Na przykłąd użytkownicy często zgłaszaja problemy takie jak "sieć jest wyłączona", "Nie mogę uzyskać dostępu do mojej poczty", lub "Mój komputer jest wolny". Do komunikacji z użytkownikiem mogą być stosowane następujące zlecenia.
Zbierając objawy z podejrzanego urządzenia sieciowego, możemy użyć takich poleceń jak:
Podczas izolowania problemów, możemy się posłużyć modelem ISO/OSI. Dla przykładu: warstwy od 7-5 - będą dotyczyć urządzenia końcowego, warstwy 4-3 - routera lub przełącznika wielowarstwowego, warstwa 2 - przełącznika standardowego oraz warstwa 1 - interfejsów, przewodów oraz portów.
Istnieje kilka uporządkowanych podejść do rozwiązywania problemów, które można wykorzystać. Każde z nich będzie zależalo od sytuacji.
3.12.2. Narzędzia do rozwiązywania problemów
Na rynku dostępnych jest szereg narzędzi sprzętowych i programowych, wspomagających rozwiązanie problemów. Mogą one być wykorzystywane do zbierania i analizowania symptomów niewłaściwej pracy sieci.
Analizatory protokołów mogą badać zawartość pakietów podczas przepływu przez sieć. Analizator protokołu dekoduje zapisaną ramkę dla każdej warstwy przedstawia informacje o zawartych w niej protokołach w relatywnie protstym formacie. Takim analizatorem może być Wireshark.
Do rozwiązywania problemów z siecią możemy wykorzystać narzędzia sprzętowe. Takie jak:
Implementacja usług rejestrowania jest ważnym elementem związanym z bezpieczeństwem sieci i rozwiązywaniem problemów. Urządzenia Cisco mogą rejestrować informacje dotyczące zmian w konfiguracji, naruszeń ACL, stanu interfejsów i wielu innych rodzajów zdarzeń. Mogą też wysyłać logi do kilku różnych obiektów, takich jak:
3.12.3. Objawy i przyczyny problemów z siecią
Problemy występujące w sieci często są związane z wydajnością. Oznacza to że istnieje różnica między wydajnością oczekiwana a obserwowaną i czy system nie funkcjonuje tak, jak powinien. Działanie wyższych warstwa modelu żależy od funkcjonowania warstwy fizycznej, administrator musi umieć w sposób efektywny wyizolować i wyeliminować w problemy w warstwie fizycznej. Poniżej znajdują się symptomy oraz przyczyny problemów w tej warstwie.
Symptomy:
Przyczyny:
Problemy powstające w warstwie drugiej objawiają się w specyficzny sposób i jeśli zostaną odpowiedniu szybko rozpoznane, ich identyfikacja może nastąpić dość szybko. Poniżej znajdują symptomy oraz przyczny problemów z warstwą łącza.
Symptomy:
Przyczyny:
Problemy warstwy sieciowej obejmują każdy problem, który obejmuje protokół warstwy 3, takie jak IPv4, IPv6, EIGRP, OSPF itp. Poniżej znajdują się objawy oraz przyczny problemów z warstwą sieciową.
Symptomy:
Przyczny:
Problemy sieci mogą w przypadku routerów wynikać z problemów warstwy transportowej, szczególnie na granicy sieci gdzie ruch jest filtrowany i modyfikowany. Zarówno listy kontroli dostępu - ACL, jak i translacja adresów - NAT działają w warstwie sieciowej i mogą obejmować operacje warstwy transportowej. Symptomy:
Przyczyny:
Do najczęstsze problem z listami ACL, na jakie możemy natrafić to:
Istnieje kilka problemów z NAT, takich jak brak integracji z usługami, takimi jak DHCP i tunelowanie. Mogą to być błędnie skonfigurowany NAT wewnątrz, NAT na zewnątrz lub listy ACL. Pozostałe problemy dotyczną interoperacyjności z innymi technologiami sieciowymi, szczególnie takimi, które wykorzystują informacje o adresacji hosta w sieci umieszczone w pakiecie.
Problemy w warstwie aplikacji blokują dostarczenie usług do programów obsługujących je. Usterka w warstwie aplikacji może w rezultacie sprawić, że zasoby sieci będą nieosiągalne lub niemożliwe do użycia, podczas gdy pozostałe warstwy funkcjonują prawidłowo. Połączenie z siecią jest prawidłowe, jednak aplikacje nie są w stanie ostarczać danych.
3.12.4. Rozwiązywanie problemów z łącznością IP.
Gdy nie ma łączności typu end-to-end, a administrator decyduje się na rozwiązanie problemów z podejściem oddolnym można wykonać następujące czynności:
3.12. Podsumowanie
W tym temacie poruszyliśmy kwestie prowadzenia dokumentacji sieci. Przestawiono wiedzę na temat metod rozwiązywania problemów, narzędzi fizycznych jak i oprogramowania. Poznaliśmy symptomy oraz objawy problemów z poszczególnymi warstwami na koniec dowiedzialiśmy w jaki sposób rozwiązywać problemy w połączeniach end-to-end.
3.13. Wirtualizacja
Przetwarzanie w chmurze obejmuje dużą liczbę komputerów połączonych siecią, które mogą być fizycznie zlokalizowane w dowolnym miejscu. Dostawcy w dużym stopniu polegają na wirtualizacji, aby świadczyć usługi w chmurze. Przetwarzanie w chmurze może obniżyć koszty operacyjne dzięki wydajniejszemu wykorzystaniu zasobów. Rozwiązuje ono różne problemy związane z zarządzaniem danymi:
Usługi w chmurze są dostępne w różnych opcjach, dostosowanych do wymagań klientów. Trzy głóne usługi przetwarzania w chmurze zdefiniowane przez NIST to:
Poniżej przedstawiono 4 modele chmur:
Terminu centrum danych i przetwarznie w chmurze często jest używane nieprawidłowego. Oto poprawne definicje centrum danych oraz przetwarzanie w chmurze.
Centra danych to fizyczne obiekty, które zaspokajają potrzeby obliczeniowe, sieciowe i magazynowe usług przetwarzania w chmurze. Dostawcy usług w chmurze używają centrów danych do hostowania usług i zasobów.
3.13.1. Wirtualizcja
Wirtualizacja oddziela system operacyjny OS od sprzetu. Różni dostawcy oferują usługi w chmurze wirtualnej, które mogą dynamicznie dostraczać serwery zgodnie w wymaganiami.
Wirtualizacja serwerów wykorzystuje nieużywane zasoby i konsoliduje liczbę serwerów. Pozwala to instnienie wielu systemów operacyjnych na jednej platformie sprzętowej.
Stosowanie wirtualizacji zwykle obejmuje redundancję. W razie awarii hiperwizora, maszyna wirtualna (pojedynczy serwer wirtualny, reprezentujący tak jakby fizyczną maszynę), może zostać uruchomiona na innym hiperwizorze. Ponad to można ją uruchomić w taki sposób, aby korzystała z większej ilości zasobów niż tylko pojedynczego hiperwizora.
Hiperwizor to program, który dodaje warstwę abstrakcji na fizycznym sprzęcie. Warstwa ta pozwala na tworzenie maszyn wirtualnych, które mogą miec dostęp do całego sprzetu serwera fizycznego.
Jedną z zalet wirtualizacji jest koszt: wymagana jest mniejsza ilość sprzętu, za co za tym idzie zmniejszone jest także zużycie energii elektrycznej oraz potrzebne mniej miejsca. Dodatkowymi zaletami są łatwiejsze prototypowanie (tworzenie środowisk testowych), szybsze udostępnienia serwerów, większy czas ich działania, lepsze odzyskiwanie po awariach czy wsparcie dla starszych wersji.
Hiperwizor typu 2 to oprogramowanie, które tworzy i uruchamia wystąpienia maszyn wirtualnych. Komputer, na którym hiperwizor obsługuje co najmniej jedną maszynę wirtualną, jest maszyną hosta. Hiperwizory typu 2 są również nazywane hiperwizorami hostowanymi. Dzieje się tak, ponieważ hiperwizor jest instalowany na istniejącym systemie operacyjnym. Typowe hiperwizory typu 2 obejmują:
Większość z nich jest bezpłatnych, lub posiadających płatne rozszerzenia. Ważne jest aby komputer, który ma hostować maszyny miał odpowiednie parametry: wielorzdzeniowy procesor oraz większą ilość pamięci RAM.
3.13.2. Infrastruktruktura sieci wirtualnej
Hiperwizor typu 1 są również nazwane podejściem bare metal, ponieważ hiperwizor jest instalowany bezpośrednio na sprzęcie. Hiperwizory typu 1 są zwykle używane na serwera przedsiebiorstwa i urządzeniach sieciowych w centrach danych. Instancje systemów operacynych są instalowane na hiperwizorze.
Po zainstalowaniu hyperwizora typu 1 i ponownym uruchomieniu serwera wyświetlane są tylko podstawowe informacje, takie jak wersja systemu operacyjnego, ilość pamięci RAM i adres IP. Na tym ekranie nie można utworzyć instancji systemu operacyjnego. Hiperwizor typu 1 wymaga konsoli zarządzania. Oprogramowania zarządzające służy do zarządzania wieloma serwerami przy użyciu tego samego hiperwizora. Konsola zarządzania może automatycznie konsolidować serwery, wyłączać je lub włączać w zależności od potrzeb.
Infrastruktura sieciowa również może skorzystać z wirtualizacji. Funkcje sieciowe można zwirtualizować, każde urządzenie sieciowe można podzielić na wiele urządzeń wirtualnych, które działają jako niezależne urządzenia. Przykłady obejmują podinterfejsy, interfejsy wirtualne, sieci VLAN i tablice routingu. Wirtualny routingu nazywany jest wirtualnym routingiem i przekazywaniem.
3.13.3. Sieć definiowana programowo
SDNy czy sieci definiowane programowo jest model konfigracji sieci, w którym za logikę sieci odpowiedzialny jest centralny sterownik, natomiast samym urządzeniom pozostaje przekazywanie danych ze źródła do miejsca docelowego.
Urządzenia sieciowe zawierają dwie płaszczyzny.
Technologią podobną do SDN jest CEF, ponieważ nie wykorzystuję ona procesora do przekazywania pakietów są one kierowane w oparciu o informacje zapisane w FIB, która jest wstępnie wypełniana na podstawie tablicy rouingu przez płaszczyznę sterowania. CEF jednak nie usuwa z urządzenia warstwy kontrolnej w przeciweństwie do SDN. W przypadku modelu SDN urządzenia będą skupiać się wyłącznie na przekazywaniu danych.
Opracowano dwie główne architektury sieciowe w celu obsługi wirtualizacji sieci:
Składniki SDN mogą obejmować:
W tradycyjnej architekturze routera lub przełącznika funkcje płaszczyzny sterowania i płaszczyzny danych występują w tym samym urządzeniu. Decyzje o routingu i przekierowanie pakietów są odpowiedzialne za system operacyjny urządzenia. W SDN zarządzanie płaszczyzną sterowania jest przeniesione do scentralizowanego kontrolera SDN. Kontroler SDN do jednostka logiczna, która umożliwia administratorom sieci zarządzanie ruchem w sieci i dyktowanie tego w jaki sposób płaszczyzna danych urządzeń ma obsługiwać ruch sieciowy. Organizuje, pośredniczy i ułatwia komunikację między aplikacjami i elementami sieci.
3.13.4. Kontrolery SDN
Wszystkie złożone funkcje wykonywane są przez kontroler. Sterownik wypełnia tablę przepływu, przełącznika zarządzają tablemi przepływu. Kontrole SDN wykorzystuje protokół OpenFlow do komunikacji z przełącznikami kompatybilnymi z tym protokołem, protokół ten jest bezpieczny wykorzystuje TLS. Przełącznika OpenFlow łączą się ze sobą oraz z urządzeniami końcowymi.
Cisco ACI to rozwiązanie sprzętowe do integracji chmury obliczeniowej i zarządzania centrum danych. Na wysokim poziomie element zasad sieci jest usuwany z płaszczyznyc danych. Upraszcza to sposób tworzenia sieci centrów danych.
Są trzy podstawowe elementy architektury ACI:
Sieć szkieletowa Cisco ACI składa się z APIC i przełączników Cisco Nexus 9000 wykorzystując dwupoziomową technologię Spine-Leaf. Przełączniki szkieletowe Leaf, zawsze przyczepiają się do przełączników dostępowych Spine, ale nigdy nie łączą się ze sobą. Podobnie przełączniki dostępowe Spine łączą się tylko do przełączników szkieletowych Leaf oraz do rdzenia. W tej dwuwarstwowej topologii wszystko jest oddzielone jednym przeskokiem od wszystkie innego.
Istnieją trzy typy sieci definiowanych programowo.
3.13. Podsumowanie
Ten rodział poruszył temat wirtualizacji, dowiedzieliśmy się czym są maszyny wirtualne oraz hiperwizory 1 i 2 typu. Dowiedzieliśmy się, że możemy wirtualizować elementy sieciowe. Na koniec zapoznaliśmuy się z pojęciem SDN oraz kontrolerami sieci definiowanej programowo.
3.14. Automatyzacja sieci
Automatyzacja to każdy proces samoczynnie napędzany, który ogranicza i potencjalnie eliminuje potrzebę interwencji człowieka.
3.14.1. Formaty danych
Format danych to sposób przechowywania i wymiany danych w ustrukturyzowanym formacie. Jednym z takich formatów jest HTML.
Formaty danych mają reguły strukturę podobną do tych, które mamy w przypadku języków programowania i języków pisanych. Każdy format danych będzie miał miał specyficzne cechy:
Systemy automatyzacji mogą wykorzystywać następujący typy danych:
3.14.2. Interfejs API
API to oprogramowanie, które umożliwia innym aplikacjom dostęp do jego danych lub usług. Jest to zestaw reguł opisujących, w jaki sposób jedna prosta aplikacja może współdziałać z inną, oraz instrukcje umożliwiające taką interakcje. Użytkownik wysyła żądanie API do serwera z prośbą o podanie określonych informacji i otrzymuje odpowiedź z serwera wraz z żądanymi informacjami.
Możemy wyróżnić trzy rodzaje api, patrząc względem dostępności:
Usługa sieci Web to usługa dostęna w Internecie za pośrednictwem sieci WWW. Istnieją cztery rodzaje interfejsów API dla usług internetowych.
3.14.3. REST
REST to styl achitektury do projektowania aplikacji internetowych. Odnosi się do stylu architektury internetowej, która ma wiele podstawowych cech i reguluje zachowanie klientów i serwerów. Najprościej mówiąc REST API to API, które działa w oparciu o protokół HTTP. Definiuje zestaw funkcji, którego programiści mogą używać do wykonywania żądań i odbierania odpowiedzi za pośrednictwem protokółu HTTP, takich jak GET i POST. Zgodność z ograniczeniami architektury REST jest ogólnie określana jako RESTful. Interfej API można uznać za RESTful, jeśli ma następujące funkcje: Klient-Serwer, Bezstanowość, Pamięć podręczna.
Zasoby i usługi internetowe, takie jak interfejsy API RESTful, są identyfikowane za pomocą identyfikatora URI. URI to ciąg znaków, który identyfikuje określony zasób sieciowy.
Przeanalizujmy sobie poniższe żądanie API:
http://www.mapquestapi.com/directions/v2/route?outFormat=json&key=KEY&from=Warsaw,PL&to=Berlin,DE
W tym URI występuje: serwer API
(http://www.mapquestapi.com/),
żądany zasób (directions/v2/route),
następnie przechodzimy już do formatu właściwego zapytania. Zapytanie
rozpoczyna się podaniem żądanego formatu danych -
?outFormat=json, następnie podawany
jest klucz (metoda uwierzytelniania, kontroli dostępu do API) -
&key=KEY. Na końcu podajemy
parametry, o które chcemy zapytać -
&from=Warsaw,PL&to=Berlin,DE.
Większość serwisów udostępniających API, udostępnia także dokumentację opisując dostępne zasoby oraz w jakis sposób uzyskać do nich dostęp. Natomiast do tworzenia API możemy wykorzystać takie programy jak Postman lub języki programowania takie jak Python.
3.14.4. Narzędzia do zarządzania konfiguracją
Podsiadając wiele urządzeń do skonfigurowania, możemy konfigurować je po kolei i spędzić nad tym trochę czasu. Poźniej możemy kontrolować nasze urządzenia za pomocą protokołu SNMP. Jednak jeśli przyjdzie nam zmienić jedną opcję na 80 przełącznikach? To znów spędzimy nad tym trochę czasu. Takie kolejne konfigurowanie to tradycyjny sposób konfiguracji i zarządzania nią.
Jedna jeśli nasz sieć jest dość pokaźnych rozmiarów lub lubimy wyzwania możemy wykorzystać informacje zawarte w tym rozdziale i przygotować jedno z narzędzi automatyzacji. Na codzień takie narzędzia używane są np. do przygotowania środowiska do uruchomienia bądź rozwijania różnego rodzaju aplikacji. Do wyboru mamy:
Wykorzystują one żądania RESTful API do automatyzacji zadań i mogą być skalowalne na tysiące urządzeń.
3.14. Podsumowanie
W tym rodziale poruszylimy kwestie automatyzacji oraz jej składników takich jak choćby interfejsy API. Dowiedzieliśmy się również w jaki sposób automatycznie skonfigurować wiele urządzeń. Ten temat kończy 3 moduł oraz cały kurs CCNA. Poniżej znajdują się opisy zadań przygotowawczych oraz opis samego egzaminu praktycznego.
P.S. Jeśli ktoś na podstawie tego materiału uważa, że zda egzamin certyfikacyjny. To jak go zda do niech się do mnie odezwie.
Opisy egzaminów próbnych oraz egzaminu koncowego, są takie same - w przypadku częsci pisemnej (testów), jak we wcześniejszych modułach więc ich opis jest daremny.
3. Przygotowanie do egzaminu praktycznego (PTSA) - ENSA
Przygotowanie do egzaminu praktycznego z modułu 3, obejmowało takie
zagadnienia jak: OSPF w konfiguracji przez interfejs, OSPF w
konfiguracji przez polecenie network.
Ustawienie identyfikatorów dla routerów w OSPF, ustawienie priorytetu
routera na interfejsie dla OSPF. Ustawienie statycznej bramy domyślnej
i rozpropagowanie jej za pomocą OSPF, ustawienie na jednym z łączy
jednego odrębnych odstępów czasu: dla wysłania pakietów hello
oraz oczekiwania na nie (dead interval), ustawienie wartości
referencyjnej dla obliczania kosztów ścieżek, ustawienie stałego kosztu
dla jedenej z scieżek oraz wyłącznie rozgłaszania pakietów hello
gdzie to jest zbędne. W drugiej częsci mamy do skonfigurowania NAT
statyczny dla jednego hosta 1:1 oraz PAT do puli adresów. W części
trzej konfigurujemy ACL-ki: pierwsza ma zezwalać na dostęp zdalny dla
jednej z sieci, druga chronić jedną sieć przed dostępem drugiej sieci.
Natomiast zadaniem ostatniej jest zabronienie jednej z sieci na dostęp
do serwera WWW w innej sieci, ale pozostawienie innego ruchu. Część
czwarta ostatnia, chce aby ustawić na jednym routerów serwer NTP
(serwer w sieci tego routera) oraz skopiowanie obrazu IOS na serwer
przy użyciu TFTP.
3. Egzamin praktyczy - ENSA
Topologia logiczna zadania składa się z trzech routerów, dwóch
przełączników, dwóch PC oraz dwóch serwerów. Do zadań konfiguracyjnych
należy: zaadresowanie wszystkich interfejsów routerów oraz uruchomienie
łączy. Serwerom należy statycznie przypisać adresy. Na routerze
podłączonym do sieci z PC-ami, należy skonfigurować DHCP dzierżawiące
adresy od .100 do .200, dostarczyć adres bramy, adres serwera DNS
(jeden z serwerów) oraz odpowiednią nazwę domeny. Na tym urządzeniu
należy skonfigurować NAT dla wszystkich hostów. Na wszystkich routerach
należy skonfigurować OSPF, wykorzystując do numer procesu 1, sieci
powinny być skonfigurowane za pomocą słowa kluczowego
network, na jednym z routerów jest
powinien być interfejs loopback, emulujący łącze do sieci
publicznej. Należy skonfigurować je jako bramę domyślną tego urządzenia
i udostępnić tę trasę przez OSPF. Ostatnim zadaniem jest
skonfigurowanie ACL, które pozwolą PC-om na dostęp do usługi WWW (80)
serwera WWW oraz usługi FTP (20/21) serwera FTP.